 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Crowd Counting via Dynamic Temporal Modeling
Paper and Code
Jul 04, 2019

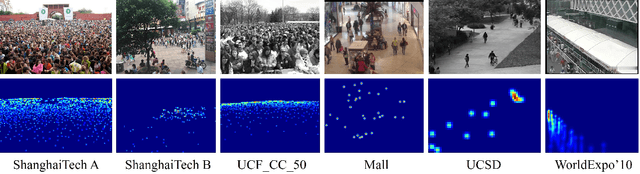
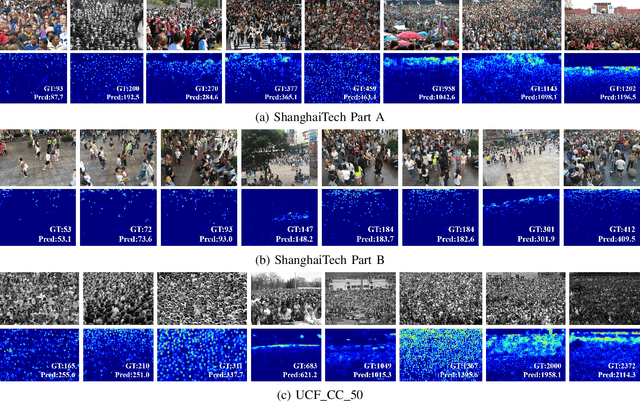
Crowd counting aims to count the number of instantaneous people in a crowded space, which plays an increasingly important role in the field of public safety. More and more researchers have already proposed many promising solutions to the crowd counting task on the image. With the continuous extension of the application of crowd counting, how to apply the technique to video content has become an urgent problem. At present, although researchers have collected and labeled some video clips, less attention has been drawn to the spatiotemporal characteristics of videos. In order to solve this problem, this paper proposes a novel framework based on dynamic temporal modeling of the relationship between video frames. We model the relationship between adjacent features by constructing a set of dilated residual blocks for crowd counting task, with each phase having an expanded set of time convolutions to generate an initial prediction which is then improved by the next prediction. We extract features from the density map as we find the adjacent density maps share more similar information than original video frames. We also propose a smaller basic network structure to balance the computational cost with a good feature representation. We conduct experiments using the proposed framework on five crowd counting datasets and demonstrate its superiority in terms of effectiveness and efficiency over previous approaches.