 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Material Translator: Towards Spoof Fingerprint Generalization
Dec 08, 2019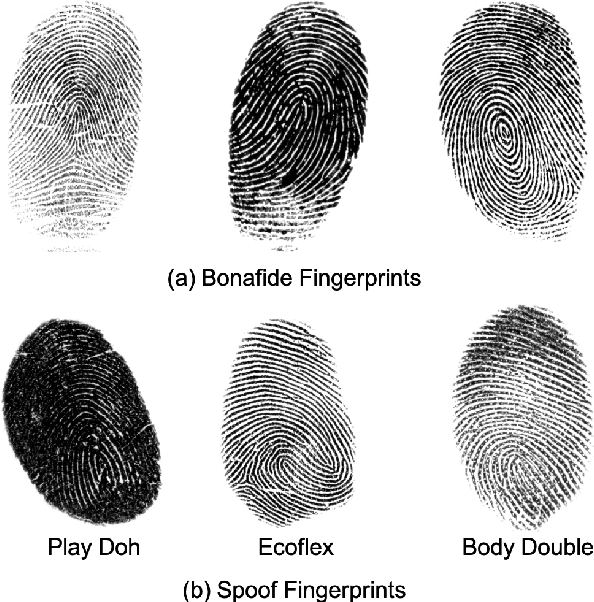
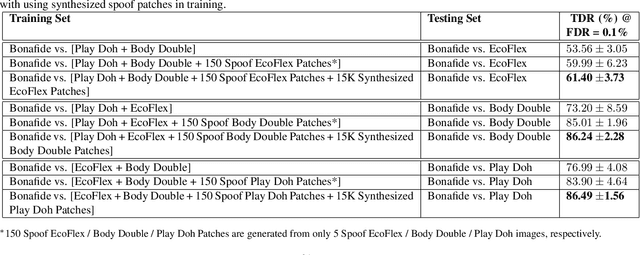
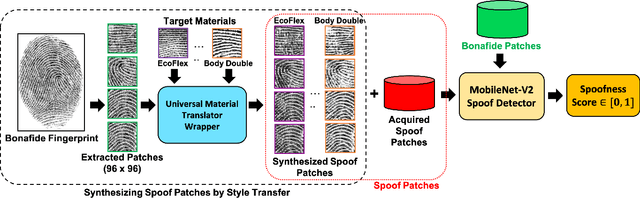
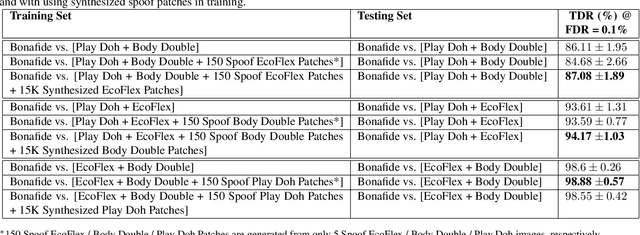
Spoof detectors are classifiers that are trained to distinguish spoof fingerprints from bonafide ones. However, state of the art spoof detectors do not generalize well on unseen spoof materials. This study proposes a style transfer based augmentation wrapper that can be used on any existing spoof detector and can dynamically improve the robustness of the spoof detection system on spoof materials for which we have very low data. Our method is an approach for synthesizing new spoof images from a few spoof examples that transfers the style or material properties of the spoof examples to the content of bonafide fingerprints to generate a larger number of examples to train the classifier on. We demonstrate the effectiveness of our approach on materials in the publicly available LivDet 2015 dataset and show that the proposed approach leads to robustness to fingerprint spoofs of the target material.
