 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
A Large-Scale Multi-Length Headline Corpus for Improving Length-Constrained Headline Generation Model Evaluation
Mar 29, 2019
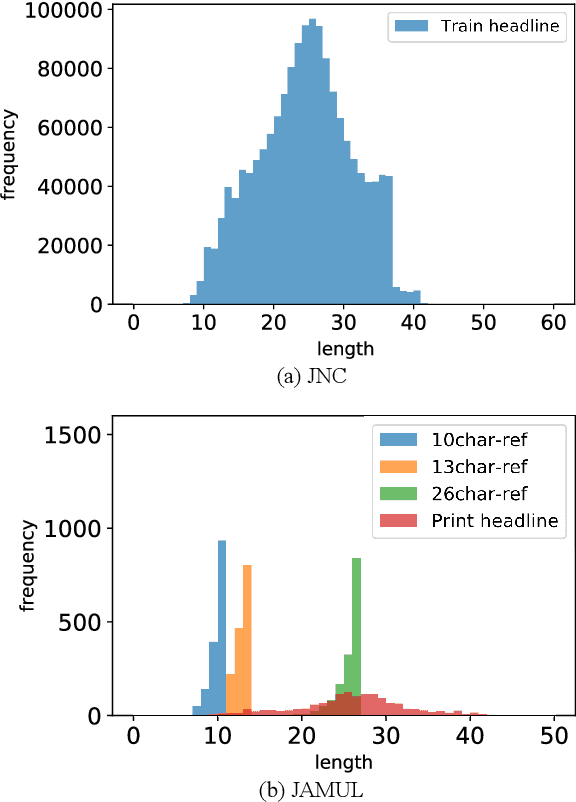

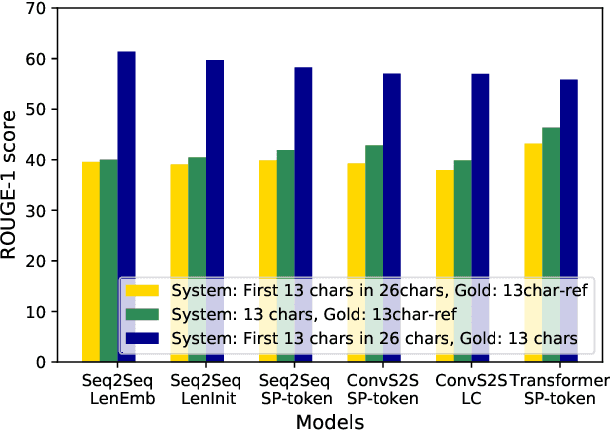
Browsing news articles on multiple devices is now possible. The lengths of news article headlines have precise upper bounds, dictated by the size of the display of the relevant device or interface. Therefore, controlling the length of headlines is essential when applying the task of headline generation to news production. However, because there is no corpus of headlines of multiple lengths for a given article, prior researches on controlling output length in headline generation have not discussed whether the evaluation of the setting that uses a single length reference can evaluate multiple length outputs appropriately. In this paper, we introduce two corpora (JNC and JAMUL) to confirm the validity of prior experimental settings and provide for the next step toward the goal of controlling output length in headline generation. The JNC provides common supervision data for headline generation. The JAMUL is a large-scale evaluation dataset for headlines of three different lengths composed by professional editors. We report new findings on these corpora; for example, while the longest length reference summary can appropriately evaluate the existing methods controlling output length, the methods do not manage the selection of words according to length constraint.
ESPnet: End-to-End Speech Processing Toolkit
Mar 30, 2018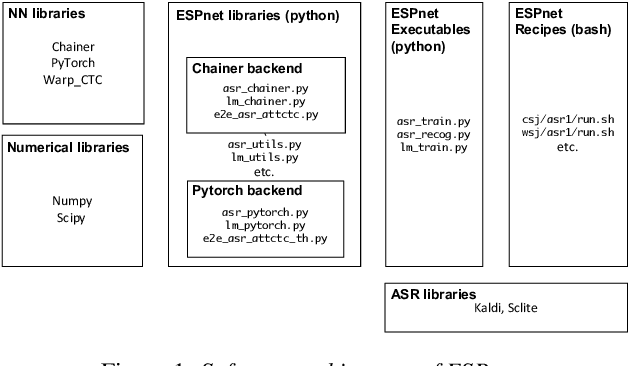
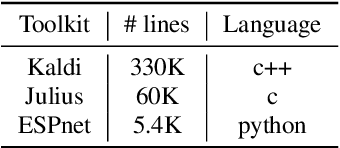
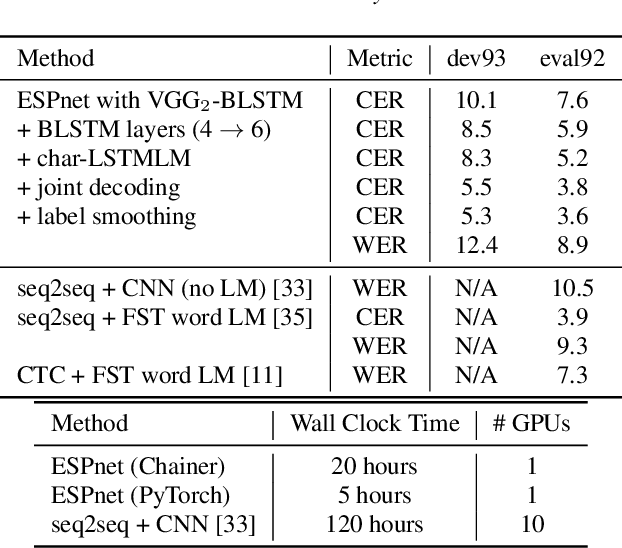
This paper introduces a new open source platform for end-to-end speech processing named ESPnet. ESPnet mainly focuses on end-to-end automatic speech recognition (ASR), and adopts widely-used dynamic neural network toolkits, Chainer and PyTorch, as a main deep learning engine. ESPnet also follows the Kaldi ASR toolkit style for data processing, feature extraction/format, and recipes to provide a complete setup for speech recognition and other speech processing experiments. This paper explains a major architecture of this software platform, several important functionalities, which differentiate ESPnet from other open source ASR toolkits, and experimental results with major ASR benchmarks.