 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction-Following Evaluation of Large Vision-Language Models
Dec 29, 2025Following the initial flourishing of large language models (LLMs), there has been a surge in proposed large vision-language models (LVLMs) that integrate LLMs with vision capabilities. However, it has been observed that LVLMs, after tuning to visual instruction using commonly used training datasets, often fail to exhibit the instruction-following ability that was present in the LLM before integration, leading to results in which they do not follow task instructions as expected. This study quantitatively demonstrates that LVLMs' instruction-following ability declines after fine-tuning and analyzes its underlying causes. In particular, we constructed new training datasets highlighting whether the output format is specified. Then, we investigated how explicitly indicating the output format during fine-tuning affects LVLMs' instruction-following ability. Our quantitative evaluation confirmed that LVLMs' instruction-following ability declines after fine-tuning with commonly used datasets. Furthermore, we found that LVLMs trained with datasets, including instructions on output format, tend to follow instructions more accurately than models that do not. These findings suggest that including samples with instructions on output format during (visual) instruction tuning may help mitigate the decline in instruction-following abilities.
Empirical Analysis of Large Vision-Language Models against Goal Hijacking via Visual Prompt Injection
Aug 07, 2024We explore visual prompt injection (VPI) that maliciously exploits the ability of large vision-language models (LVLMs) to follow instructions drawn onto the input image. We propose a new VPI method, "goal hijacking via visual prompt injection" (GHVPI), that swaps the execution task of LVLMs from an original task to an alternative task designated by an attacker. The quantitative analysis indicates that GPT-4V is vulnerable to the GHVPI and demonstrates a notable attack success rate of 15.8%, which is an unignorable security risk. Our analysis also shows that successful GHVPI requires high character recognition capability and instruction-following ability in LVLMs.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021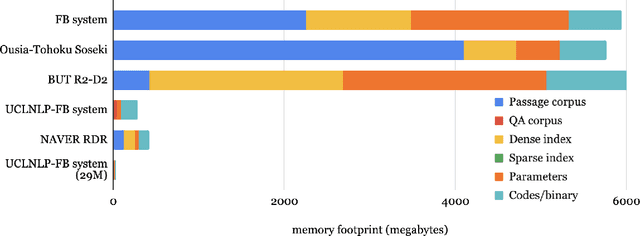
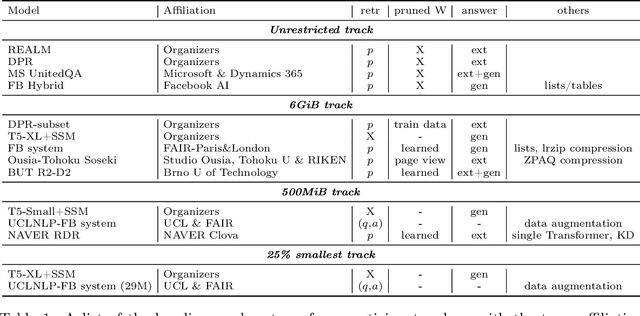
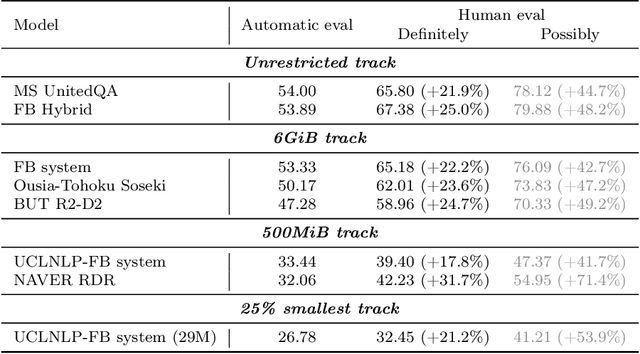
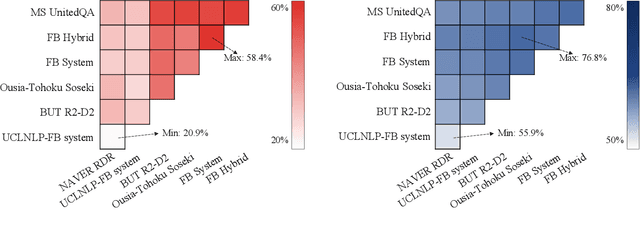
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Embeddings of Label Components for Sequence Labeling: A Case Study of Fine-grained Named Entity Recognition
Jun 04, 2020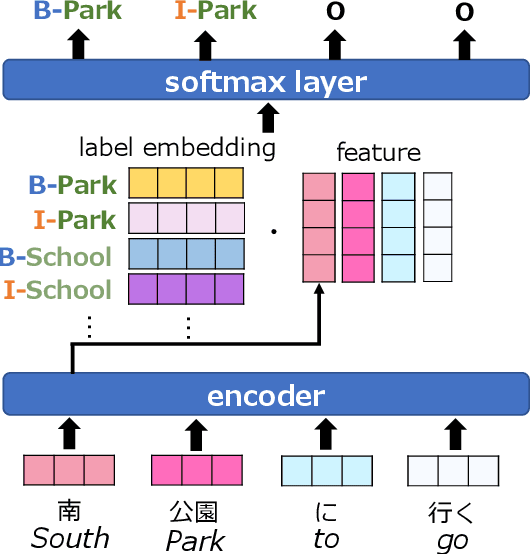
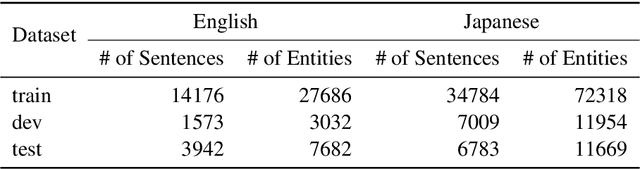
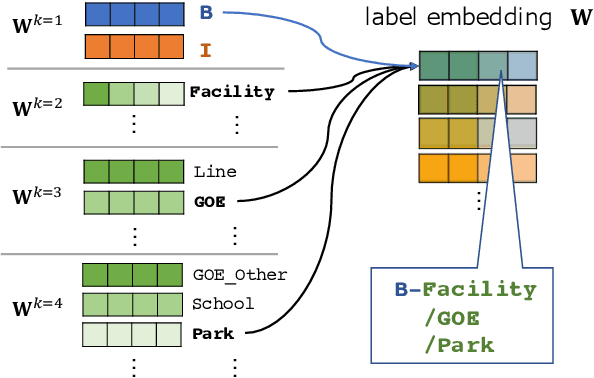
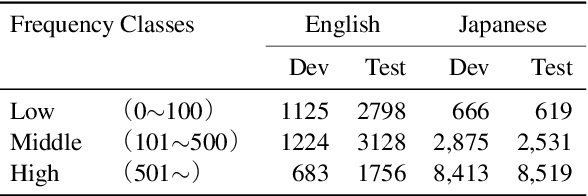
In general, the labels used in sequence labeling consist of different types of elements. For example, IOB-format entity labels, such as B-Person and I-Person, can be decomposed into span (B and I) and type information (Person). However, while most sequence labeling models do not consider such label components, the shared components across labels, such as Person, can be beneficial for label prediction. In this work, we propose to integrate label component information as embeddings into models. Through experiments on English and Japanese fine-grained named entity recognition, we demonstrate that the proposed method improves performance, especially for instances with low-frequency labels.