 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Conditional Image Embedding Framework Leveraging Large Vision Language Models
Dec 26, 2025Conditional image embeddings are feature representations that focus on specific aspects of an image indicated by a given textual condition (e.g., color, genre), which has been a challenging problem. Although recent vision foundation models, such as CLIP, offer rich representations of images, they are not designed to focus on a specified condition. In this paper, we propose DIOR, a method that leverages a large vision-language model (LVLM) to generate conditional image embeddings. DIOR is a training-free approach that prompts the LVLM to describe an image with a single word related to a given condition. The hidden state vector of the LVLM's last token is then extracted as the conditional image embedding. DIOR provides a versatile solution that can be applied to any image and condition without additional training or task-specific priors. Comprehensive experimental results on conditional image similarity tasks demonstrate that DIOR outperforms existing training-free baselines, including CLIP. Furthermore, DIOR achieves superior performance compared to methods that require additional training across multiple settings.
Do LLMs and Humans Find the Same Questions Difficult? A Case Study on Japanese Quiz Answering
Nov 15, 2025LLMs have achieved performance that surpasses humans in many NLP tasks. However, it remains unclear whether problems that are difficult for humans are also difficult for LLMs. This study investigates how the difficulty of quizzes in a buzzer setting differs between LLMs and humans. Specifically, we first collect Japanese quiz data including questions, answers, and correct response rate of humans, then prompted LLMs to answer the quizzes under several settings, and compare their correct answer rate to that of humans from two analytical perspectives. The experimental results showed that, compared to humans, LLMs struggle more with quizzes whose correct answers are not covered by Wikipedia entries, and also have difficulty with questions that require numerical answers.
Out-of-the-Box Conditional Text Embeddings from Large Language Models
Apr 23, 2025

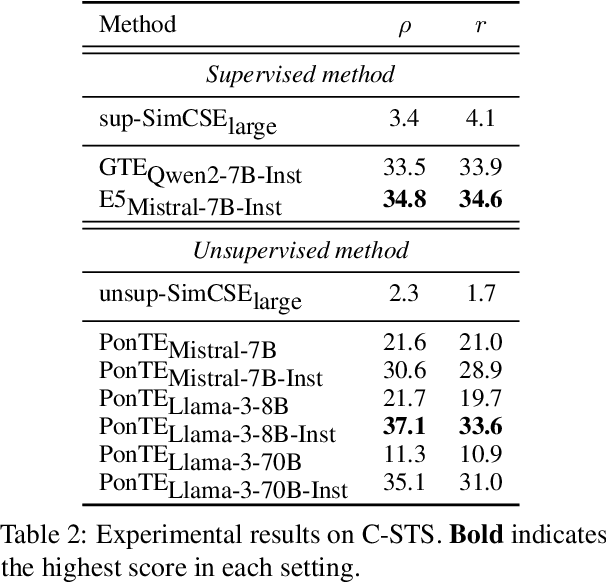

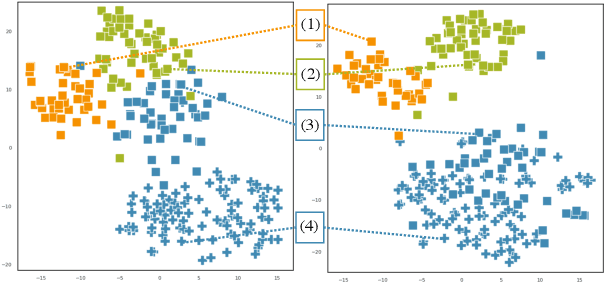
Conditional text embedding is a proposed representation that captures the shift in perspective on texts when conditioned on a specific aspect. Previous methods have relied on extensive training data for fine-tuning models, leading to challenges in terms of labor and resource costs. We propose PonTE, a novel unsupervised conditional text embedding method that leverages a causal large language model and a conditional prompt. Through experiments on conditional semantic text similarity and text clustering, we demonstrate that PonTE can generate useful conditional text embeddings and achieve performance comparable to supervised methods without fine-tuning. We also show the interpretability of text embeddings with PonTE by analyzing word generation following prompts and embedding visualization.
Transformer-based Live Update Generation for Soccer Matches from Microblog Posts
Oct 25, 2023



It has been known to be difficult to generate adequate sports updates from a sequence of vast amounts of diverse live tweets, although the live sports viewing experience with tweets is gaining the popularity. In this paper, we focus on soccer matches and work on building a system to generate live updates for soccer matches from tweets so that users can instantly grasp a match's progress and enjoy the excitement of the match from raw tweets. Our proposed system is based on a large pre-trained language model and incorporates a mechanism to control the number of updates and a mechanism to reduce the redundancy of duplicate and similar updates.
Acquiring Frame Element Knowledge with Deep Metric Learning for Semantic Frame Induction
May 23, 2023



