 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancement-Driven Pretraining for Robust Fingerprint Representation Learning
Feb 16, 2024



Fingerprint recognition stands as a pivotal component of biometric technology, with diverse applications from identity verification to advanced search tools. In this paper, we propose a unique method for deriving robust fingerprint representations by leveraging enhancement-based pre-training. Building on the achievements of U-Net-based fingerprint enhancement, our method employs a specialized encoder to derive representations from fingerprint images in a self-supervised manner. We further refine these representations, aiming to enhance the verification capabilities. Our experimental results, tested on publicly available fingerprint datasets, reveal a marked improvement in verification performance against established self-supervised training techniques. Our findings not only highlight the effectiveness of our method but also pave the way for potential advancements. Crucially, our research indicates that it is feasible to extract meaningful fingerprint representations from degraded images without relying on enhanced samples.
* 8 pages, 4 figures, Accepted at 19th VISIGRAPP 2024: VISAPP conference
Center Loss Regularization for Continual Learning
Oct 21, 2021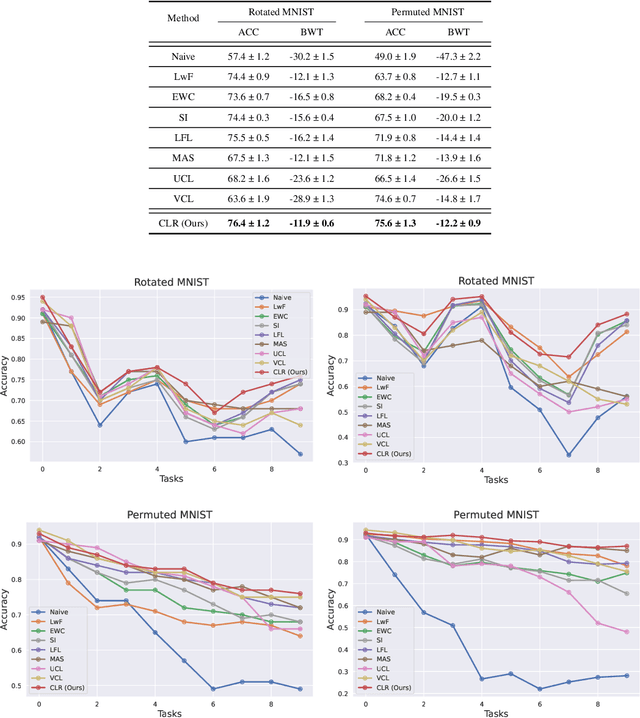
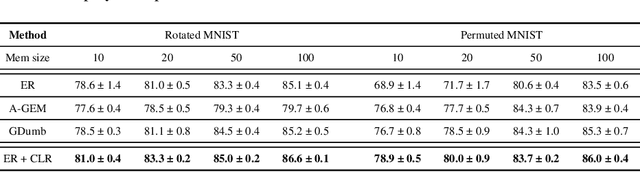
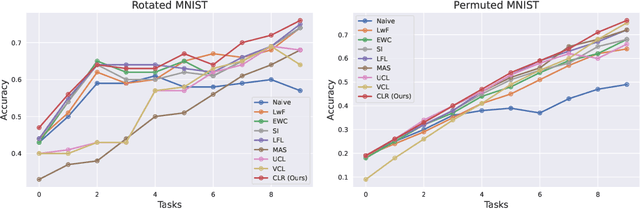
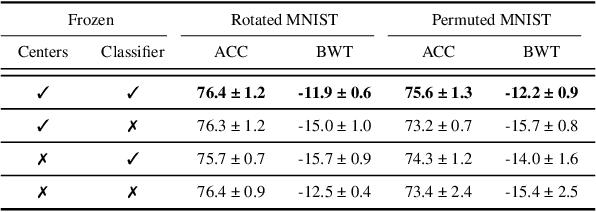
The ability to learn different tasks sequentially is essential to the development of artificial intelligence. In general, neural networks lack this capability, the major obstacle being catastrophic forgetting. It occurs when the incrementally available information from non-stationary data distributions is continually acquired, disrupting what the model has already learned. Our approach remembers old tasks by projecting the representations of new tasks close to that of old tasks while keeping the decision boundaries unchanged. We employ the center loss as a regularization penalty that enforces new tasks' features to have the same class centers as old tasks and makes the features highly discriminative. This, in turn, leads to the least forgetting of already learned information. This method is easy to implement, requires minimal computational and memory overhead, and allows the neural network to maintain high performance across many sequentially encountered tasks. We also demonstrate that using the center loss in conjunction with the memory replay outperforms other replay-based strategies. Along with standard MNIST variants for continual learning, we apply our method to continual domain adaptation scenarios with the Digits and PACS datasets. We demonstrate that our approach is scalable, effective, and gives competitive performance compared to state-of-the-art continual learning methods.
