 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVDocRAG: Retrieval-Augmented Generation over Visually-Rich Documents
Apr 14, 2025We aim to develop a retrieval-augmented generation (RAG) framework that answers questions over a corpus of visually-rich documents presented in mixed modalities (e.g., charts, tables) and diverse formats (e.g., PDF, PPTX). In this paper, we introduce a new RAG framework, VDocRAG, which can directly understand varied documents and modalities in a unified image format to prevent missing information that occurs by parsing documents to obtain text. To improve the performance, we propose novel self-supervised pre-training tasks that adapt large vision-language models for retrieval by compressing visual information into dense token representations while aligning them with textual content in documents. Furthermore, we introduce OpenDocVQA, the first unified collection of open-domain document visual question answering datasets, encompassing diverse document types and formats. OpenDocVQA provides a comprehensive resource for training and evaluating retrieval and question answering models on visually-rich documents in an open-domain setting. Experiments show that VDocRAG substantially outperforms conventional text-based RAG and has strong generalization capability, highlighting the potential of an effective RAG paradigm for real-world documents.
InstructDoc: A Dataset for Zero-Shot Generalization of Visual Document Understanding with Instructions
Jan 24, 2024We study the problem of completing various visual document understanding (VDU) tasks, e.g., question answering and information extraction, on real-world documents through human-written instructions. To this end, we propose InstructDoc, the first large-scale collection of 30 publicly available VDU datasets, each with diverse instructions in a unified format, which covers a wide range of 12 tasks and includes open document types/formats. Furthermore, to enhance the generalization performance on VDU tasks, we design a new instruction-based document reading and understanding model, InstructDr, that connects document images, image encoders, and large language models (LLMs) through a trainable bridging module. Experiments demonstrate that InstructDr can effectively adapt to new VDU datasets, tasks, and domains via given instructions and outperforms existing multimodal LLMs and ChatGPT without specific training.
Do BERTs Learn to Use Browser User Interface? Exploring Multi-Step Tasks with Unified Vision-and-Language BERTs
Mar 15, 2022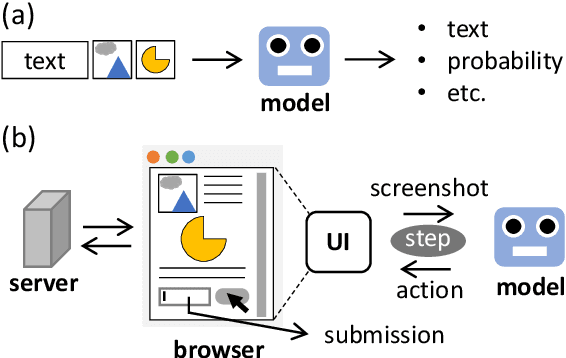



Pre-trained Transformers are good foundations for unified multi-task models owing to their task-agnostic representation. Pre-trained Transformers are often combined with text-to-text framework to execute multiple tasks by a single model. Performing a task through a graphical user interface (GUI) is another candidate to accommodate various tasks, including multi-step tasks with vision and language inputs. However, few papers combine pre-trained Transformers with performing through GUI. To fill this gap, we explore a framework in which a model performs a task by manipulating the GUI implemented with web pages in multiple steps. We develop task pages with and without page transitions and propose a BERT extension for the framework. We jointly trained our BERT extension with those task pages, and made the following observations. (1) The model learned to use both task pages with and without page transition. (2) In four out of five tasks without page transitions, the model performs greater than 75% of the performance of the original BERT, which does not use browsers. (3) The model did not generalize effectively on unseen tasks. These results suggest that we can fine-tune BERTs to multi-step tasks through GUIs, and there is room for improvement in their generalizability. Code will be available online.
Effect of Vision-and-Language Extensions on Natural Language Understanding in Vision-and-Language Models
Apr 16, 2021
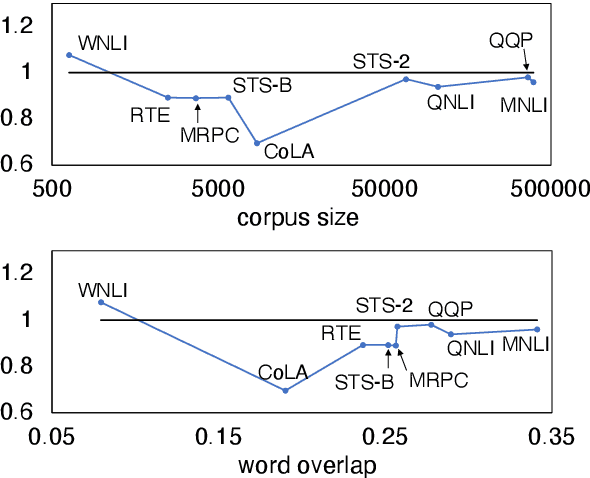
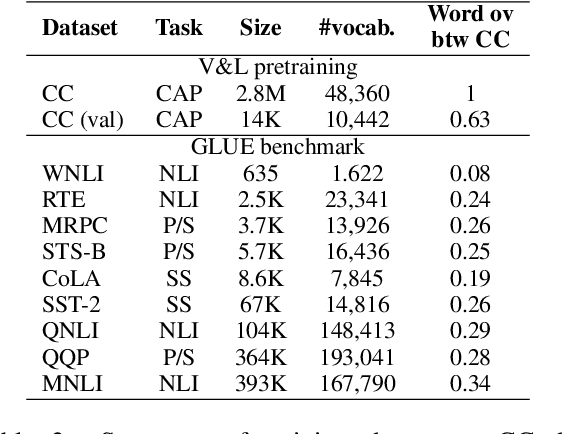
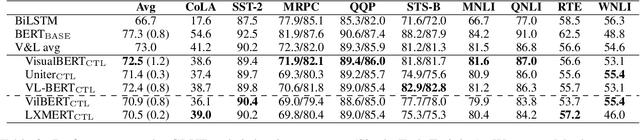
Extending language models with structural modifications and vision-and-language (V&L) pretraining are successful ways of making V&L models that can ground vision and language. Potential applications of these advanced models include multi-modal machine reading comprehension models and multi-modal dialogue models, which require language ability upon grounding. Although language capability is crucial for such applications, the impact of extending their visual capabilities on their language capabilities is not fully understood. This paper investigates how visual extension affects the language capability of V&L models using the GLUE benchmark. We found that visual extension causes some decreases in language capability and that V&L pretraining has a greater impact than structural modifications on the decreases. Our results suggest the need for further study on pretraining that can maintain or, if possible, improve a model's language capability.