 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow many simulations do we need for simulation-based inference in cosmology?
Mar 17, 2025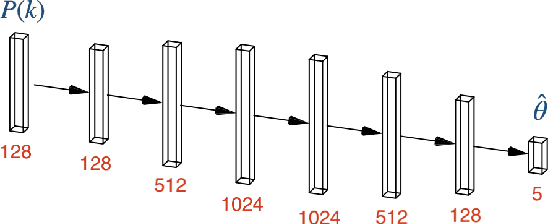
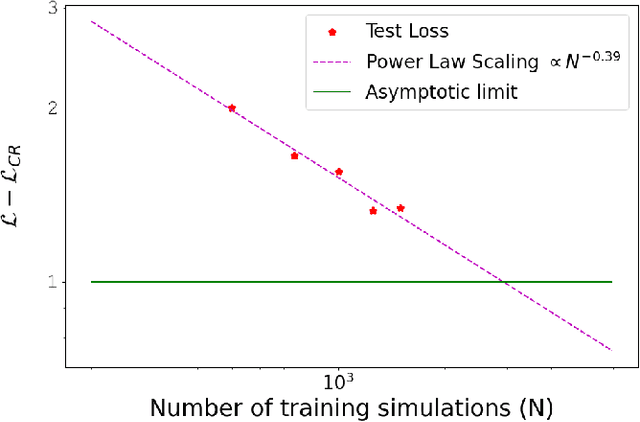
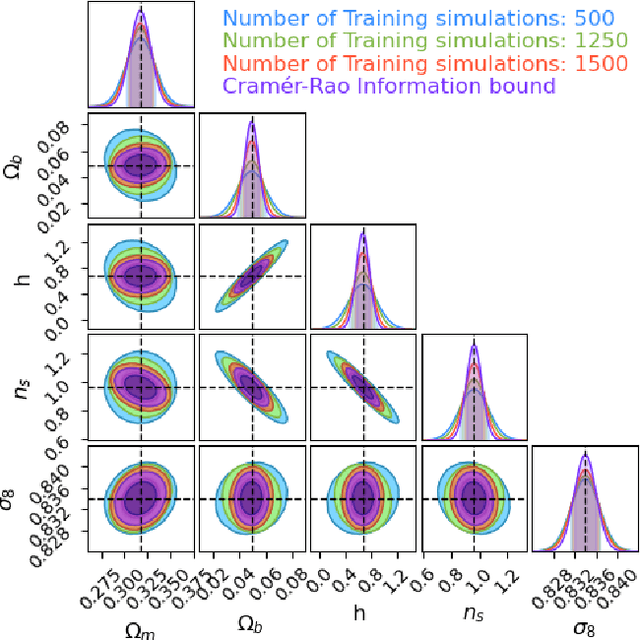
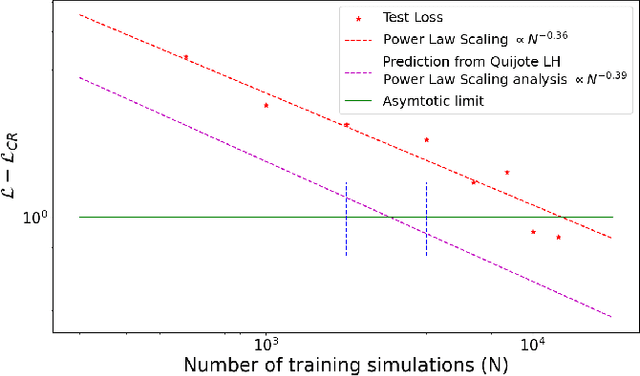
How many simulations do we need to train machine learning methods to extract information available from summary statistics of the cosmological density field? Neural methods have shown the potential to extract non-linear information available from cosmological data. Success depends critically on having sufficient simulations for training the networks and appropriate network architectures. In the first detailed convergence study of neural network training for cosmological inference, we show that currently available simulation suites, such as the Quijote Latin Hypercube(LH) with 2000 simulations, do not provide sufficient training data for a generic neural network to reach the optimal regime, even for the dark matter power spectrum, and in an idealized case. We discover an empirical neural scaling law that predicts how much information a neural network can extract from a highly informative summary statistic, the dark matter power spectrum, as a function of the number of simulations used to train the network, for a wide range of architectures and hyperparameters. We combine this result with the Cramer-Rao information bound to forecast the number of training simulations needed for near-optimal information extraction. To verify our method we created the largest publicly released simulation data set in cosmology, the Big Sobol Sequence(BSQ), consisting of 32,768 $\Lambda$CDM n-body simulations uniformly covering the $\Lambda$CDM parameter space. Our method enables efficient planning of simulation campaigns for machine learning applications in cosmology, while the BSQ dataset provides an unprecedented resource for studying the convergence behavior of neural networks in cosmological parameter inference. Our results suggest that new large simulation suites or new training approaches will be necessary to achieve information-optimal parameter inference from non-linear simulations.