Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoBLEURT Submission for the WMT2021 Metrics Task
Paper and Code
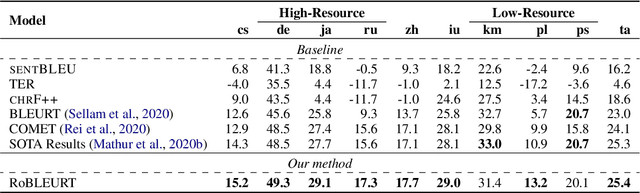

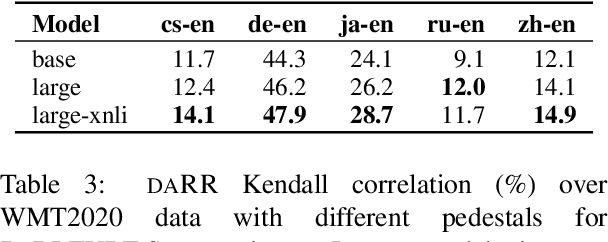
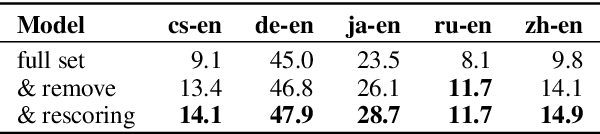
In this paper, we present our submission to Shared Metrics Task: RoBLEURT (Robustly Optimizing the training of BLEURT). After investigating the recent advances of trainable metrics, we conclude several aspects of vital importance to obtain a well-performed metric model by: 1) jointly leveraging the advantages of source-included model and reference-only model, 2) continuously pre-training the model with massive synthetic data pairs, and 3) fine-tuning the model with data denoising strategy. Experimental results show that our model reaching state-of-the-art correlations with the WMT2020 human annotations upon 8 out of 10 to-English language pairs.
* WMT2021 Metrics Shared Task
View paper on