 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserved Big Data Analysis Based on Asymmetric Imputation Kernels and Multiside Similarities
Paper and Code
Nov 21, 2016

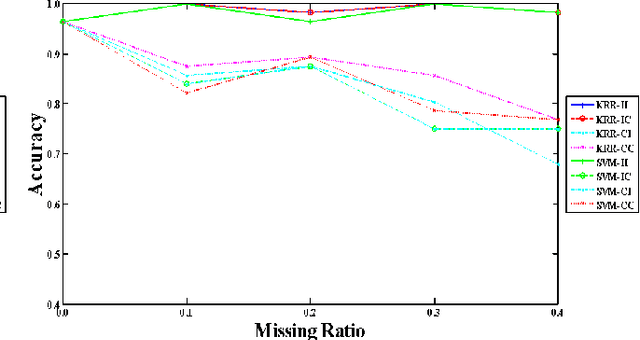

This study presents an efficient approach for incomplete data classification, where the entries of samples are missing or masked due to privacy preservation. To deal with these incomplete data, a new kernel function with asymmetric intrinsic mappings is proposed in this study. Such a new kernel uses three-side similarities for kernel matrix formation. The similarity between a testing instance and a training sample relies not only on their distance but also on the relation between the testing sample and the centroid of the class, where the training sample belongs. This reduces biased estimation compared with typical methods when only one training sample is used for kernel matrix formation. Furthermore, centroid generation does not involve any clustering algorithms. The proposed kernel is capable of performing data imputation by using class-dependent averages. This enhances Fisher Discriminant Ratios and data discriminability. Experiments on two open databases were carried out for evaluating the proposed method. The result indicated that the accuracy of the proposed method was higher than that of the baseline. These findings thereby demonstrated the effectiveness of the proposed idea.