 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Financial Consumer Complaints through Multi-Scale Model Interaction
Apr 14, 2025Legal writing demands clarity, formality, and domain-specific precision-qualities often lacking in documents authored by individuals without legal training. To bridge this gap, this paper explores the task of legal text refinement that transforms informal, conversational inputs into persuasive legal arguments. We introduce FinDR, a Chinese dataset of financial dispute records, annotated with official judgments on claim reasonableness. Our proposed method, Multi-Scale Model Interaction (MSMI), leverages a lightweight classifier to evaluate outputs and guide iterative refinement by Large Language Models (LLMs). Experimental results demonstrate that MSMI significantly outperforms single-pass prompting strategies. Additionally, we validate the generalizability of MSMI on several short-text benchmarks, showing improved adversarial robustness. Our findings reveal the potential of multi-model collaboration for enhancing legal document generation and broader text refinement tasks.
Tracking Players in a Badminton Court by Two Cameras
Aug 09, 2023This study proposes a simple method for multi-object tracking (MOT) of players in a badminton court. We leverage two off-the-shelf cameras, one on the top of the court and the other on the side of the court. The one on the top is to track players' trajectories, while the one on the side is to analyze the pixel features of players. By computing the correlations between adjacent frames and engaging the information of the two cameras, MOT of badminton players is obtained. This two-camera approach addresses the challenge of player occlusion and overlapping in a badminton court, providing player trajectory tracking and multi-angle analysis. The presented system offers insights into the positions and movements of badminton players, thus serving as a coaching or self-training tool for badminton players to improve their gaming strategies.
Efficient Multiple Incremental Computation for Kernel Ridge Regression with Bayesian Uncertainty Modeling
Nov 09, 2017


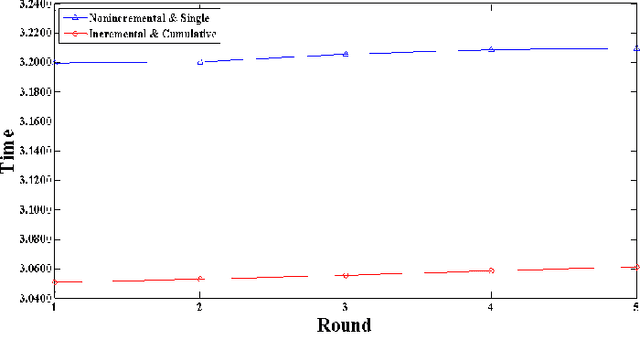
This study presents an efficient incremental/decremental approach for big streams based on Kernel Ridge Regression (KRR), a frequently used data analysis in cloud centers. To avoid reanalyzing the whole dataset whenever sensors receive new training data, typical incremental KRR used a single-instance mechanism for updating an existing system. However, this inevitably increased redundant computational time, not to mention applicability to big streams. To this end, the proposed mechanism supports incremental/decremental processing for both single and multiple samples (i.e., batch processing). A large scale of data can be divided into batches, processed by a machine, without sacrificing the accuracy. Moreover, incremental/decremental analyses in empirical and intrinsic space are also proposed in this study to handle different types of data either with a large number of samples or high feature dimensions, whereas typical methods focused only on one type. At the end of this study, we further the proposed mechanism to statistical Kernelized Bayesian Regression, so that uncertainty modeling with incremental/decremental computation becomes applicable. Experimental results showed that computational time was significantly reduced, better than the original nonincremental design and the typical single incremental method. Furthermore, the accuracy of the proposed method remained the same as the baselines. This implied that the system enhanced efficiency without sacrificing the accuracy. These findings proved that the proposed method was appropriate for variable streaming data analysis, thereby demonstrating the effectiveness of the proposed method.
Privacy-Preserved Big Data Analysis Based on Asymmetric Imputation Kernels and Multiside Similarities
Nov 21, 2016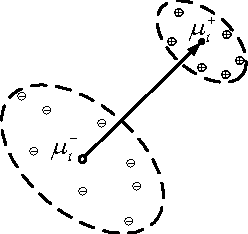

