 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
Can Multimodal LLMs do Visual Temporal Understanding and Reasoning? The answer is No!
Jan 18, 2025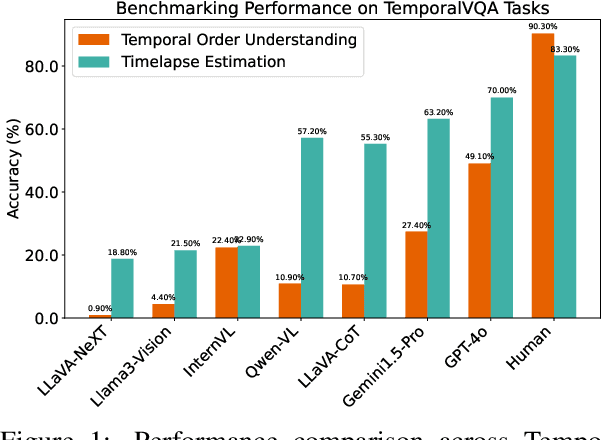



Multimodal Large Language Models (MLLMs) have achieved significant advancements in tasks like Visual Question Answering (VQA) by leveraging foundational Large Language Models (LLMs). However, their abilities in specific areas such as temporal understanding, which is crucial for comprehending real-world dynamics, remain underexplored. To address this, we propose a challenging evaluation benchmark named TemporalVQA, consisting of two parts: (1) Temporal Order Understanding and (2) Time-lapse Estimation. The first part requires MLLMs to determine the sequence of events by analyzing temporally consecutive video frames. The second part presents image pairs with varying time differences, framed as multiple-choice questions, asking MLLMs to estimate the time-lapse between images with options ranging from seconds to years. Our evaluations of advanced MLLMs, including models like GPT-4o and Gemini-1.5-Pro, reveal significant challenges: GPT-4o achieved only 43.8% average consistent accuracy in temporal order tasks and 70% in time-lapse estimation, with open-source models performing even less effectively. These findings underscore the limitations of current MLLMs in visual temporal understanding and reasoning, highlighting the need for further improvements in their temporal capabilities. Our dataset can be found at https://huggingface.co/datasets/fazliimam/temporal-vqa.
CLIP meets DINO for Tuning Zero-Shot Classifier using Unlabeled Image Collections
Nov 28, 2024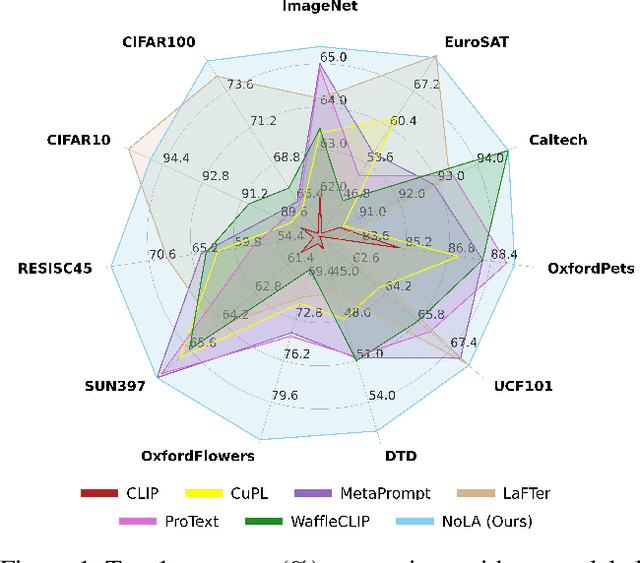
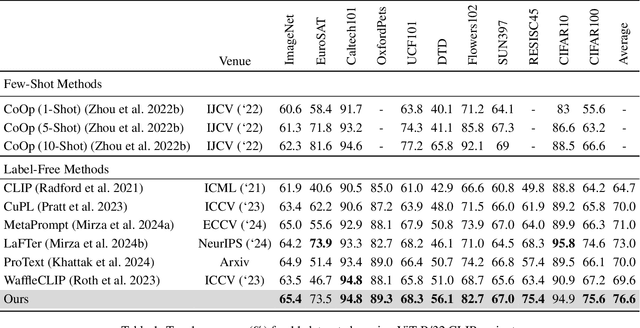
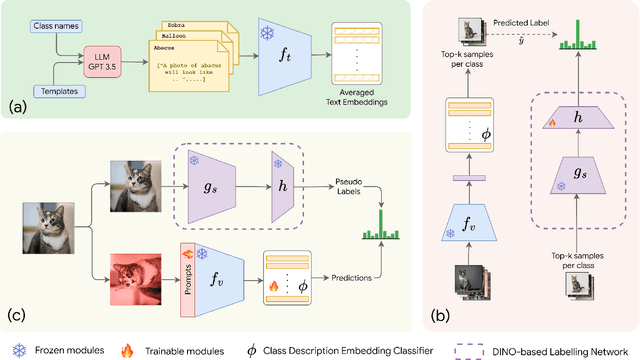
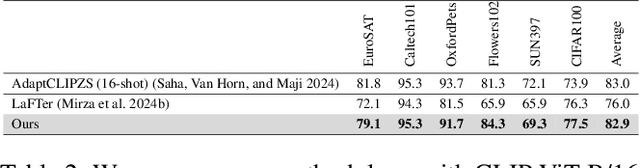
In the era of foundation models, CLIP has emerged as a powerful tool for aligning text and visual modalities into a common embedding space. However, the alignment objective used to train CLIP often results in subpar visual features for fine-grained tasks. In contrast, SSL-pretrained models like DINO excel at extracting rich visual features due to their specialized training paradigm. Yet, these SSL models require an additional supervised linear probing step, which relies on fully labeled data which is often expensive and difficult to obtain at scale. In this paper, we propose a label-free prompt-tuning method that leverages the rich visual features of self-supervised learning models (DINO) and the broad textual knowledge of large language models (LLMs) to largely enhance CLIP-based image classification performance using unlabeled images. Our approach unfolds in three key steps: (1) We generate robust textual feature embeddings that more accurately represent object classes by leveraging class-specific descriptions from LLMs, enabling more effective zero-shot classification compared to CLIP's default name-specific prompts. (2) These textual embeddings are then used to produce pseudo-labels to train an alignment module that integrates the complementary strengths of LLM description-based textual embeddings and DINO's visual features. (3) Finally, we prompt-tune CLIP's vision encoder through DINO-assisted supervision using the trained alignment module. This three-step process allows us to harness the best of visual and textual foundation models, resulting in a powerful and efficient approach that surpasses state-of-the-art label-free classification methods. Notably, our framework, NoLA (No Labels Attached), achieves an average absolute gain of 3.6% over the state-of-the-art LaFter across 11 diverse image classification datasets.