The semantic frame induction tasks are defined as a clustering of words into the frames that they evoke, and a clustering of their arguments according to the frame element roles that they should fill. In this paper, we address the latter task of argument clustering, which aims to acquire frame element knowledge, and propose a method that applies deep metric learning. In this method, a pre-trained language model is fine-tuned to be suitable for distinguishing frame element roles through the use of frame-annotated data, and argument clustering is performed with embeddings obtained from the fine-tuned model. Experimental results on FrameNet demonstrate that our method achieves substantially better performance than existing methods.
Semantic Frame Induction with Deep Metric Learning
Apr 27, 2023Recent studies have demonstrated the usefulness of contextualized word embeddings in unsupervised semantic frame induction. However, they have also revealed that generic contextualized embeddings are not always consistent with human intuitions about semantic frames, which causes unsatisfactory performance for frame induction based on contextualized embeddings. In this paper, we address supervised semantic frame induction, which assumes the existence of frame-annotated data for a subset of predicates in a corpus and aims to build a frame induction model that leverages the annotated data. We propose a model that uses deep metric learning to fine-tune a contextualized embedding model, and we apply the fine-tuned contextualized embeddings to perform semantic frame induction. Our experiments on FrameNet show that fine-tuning with deep metric learning considerably improves the clustering evaluation scores, namely, the B-cubed F-score and Purity F-score, by about 8 points or more. We also demonstrate that our approach is effective even when the number of training instances is small.
Transformer-based Lexically Constrained Headline Generation
Sep 15, 2021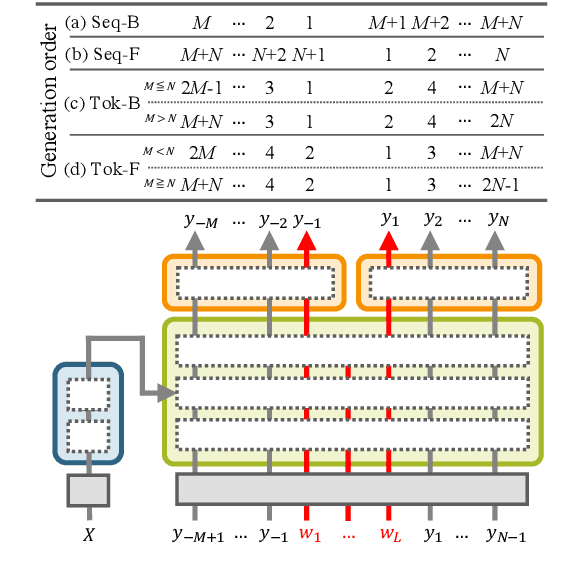

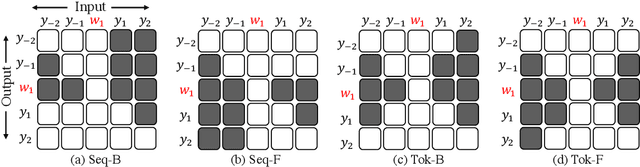

This paper explores a variant of automatic headline generation methods, where a generated headline is required to include a given phrase such as a company or a product name. Previous methods using Transformer-based models generate a headline including a given phrase by providing the encoder with additional information corresponding to the given phrase. However, these methods cannot always include the phrase in the generated headline. Inspired by previous RNN-based methods generating token sequences in backward and forward directions from the given phrase, we propose a simple Transformer-based method that guarantees to include the given phrase in the high-quality generated headline. We also consider a new headline generation strategy that takes advantage of the controllable generation order of Transformer. Our experiments with the Japanese News Corpus demonstrate that our methods, which are guaranteed to include the phrase in the generated headline, achieve ROUGE scores comparable to previous Transformer-based methods. We also show that our generation strategy performs better than previous strategies.
Semantic Frame Induction using Masked Word Embeddings and Two-Step Clustering
May 27, 2021


Recent studies on semantic frame induction show that relatively high performance has been achieved by using clustering-based methods with contextualized word embeddings. However, there are two potential drawbacks to these methods: one is that they focus too much on the superficial information of the frame-evoking verb and the other is that they tend to divide the instances of the same verb into too many different frame clusters. To overcome these drawbacks, we propose a semantic frame induction method using masked word embeddings and two-step clustering. Through experiments on the English FrameNet data, we demonstrate that using the masked word embeddings is effective for avoiding too much reliance on the surface information of frame-evoking verbs and that two-step clustering can improve the number of resulting frame clusters for the instances of the same verb.
Verb Sense Clustering using Contextualized Word Representations for Semantic Frame Induction
May 27, 2021



Contextualized word representations have proven useful for various natural language processing tasks. However, it remains unclear to what extent these representations can cover hand-coded semantic information such as semantic frames, which specify the semantic role of the arguments associated with a predicate. In this paper, we focus on verbs that evoke different frames depending on the context, and we investigate how well contextualized word representations can recognize the difference of frames that the same verb evokes. We also explore which types of representation are suitable for semantic frame induction. In our experiments, we compare seven different contextualized word representations for two English frame-semantic resources, FrameNet and PropBank. We demonstrate that several contextualized word representations, especially BERT and its variants, are considerably informative for semantic frame induction. Furthermore, we examine the extent to which the contextualized representation of a verb can estimate the number of frames that the verb can evoke.