 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuaternion Self-Attention with Shared Scores
May 24, 2026Quaternion neural networks are parameter-efficient and model multidimensional dependencies by representing four related features as a single entity. However, existing quaternion self-attention computes component-wise scores and applies independent softmax operations to each component, which increases the computational cost and allows attention distributions to diverge across components. We propose a shared-score quaternion self-attention mechanism that computes a single real-valued score using the quaternion inner product and applies a shared attention distribution across all components. This reduces score-computation multiplications by 75% and the number of softmax operations from four to one. We prove that, when queries and keys are produced by quaternion linear projections that induce component pre-mixing, the component-wise and shared scores lie in the same interaction subspace, indicating that independent component-wise attention primarily re-parameterizes the same interactions rather than expanding the feature interaction space. In speech enhancement, our method reduces inference time by up to 44.3% on a GPU and 58.1% on a CPU while maintaining quality, with consistent trends across vision and natural language processing.
Transformer-based Lexically Constrained Headline Generation
Sep 15, 2021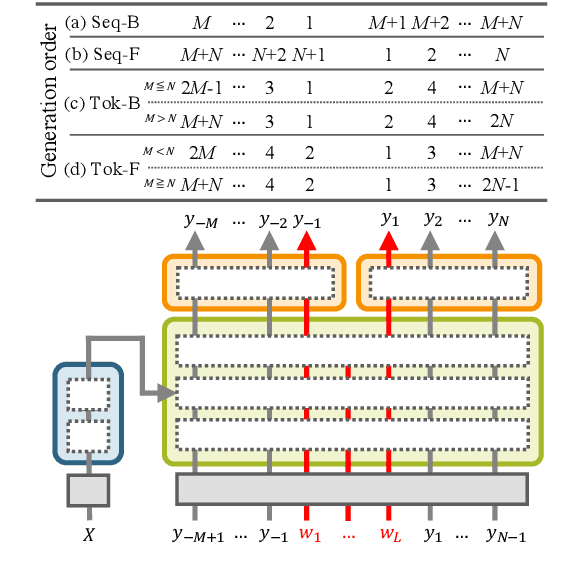

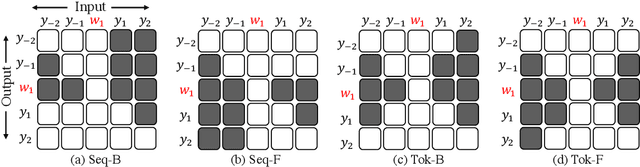

This paper explores a variant of automatic headline generation methods, where a generated headline is required to include a given phrase such as a company or a product name. Previous methods using Transformer-based models generate a headline including a given phrase by providing the encoder with additional information corresponding to the given phrase. However, these methods cannot always include the phrase in the generated headline. Inspired by previous RNN-based methods generating token sequences in backward and forward directions from the given phrase, we propose a simple Transformer-based method that guarantees to include the given phrase in the high-quality generated headline. We also consider a new headline generation strategy that takes advantage of the controllable generation order of Transformer. Our experiments with the Japanese News Corpus demonstrate that our methods, which are guaranteed to include the phrase in the generated headline, achieve ROUGE scores comparable to previous Transformer-based methods. We also show that our generation strategy performs better than previous strategies.
A Large-Scale Multi-Length Headline Corpus for Improving Length-Constrained Headline Generation Model Evaluation
Mar 29, 2019
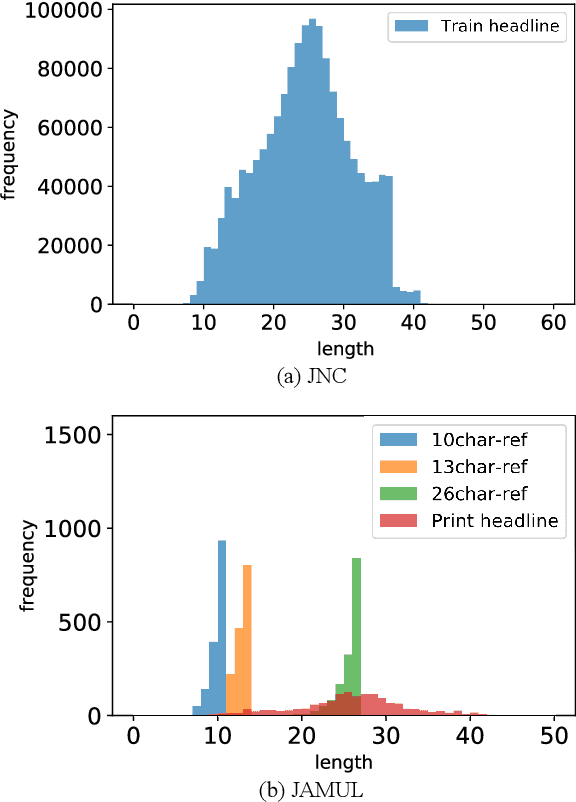

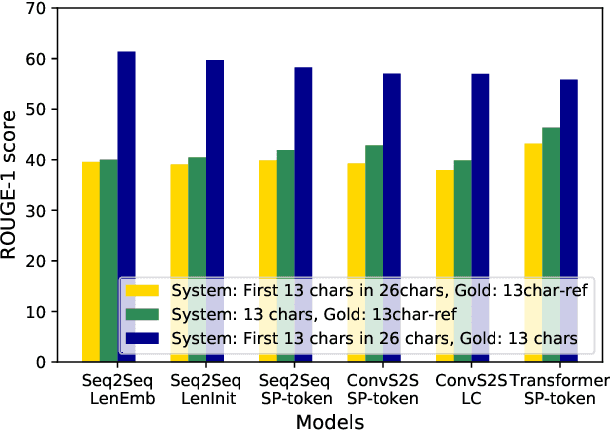
Browsing news articles on multiple devices is now possible. The lengths of news article headlines have precise upper bounds, dictated by the size of the display of the relevant device or interface. Therefore, controlling the length of headlines is essential when applying the task of headline generation to news production. However, because there is no corpus of headlines of multiple lengths for a given article, prior researches on controlling output length in headline generation have not discussed whether the evaluation of the setting that uses a single length reference can evaluate multiple length outputs appropriately. In this paper, we introduce two corpora (JNC and JAMUL) to confirm the validity of prior experimental settings and provide for the next step toward the goal of controlling output length in headline generation. The JNC provides common supervision data for headline generation. The JAMUL is a large-scale evaluation dataset for headlines of three different lengths composed by professional editors. We report new findings on these corpora; for example, while the longest length reference summary can appropriately evaluate the existing methods controlling output length, the methods do not manage the selection of words according to length constraint.