 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-Aware Binarization of Neural Networks for Sketch Recognition
Paper and Code
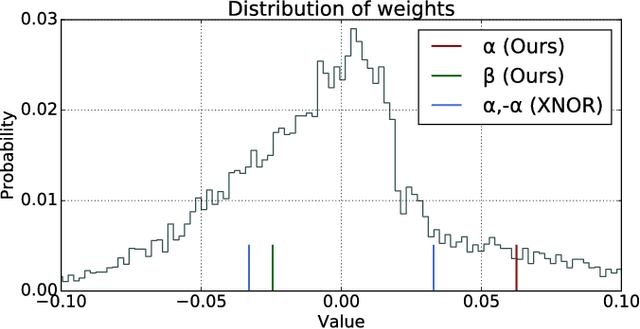

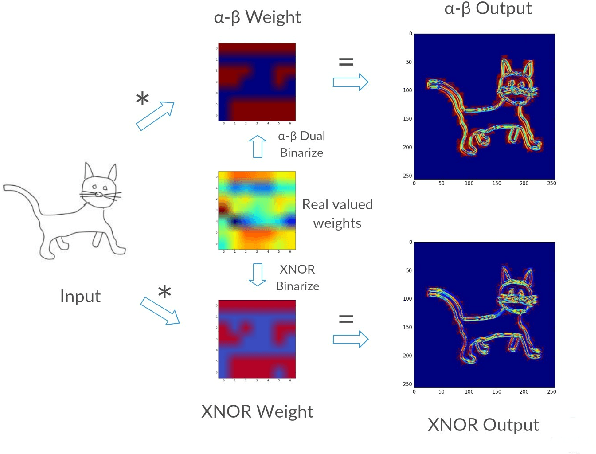

Deep neural networks are highly effective at a range of computational tasks. However, they tend to be computationally expensive, especially in vision-related problems, and also have large memory requirements. One of the most effective methods to achieve significant improvements in computational/spatial efficiency is to binarize the weights and activations in a network. However, naive binarization results in accuracy drops when applied to networks for most tasks. In this work, we present a highly generalized, distribution-aware approach to binarizing deep networks that allows us to retain the advantages of a binarized network, while reducing accuracy drops. We also develop efficient implementations for our proposed approach across different architectures. We present a theoretical analysis of the technique to show the effective representational power of the resulting layers, and explore the forms of data they model best. Experiments on popular datasets show that our technique offers better accuracies than naive binarization, while retaining the same benefits that binarization provides - with respect to run-time compression, reduction of computational costs, and power consumption.