 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3AM: An Ambiguity-Aware Multi-Modal Machine Translation Dataset
Paper and Code
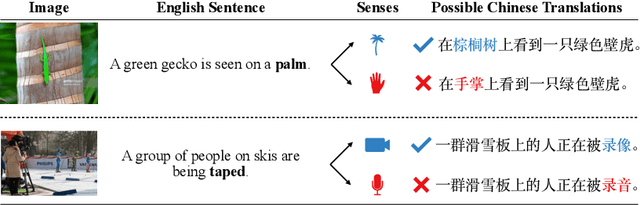
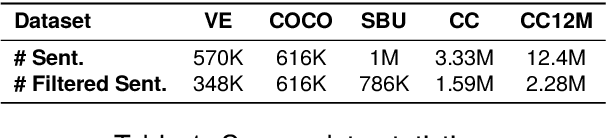
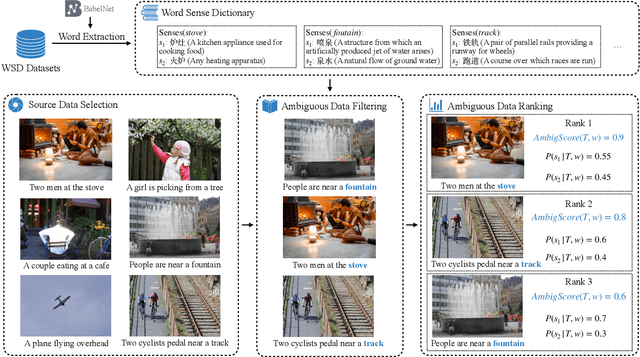

Multimodal machine translation (MMT) is a challenging task that seeks to improve translation quality by incorporating visual information. However, recent studies have indicated that the visual information provided by existing MMT datasets is insufficient, causing models to disregard it and overestimate their capabilities. This issue presents a significant obstacle to the development of MMT research. This paper presents a novel solution to this issue by introducing 3AM, an ambiguity-aware MMT dataset comprising 26,000 parallel sentence pairs in English and Chinese, each with corresponding images. Our dataset is specifically designed to include more ambiguity and a greater variety of both captions and images than other MMT datasets. We utilize a word sense disambiguation model to select ambiguous data from vision-and-language datasets, resulting in a more challenging dataset. We further benchmark several state-of-the-art MMT models on our proposed dataset. Experimental results show that MMT models trained on our dataset exhibit a greater ability to exploit visual information than those trained on other MMT datasets. Our work provides a valuable resource for researchers in the field of multimodal learning and encourages further exploration in this area. The data, code and scripts are freely available at https://github.com/MaxyLee/3AM.