 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo BERTs Learn to Use Browser User Interface? Exploring Multi-Step Tasks with Unified Vision-and-Language BERTs
Paper and Code
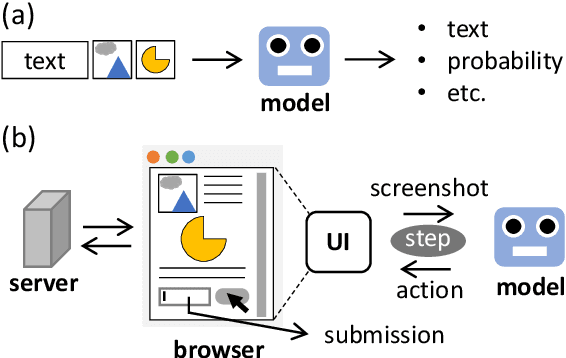



Pre-trained Transformers are good foundations for unified multi-task models owing to their task-agnostic representation. Pre-trained Transformers are often combined with text-to-text framework to execute multiple tasks by a single model. Performing a task through a graphical user interface (GUI) is another candidate to accommodate various tasks, including multi-step tasks with vision and language inputs. However, few papers combine pre-trained Transformers with performing through GUI. To fill this gap, we explore a framework in which a model performs a task by manipulating the GUI implemented with web pages in multiple steps. We develop task pages with and without page transitions and propose a BERT extension for the framework. We jointly trained our BERT extension with those task pages, and made the following observations. (1) The model learned to use both task pages with and without page transition. (2) In four out of five tasks without page transitions, the model performs greater than 75% of the performance of the original BERT, which does not use browsers. (3) The model did not generalize effectively on unseen tasks. These results suggest that we can fine-tune BERTs to multi-step tasks through GUIs, and there is room for improvement in their generalizability. Code will be available online.