 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Kaleidoscope: Engaging AI with Pluralistic Human Values, Rights, and Duties
Sep 02, 2023Human values are crucial to human decision-making. Value pluralism is the view that multiple correct values may be held in tension with one another (e.g., when considering lying to a friend to protect their feelings, how does one balance honesty with friendship?). As statistical learners, AI systems fit to averages by default, washing out these potentially irreducible value conflicts. To improve AI systems to better reflect value pluralism, the first-order challenge is to explore the extent to which AI systems can model pluralistic human values, rights, and duties as well as their interaction. We introduce ValuePrism, a large-scale dataset of 218k values, rights, and duties connected to 31k human-written situations. ValuePrism's contextualized values are generated by GPT-4 and deemed high-quality by human annotators 91% of the time. We conduct a large-scale study with annotators across diverse social and demographic backgrounds to try to understand whose values are represented. With ValuePrism, we build Kaleido, an open, light-weight, and structured language-based multi-task model that generates, explains, and assesses the relevance and valence (i.e., support or oppose) of human values, rights, and duties within a specific context. Humans prefer the sets of values output by our system over the teacher GPT-4, finding them more accurate and with broader coverage. In addition, we demonstrate that Kaleido can help explain variability in human decision-making by outputting contrasting values. Finally, we show that Kaleido's representations transfer to other philosophical frameworks and datasets, confirming the benefit of an explicit, modular, and interpretable approach to value pluralism. We hope that our work will serve as a step to making more explicit the implicit values behind human decision-making and to steering AI systems to make decisions that are more in accordance with them.
Back to the Future: Unsupervised Backprop-based Decoding for Counterfactual and Abductive Commonsense Reasoning
Oct 20, 2020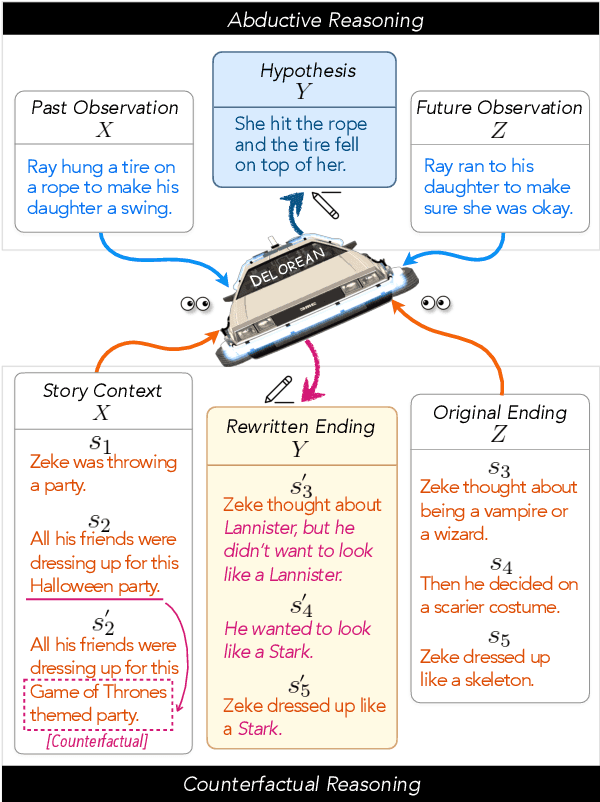
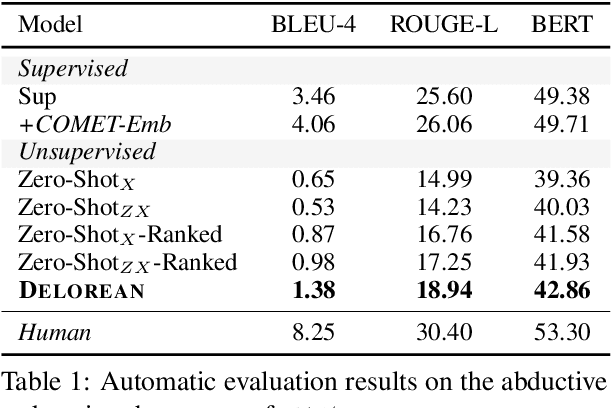
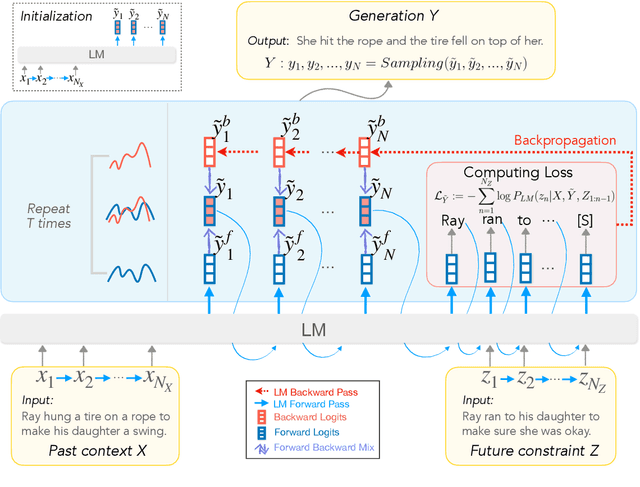
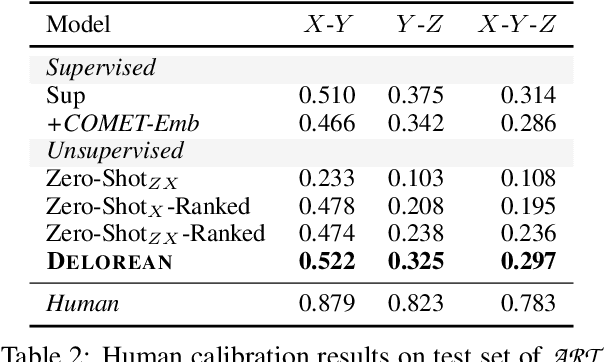
