 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResponses Fall Short of Understanding: Revealing the Gap between Internal Representations and Responses in Visual Document Understanding
Apr 06, 2026Visual document understanding (VDU) is a challenging task for large vision language models (LVLMs), requiring the integration of visual perception, text recognition, and reasoning over structured layouts. Although recent LVLMs have shown progress on VDU benchmarks, their performance is typically evaluated based on generated responses, which may not necessarily reflect whether the model has actually captured the required information internally. In this paper, we investigate how information required to solve VDU tasks is represented across different layers of LLMs within LVLMs using linear probing. Our study reveals that (1) there is a clear gap between internal representations and generated responses, and (2) information required to solve the task is often encoded more linearly from intermediate layers than from the final layer. Motivated by these findings, we explore fine-tuning strategies that target intermediate layers. Experiments show that fine-tuning intermediate layers improves both linear probing accuracy and response accuracy while narrowing the gap.
Nodes Are Early, Edges Are Late: Probing Diagram Representations in Large Vision-Language Models
Mar 03, 2026Large vision-language models (LVLMs) demonstrate strong performance on diagram understanding benchmarks, yet they still struggle with understanding relationships between elements, particularly those represented by nodes and directed edges (e.g., arrows and lines). To investigate the underlying causes of this limitation, we probe the internal representation of LVLMs using a carefully constructed synthetic diagram dataset based on directed graphs. Our probing experiments reveal that edge information is not linearly separable in the vision encoder and becomes linearly encoded only in the text tokens in the language model. In contrast, node information and global structural features are already linearly encoded in individual hidden states of the vision encoder. These findings suggest that the stage at which linearly separable representations are formed varies depending on the type of visual information. In particular, the delayed emergence of edge representations may help explain why LVLMs struggle with relational understanding, such as interpreting edge directions, which require more abstract, compositionally integrated processes.
Instruction-Following Evaluation of Large Vision-Language Models
Dec 29, 2025Following the initial flourishing of large language models (LLMs), there has been a surge in proposed large vision-language models (LVLMs) that integrate LLMs with vision capabilities. However, it has been observed that LVLMs, after tuning to visual instruction using commonly used training datasets, often fail to exhibit the instruction-following ability that was present in the LLM before integration, leading to results in which they do not follow task instructions as expected. This study quantitatively demonstrates that LVLMs' instruction-following ability declines after fine-tuning and analyzes its underlying causes. In particular, we constructed new training datasets highlighting whether the output format is specified. Then, we investigated how explicitly indicating the output format during fine-tuning affects LVLMs' instruction-following ability. Our quantitative evaluation confirmed that LVLMs' instruction-following ability declines after fine-tuning with commonly used datasets. Furthermore, we found that LVLMs trained with datasets, including instructions on output format, tend to follow instructions more accurately than models that do not. These findings suggest that including samples with instructions on output format during (visual) instruction tuning may help mitigate the decline in instruction-following abilities.
VIFSS: View-Invariant and Figure Skating-Specific Pose Representation Learning for Temporal Action Segmentation
Aug 14, 2025Understanding human actions from videos plays a critical role across various domains, including sports analytics. In figure skating, accurately recognizing the type and timing of jumps a skater performs is essential for objective performance evaluation. However, this task typically requires expert-level knowledge due to the fine-grained and complex nature of jump procedures. While recent approaches have attempted to automate this task using Temporal Action Segmentation (TAS), there are two major limitations to TAS for figure skating: the annotated data is insufficient, and existing methods do not account for the inherent three-dimensional aspects and procedural structure of jump actions. In this work, we propose a new TAS framework for figure skating jumps that explicitly incorporates both the three-dimensional nature and the semantic procedure of jump movements. First, we propose a novel View-Invariant, Figure Skating-Specific pose representation learning approach (VIFSS) that combines contrastive learning as pre-training and action classification as fine-tuning. For view-invariant contrastive pre-training, we construct FS-Jump3D, the first publicly available 3D pose dataset specialized for figure skating jumps. Second, we introduce a fine-grained annotation scheme that marks the ``entry (preparation)'' and ``landing'' phases, enabling TAS models to learn the procedural structure of jumps. Extensive experiments demonstrate the effectiveness of our framework. Our method achieves over 92% F1@50 on element-level TAS, which requires recognizing both jump types and rotation levels. Furthermore, we show that view-invariant contrastive pre-training is particularly effective when fine-tuning data is limited, highlighting the practicality of our approach in real-world scenarios.