Deep CNNs for Peripheral Blood Cell Classification
Oct 18, 2021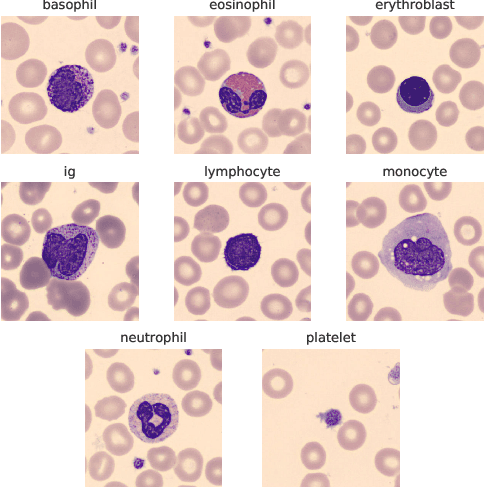
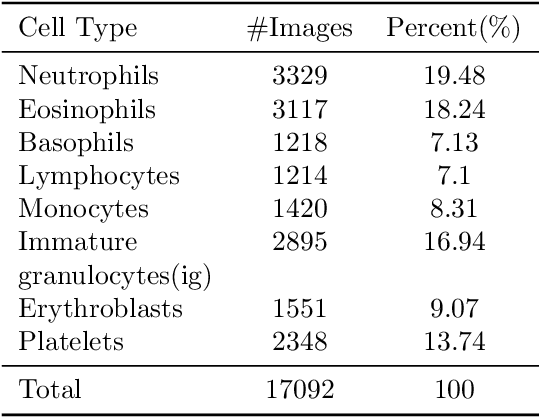
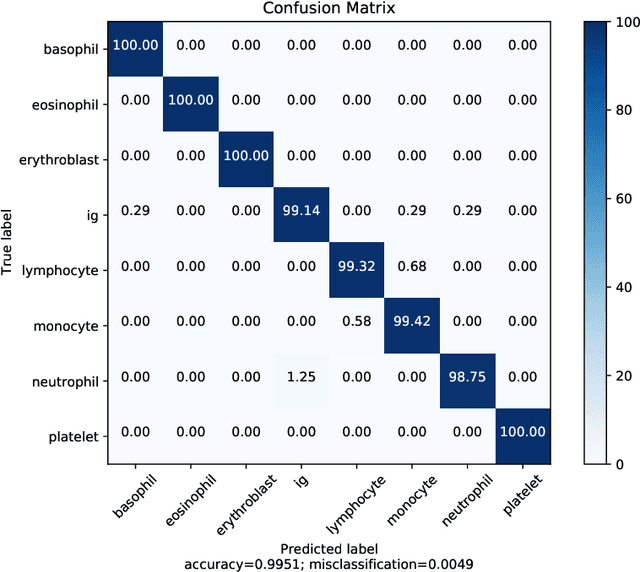
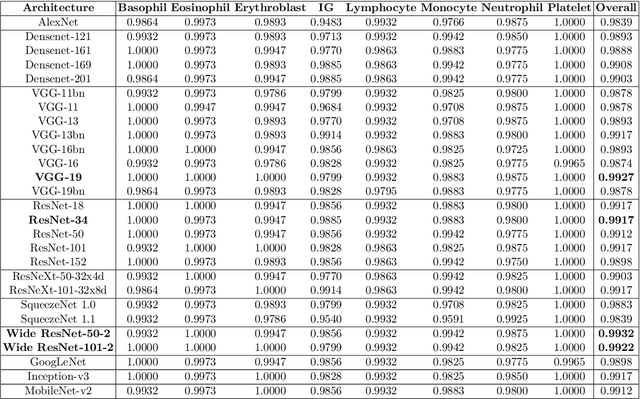
The application of machine learning techniques to the medical domain is especially challenging due to the required level of precision and the incurrence of huge risks of minute errors. Employing these techniques to a more complex subdomain of hematological diagnosis seems quite promising, with automatic identification of blood cell types, which can help in detection of hematologic disorders. In this paper, we benchmark 27 popular deep convolutional neural network architectures on the microscopic peripheral blood cell images dataset. The dataset is publicly available, with large number of normal peripheral blood cells acquired using the CellaVision DM96 analyzer and identified by expert pathologists into eight different cell types. We fine-tune the state-of-the-art image classification models pre-trained on the ImageNet dataset for blood cell classification. We exploit data augmentation techniques during training to avoid overfitting and achieve generalization. An ensemble of the top performing models obtains significant improvements over past published works, achieving the state-of-the-art results with a classification accuracy of 99.51%. Our work provides empirical baselines and benchmarks on standard deep-learning architectures for microscopic peripheral blood cell recognition task.