Abductive and counterfactual reasoning, core abilities of everyday human cognition, require reasoning about what might have happened at time t, while conditioning on multiple contexts from the relative past and future. However, simultaneous incorporation of past and future contexts using generative language models (LMs) can be challenging, as they are trained either to condition only on the past context or to perform narrowly scoped text-infilling. In this paper, we propose DeLorean, a new unsupervised decoding algorithm that can flexibly incorporate both the past and future contexts using only off-the-shelf, left-to-right language models and no supervision. The key intuition of our algorithm is incorporating the future through back-propagation, during which, we only update the internal representation of the output while fixing the model parameters. By alternating between forward and backward propagation, DeLorean can decode the output representation that reflects both the left and right contexts. We demonstrate that our approach is general and applicable to two nonmonotonic reasoning tasks: abductive text generation and counterfactual story revision, where DeLorean outperforms a range of unsupervised and some supervised methods, based on automatic and human evaluation.
Reflective Decoding: Unsupervised Paraphrasing and Abductive Reasoning
Oct 16, 2020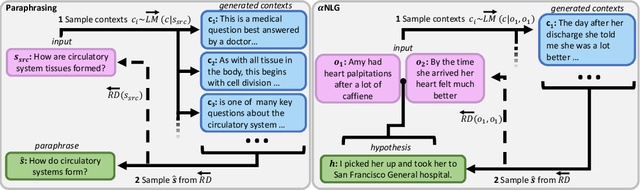
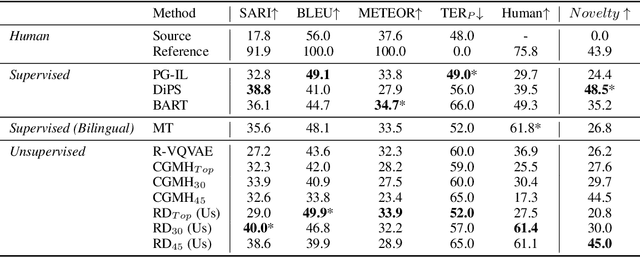

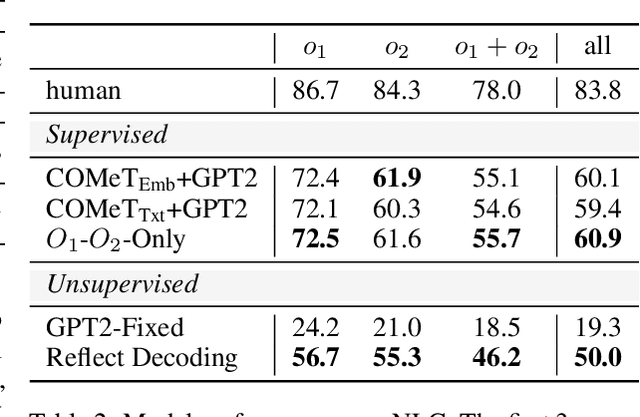
Pretrained Language Models (LMs) generate text with remarkable quality, novelty,and coherence. Yet applying LMs to the problems of paraphrasing and infilling currently requires direct supervision, since these tasks break the left-to-right generation setup of pretrained LMs. We present Reflective Decoding, a novel unsupervised approach to apply the capabilities of pretrained LMs to non-sequential tasks. Our approach is general and applicable to two distant tasks - paraphrasing and abductive reasoning. It requires no supervision or parallel corpora, only two pretrained language models: forward and backward. Reflective Decoding operates in two intuitive steps. In the contextualization step, we use LMs to generate many left and right contexts which collectively capture the meaning of the input sentence. Then, in the reflection step we decode in the semantic neighborhood of the input, conditioning on an ensemble of generated contexts with the reverse direction LM. We reflect through the generated contexts, effectively using them as an intermediate meaning representation to generate conditional output. Empirical results demonstrate that Reflective Decoding outperforms strong unsupervised baselines on both paraphrasing and abductive text infilling, significantly narrowing the gap between unsupervised and supervised methods.Reflective Decoding introduces the concept of using generated contexts to represent meaning, opening up new possibilities for unsupervised conditional text generation.