 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of Vision-and-Language Extensions on Natural Language Understanding in Vision-and-Language Models
Paper and Code

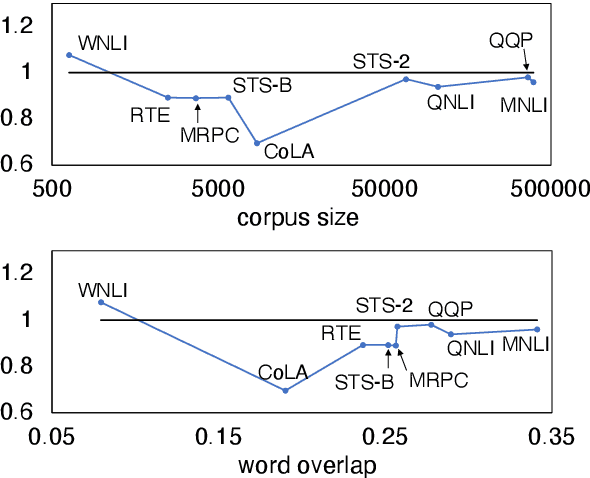
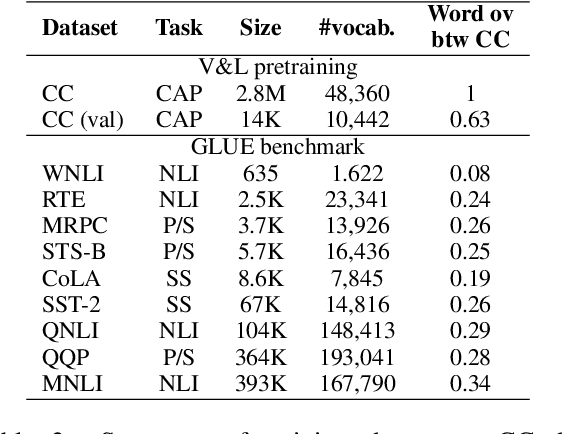
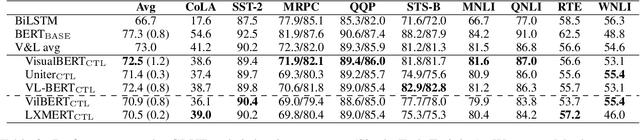
Extending language models with structural modifications and vision-and-language (V&L) pretraining are successful ways of making V&L models that can ground vision and language. Potential applications of these advanced models include multi-modal machine reading comprehension models and multi-modal dialogue models, which require language ability upon grounding. Although language capability is crucial for such applications, the impact of extending their visual capabilities on their language capabilities is not fully understood. This paper investigates how visual extension affects the language capability of V&L models using the GLUE benchmark. We found that visual extension causes some decreases in language capability and that V&L pretraining has a greater impact than structural modifications on the decreases. Our results suggest the need for further study on pretraining that can maintain or, if possible, improve a model's language capability.