 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interpretable and Reliable Reading Comprehension: A Pipeline Model with Unanswerability Prediction
Nov 18, 2021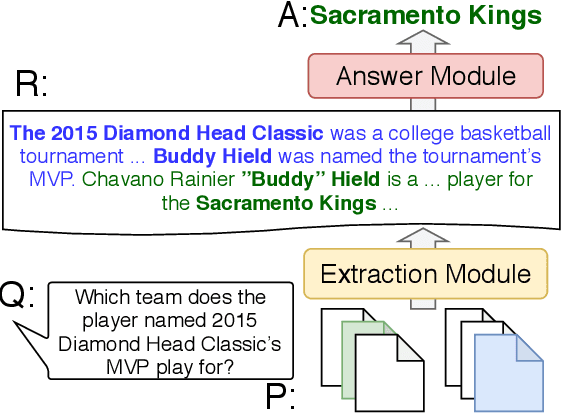
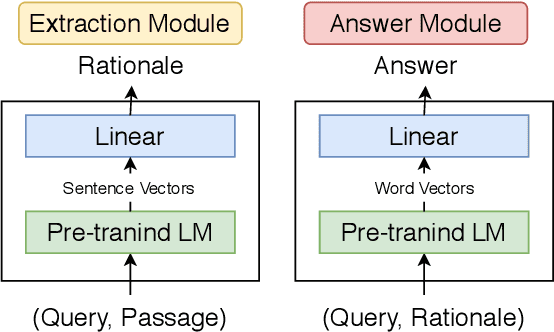

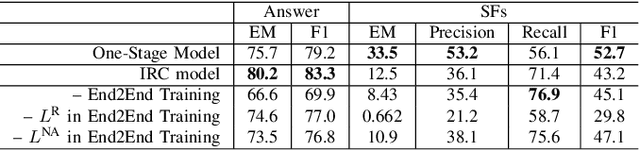
Multi-hop QA with annotated supporting facts, which is the task of reading comprehension (RC) considering the interpretability of the answer, has been extensively studied. In this study, we define an interpretable reading comprehension (IRC) model as a pipeline model with the capability of predicting unanswerable queries. The IRC model justifies the answer prediction by establishing consistency between the predicted supporting facts and the actual rationale for interpretability. The IRC model detects unanswerable questions, instead of outputting the answer forcibly based on the insufficient information, to ensure the reliability of the answer. We also propose an end-to-end training method for the pipeline RC model. To evaluate the interpretability and the reliability, we conducted the experiments considering unanswerability in a multi-hop question for a given passage. We show that our end-to-end trainable pipeline model outperformed a non-interpretable model on our modified HotpotQA dataset. Experimental results also show that the IRC model achieves comparable results to the previous non-interpretable models in spite of the trade-off between prediction performance and interpretability.
* IJCNN 2021 (https://ieeexplore.ieee.org/abstract/document/9534370)
Task-adaptive Pre-training of Language Models with Word Embedding Regularization
Sep 17, 2021
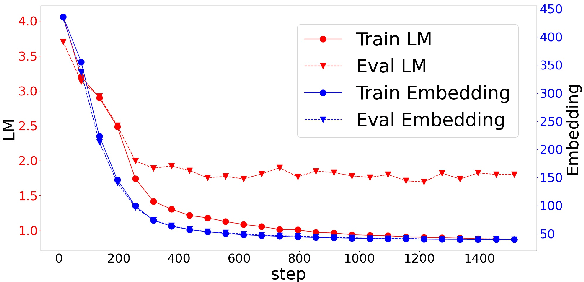

Pre-trained language models (PTLMs) acquire domain-independent linguistic knowledge through pre-training with massive textual resources. Additional pre-training is effective in adapting PTLMs to domains that are not well covered by the pre-training corpora. Here, we focus on the static word embeddings of PTLMs for domain adaptation to teach PTLMs domain-specific meanings of words. We propose a novel fine-tuning process: task-adaptive pre-training with word embedding regularization (TAPTER). TAPTER runs additional pre-training by making the static word embeddings of a PTLM close to the word embeddings obtained in the target domain with fastText. TAPTER requires no additional corpus except for the training data of the downstream task. We confirmed that TAPTER improves the performance of the standard fine-tuning and the task-adaptive pre-training on BioASQ (question answering in the biomedical domain) and on SQuAD (the Wikipedia domain) when their pre-training corpora were not dominated by in-domain data.
VisualMRC: Machine Reading Comprehension on Document Images
Jan 27, 2021
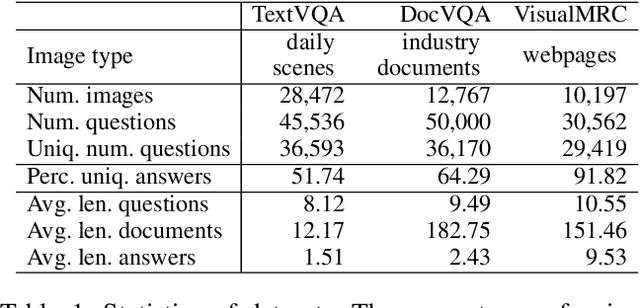
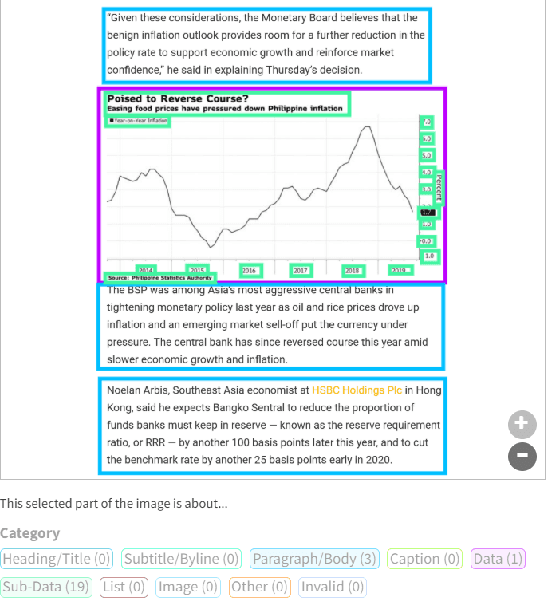

Recent studies on machine reading comprehension have focused on text-level understanding but have not yet reached the level of human understanding of the visual layout and content of real-world documents. In this study, we introduce a new visual machine reading comprehension dataset, named VisualMRC, wherein given a question and a document image, a machine reads and comprehends texts in the image to answer the question in natural language. Compared with existing visual question answering (VQA) datasets that contain texts in images, VisualMRC focuses more on developing natural language understanding and generation abilities. It contains 30,000+ pairs of a question and an abstractive answer for 10,000+ document images sourced from multiple domains of webpages. We also introduce a new model that extends existing sequence-to-sequence models, pre-trained with large-scale text corpora, to take into account the visual layout and content of documents. Experiments with VisualMRC show that this model outperformed the base sequence-to-sequence models and a state-of-the-art VQA model. However, its performance is still below that of humans on most automatic evaluation metrics. The dataset will facilitate research aimed at connecting vision and language understanding.