* 8 pages, 6 figures, conference
Hybrid Binary Networks: Optimizing for Accuracy, Efficiency and Memory
Apr 11, 2018
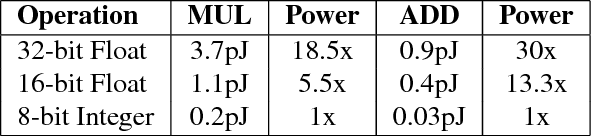
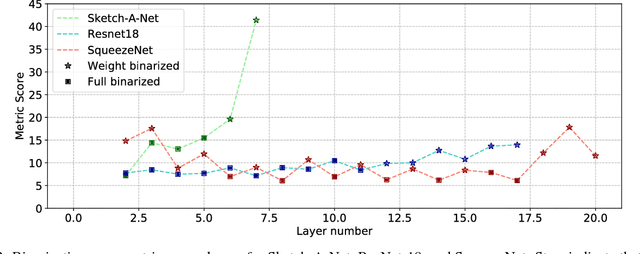
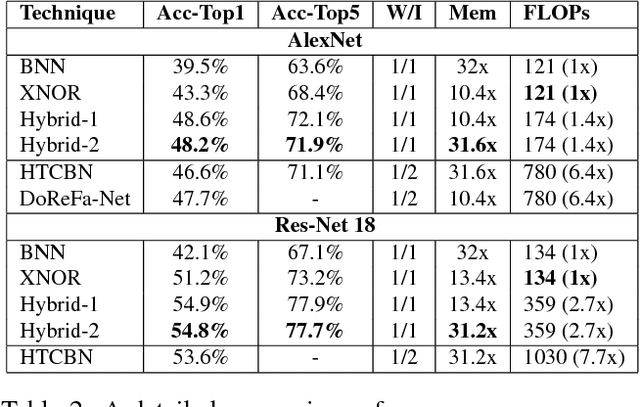
Binarization is an extreme network compression approach that provides large computational speedups along with energy and memory savings, albeit at significant accuracy costs. We investigate the question of where to binarize inputs at layer-level granularity and show that selectively binarizing the inputs to specific layers in the network could lead to significant improvements in accuracy while preserving most of the advantages of binarization. We analyze the binarization tradeoff using a metric that jointly models the input binarization-error and computational cost and introduce an efficient algorithm to select layers whose inputs are to be binarized. Practical guidelines based on insights obtained from applying the algorithm to a variety of models are discussed. Experiments on Imagenet dataset using AlexNet and ResNet-18 models show 3-4% improvements in accuracy over fully binarized networks with minimal impact on compression and computational speed. The improvements are even more substantial on sketch datasets like TU-Berlin, where we match state-of-the-art accuracy as well, getting over 8% increase in accuracies. We further show that our approach can be applied in tandem with other forms of compression that deal with individual layers or overall model compression (e.g., SqueezeNets). Unlike previous quantization approaches, we are able to binarize the weights in the last layers of a network, which often have a large number of parameters, resulting in significant improvement in accuracy over fully binarized models.
Distribution-Aware Binarization of Neural Networks for Sketch Recognition
Apr 09, 2018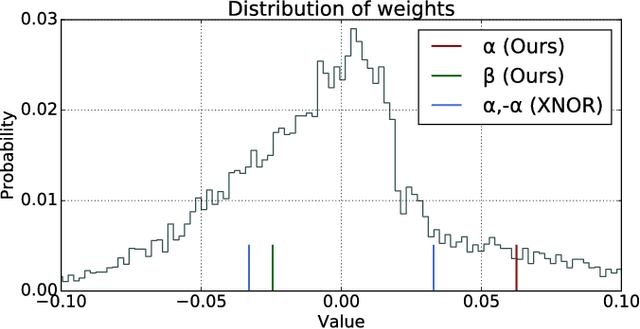

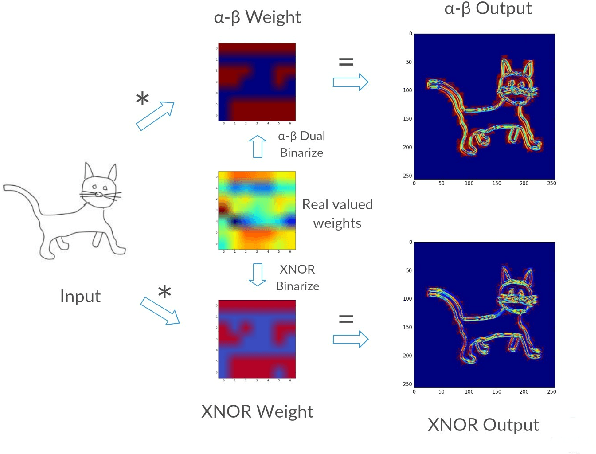

Deep neural networks are highly effective at a range of computational tasks. However, they tend to be computationally expensive, especially in vision-related problems, and also have large memory requirements. One of the most effective methods to achieve significant improvements in computational/spatial efficiency is to binarize the weights and activations in a network. However, naive binarization results in accuracy drops when applied to networks for most tasks. In this work, we present a highly generalized, distribution-aware approach to binarizing deep networks that allows us to retain the advantages of a binarized network, while reducing accuracy drops. We also develop efficient implementations for our proposed approach across different architectures. We present a theoretical analysis of the technique to show the effective representational power of the resulting layers, and explore the forms of data they model best. Experiments on popular datasets show that our technique offers better accuracies than naive binarization, while retaining the same benefits that binarization provides - with respect to run-time compression, reduction of computational costs, and power consumption.