KASportsFormer: Kinematic Anatomy Enhanced Transformer for 3D Human Pose Estimation on Short Sports Scene Video
Jul 28, 2025Recent transformer based approaches have demonstrated impressive performance in solving real-world 3D human pose estimation problems. Albeit these approaches achieve fruitful results on benchmark datasets, they tend to fall short of sports scenarios where human movements are more complicated than daily life actions, as being hindered by motion blur, occlusions, and domain shifts. Moreover, due to the fact that critical motions in a sports game often finish in moments of time (e.g., shooting), the ability to focus on momentary actions is becoming a crucial factor in sports analysis, where current methods appear to struggle with instantaneous scenarios. To overcome these limitations, we introduce KASportsFormer, a novel transformer based 3D pose estimation framework for sports that incorporates a kinematic anatomy-informed feature representation and integration module. In which the inherent kinematic motion information is extracted with the Bone Extractor (BoneExt) and Limb Fuser (LimbFus) modules and encoded in a multimodal manner. This improved the capability of comprehending sports poses in short videos. We evaluate our method through two representative sports scene datasets: SportsPose and WorldPose. Experimental results show that our proposed method achieves state-of-the-art results with MPJPE errors of 58.0mm and 34.3mm, respectively. Our code and models are available at: https://github.com/jw0r1n/KASportsFormer
VDocRAG: Retrieval-Augmented Generation over Visually-Rich Documents
Apr 14, 2025We aim to develop a retrieval-augmented generation (RAG) framework that answers questions over a corpus of visually-rich documents presented in mixed modalities (e.g., charts, tables) and diverse formats (e.g., PDF, PPTX). In this paper, we introduce a new RAG framework, VDocRAG, which can directly understand varied documents and modalities in a unified image format to prevent missing information that occurs by parsing documents to obtain text. To improve the performance, we propose novel self-supervised pre-training tasks that adapt large vision-language models for retrieval by compressing visual information into dense token representations while aligning them with textual content in documents. Furthermore, we introduce OpenDocVQA, the first unified collection of open-domain document visual question answering datasets, encompassing diverse document types and formats. OpenDocVQA provides a comprehensive resource for training and evaluating retrieval and question answering models on visually-rich documents in an open-domain setting. Experiments show that VDocRAG substantially outperforms conventional text-based RAG and has strong generalization capability, highlighting the potential of an effective RAG paradigm for real-world documents.
AthletePose3D: A Benchmark Dataset for 3D Human Pose Estimation and Kinematic Validation in Athletic Movements
Mar 11, 2025Human pose estimation is a critical task in computer vision and sports biomechanics, with applications spanning sports science, rehabilitation, and biomechanical research. While significant progress has been made in monocular 3D pose estimation, current datasets often fail to capture the complex, high-acceleration movements typical of competitive sports. In this work, we introduce AthletePose3D, a novel dataset designed to address this gap. AthletePose3D includes 12 types of sports motions across various disciplines, with approximately 1.3 million frames and 165 thousand individual postures, specifically capturing high-speed, high-acceleration athletic movements. We evaluate state-of-the-art (SOTA) monocular 2D and 3D pose estimation models on the dataset, revealing that models trained