 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdTEC: A Unified Benchmark for Evaluating Text Quality in Search Engine Advertising
Paper and Code
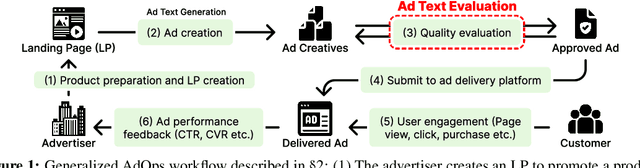


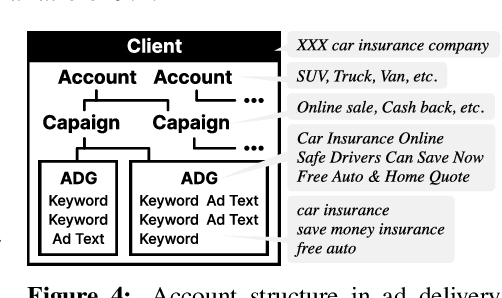
With the increase in the more fluent ad texts automatically created by natural language generation technology, it is in the high demand to verify the quality of these creatives in a real-world setting. We propose AdTEC, the first public benchmark to evaluate ad texts in multiple aspects from the perspective of practical advertising operations. Our contributions are: (i) Defining five tasks for evaluating the quality of ad texts and building a dataset based on the actual operational experience of advertising agencies, which is typically kept in-house. (ii) Validating the performance of existing pre-trained language models (PLMs) and human evaluators on the dataset. (iii) Analyzing the characteristics and providing challenges of the benchmark. The results show that while PLMs have already reached the practical usage level in several tasks, human still outperforms in certain domains, implying that there is significant room for improvement in such area.