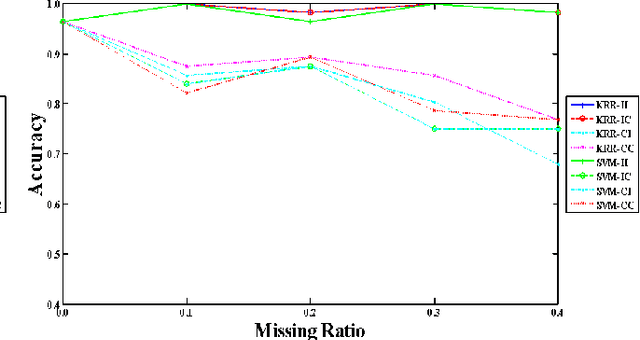

This study presents an efficient approach for incomplete data classification, where the entries of samples are missing or masked due to privacy preservation. To deal with these incomplete data, a new kernel function with asymmetric intrinsic mappings is proposed in this study. Such a new kernel uses three-side similarities for kernel matrix formation. The similarity between a testing instance and a training sample relies not only on their distance but also on the relation between the testing sample and the centroid of the class, where the training sample belongs. This reduces biased estimation compared with typical methods when only one training sample is used for kernel matrix formation. Furthermore, centroid generation does not involve any clustering algorithms. The proposed kernel is capable of performing data imputation by using class-dependent averages. This enhances Fisher Discriminant Ratios and data discriminability. Experiments on two open databases were carried out for evaluating the proposed method. The result indicated that the accuracy of the proposed method was higher than that of the baseline. These findings thereby demonstrated the effectiveness of the proposed idea.
Recursion-Free Online Multiple Incremental/Decremental Analysis Based on Ridge Support Vector Learning
Oct 11, 2016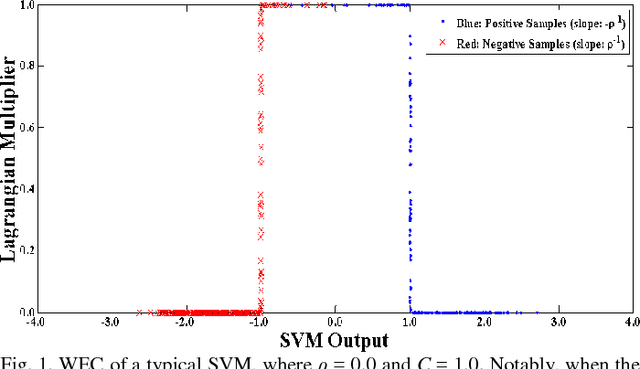

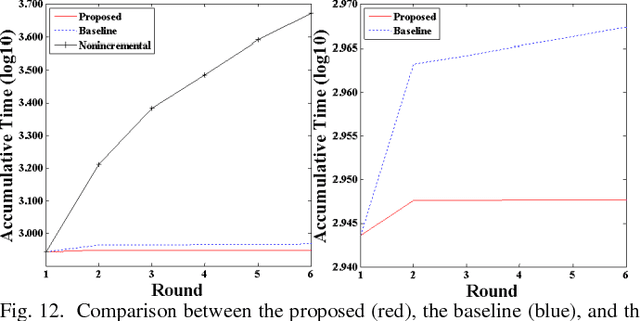

This study presents a rapid multiple incremental and decremental mechanism based on Weight-Error Curves (WECs) for support-vector analysis. Recursion-free computation is proposed for predicting the Lagrangian multipliers of new samples. This study examines Ridge Support Vector Models, subsequently devising a recursion-free function derived from WECs. With the proposed function, all the new Lagrangian multipliers can be computed at once without using any gradual step sizes. Moreover, such a function relaxes a constraint, where the increment of new multiple Lagrangian multipliers should be the same in the previous work, thereby easily satisfying the requirement of KKT conditions. The proposed mechanism no longer requires typical bookkeeping strategies, which compute the step size by checking all the training samples in each incremental round.
Efficient Divide-And-Conquer Classification Based on Feature-Space Decomposition
Jan 29, 2015
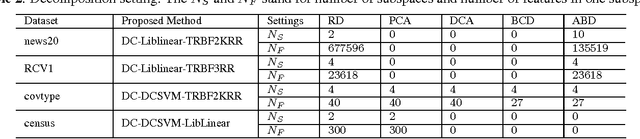
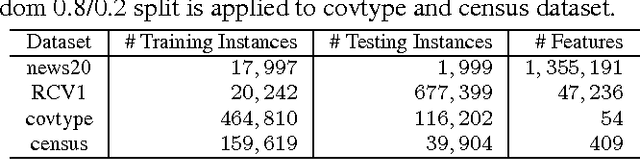

This study presents a divide-and-conquer (DC) approach based on feature space decomposition for classification. When large-scale datasets are present, typical approaches usually employed truncated kernel methods on the feature space or DC approaches on the sample space. However, this did not guarantee separability between classes, owing to overfitting. To overcome such problems, this work proposes a novel DC approach on feature spaces consisting of three steps. Firstly, we divide the feature space into several subspaces using the decomposition method proposed in this paper. Subsequently, these feature subspaces are sent into individual local classifiers for training. Finally, the outcomes of local classifiers are fused together to generate the final classification results. Experiments on large-scale datasets are carried out for performance evaluation. The results show that the error rates of the proposed DC method decreased comparing with the state-of-the-art fast SVM solvers, e.g., reducing error rates by 10.53% and 7.53% on RCV1 and covtype datasets respectively.