on conventional datasets perform poorly on athletic motions. However, fine-tuning these models on AthletePose3D notably reduces the SOTA model mean per joint position error (MPJPE) from 214mm to 65mm-a reduction of over 69%. We also validate the kinematic accuracy of monocular pose estimations through waveform analysis, highlighting strong correlations in joint angle estimations but limitations in velocity estimation. Our work provides a comprehensive evaluation of monocular pose estimation models in the context of sports, contributing valuable insights for advancing monocular pose estimation techniques in high-performance sports environments. The dataset, code, and model checkpoints are available at: https://github.com/calvinyeungck/AthletePose3D
3D Pose-Based Temporal Action Segmentation for Figure Skating: A Fine-Grained and Jump Procedure-Aware Annotation Approach
Aug 29, 2024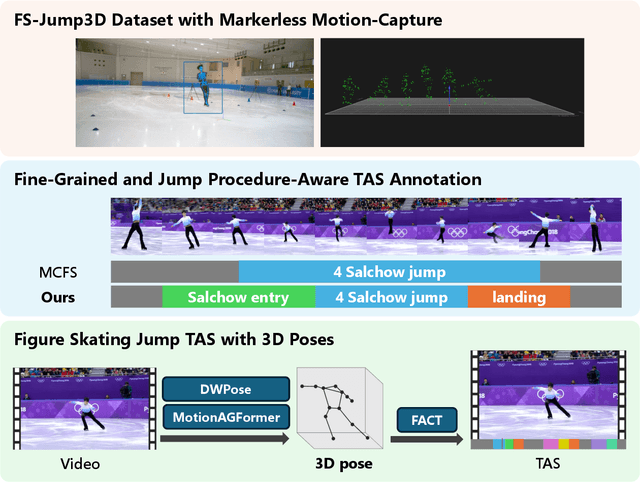
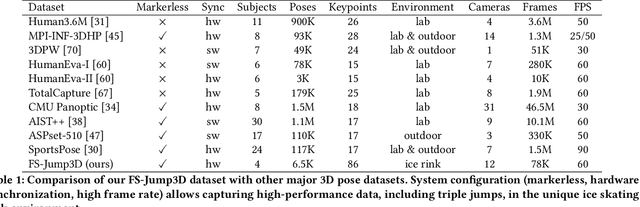
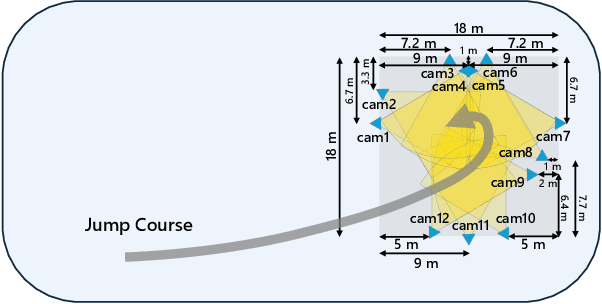

Understanding human actions from videos is essential in many domains, including sports. In figure skating, technical judgments are performed by watching skaters' 3D movements, and its part of the judging procedure can be regarded as a Temporal Action Segmentation (TAS) task. TAS tasks in figure skating that automatically assign temporal semantics to video are actively researched. However, there is a lack of datasets and effective methods for TAS tasks requiring 3D pose data. In this study, we first created the FS-Jump3D dataset of complex and dynamic figure skating jumps using optical markerless motion capture. We also propose a new fine-grained figure skating jump TAS dataset annotation method with which TAS models can learn jump procedures. In the experimental results, we validated the usefulness of 3D pose features as input and the fine-grained dataset for the TAS model in figure skating. FS-Jump3D Dataset is available at https://github.com/ryota-skating/FS-Jump3D.
Empirical Analysis of Large Vision-Language Models against Goal Hijacking via Visual Prompt Injection
Aug 07, 2024We explore visual prompt injection (VPI) that maliciously exploits the ability of large vision-language models (LVLMs) to follow instructions drawn onto the input image. We propose a new VPI method, "goal hijacking via visual prompt injection" (GHVPI), that swaps the execution task of LVLMs from an original task to an alternative task designated by an attacker. The quantitative analysis indicates that GPT-4V is vulnerable to the GHVPI and demonstrates a notable attack success rate of 15.8%, which is an unignorable security risk. Our analysis also shows that successful GHVPI requires high character recognition capability and instruction-following ability in LVLMs.
InstructDoc: A Dataset for Zero-Shot Generalization of Visual Document Understanding with Instructions
Jan 24, 2024We study the problem of completing various visual document understanding (VDU) tasks, e.g., question answering and information extraction, on real-world documents through human-written instructions. To this end, we propose InstructDoc, the first large-scale collection of 30 publicly available VDU datasets, each with diverse instructions in a unified format, which covers a wide range of 12 tasks and includes open document types/formats. Furthermore, to enhance the generalization performance on VDU tasks, we design a new instruction-based document reading and understanding model, InstructDr, that connects document images, image encoders, and large language models (LLMs) through a trainable bridging module. Experiments demonstrate that InstructDr can effectively adapt to new VDU datasets, tasks, and domains via given instructions and outperforms existing multimodal LLMs and ChatGPT without specific training.