 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Criteria for Instance-based Explanation
Paper and Code


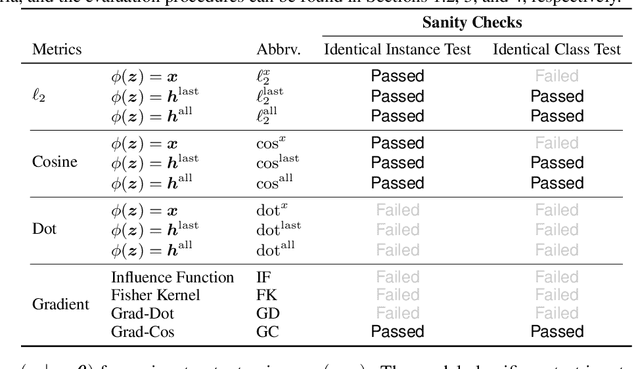

Explaining predictions made by complex machine learning models helps users understand and accept the predicted outputs with confidence. Instance-based explanation provides such help by identifying relevant instances as evidence to support a model's prediction result. To find relevant instances, several relevance metrics have been proposed. In this study, we ask the following research question: "Do the metrics actually work in practice?" To address this question, we propose two sanity check criteria that valid metrics should pass, and two additional criteria to evaluate the practical utility of the metrics. All criteria are designed in terms of whether the metric can pick up instances of desirable properties that the users expect in practice. Through experiments, we obtained two insights. First, some popular relevance metrics do not pass sanity check criteria. Second, some metrics based on cosine similarity perform better than other metrics, which would be recommended choices in practice. We also analyze why some metrics are successful and why some are not. We expect our insights to help further researches such as developing better explanation methods or designing new evaluation criteria.