 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Binary Networks: Optimizing for Accuracy, Efficiency and Memory
Paper and Code

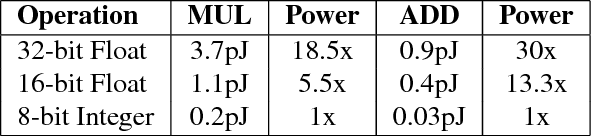
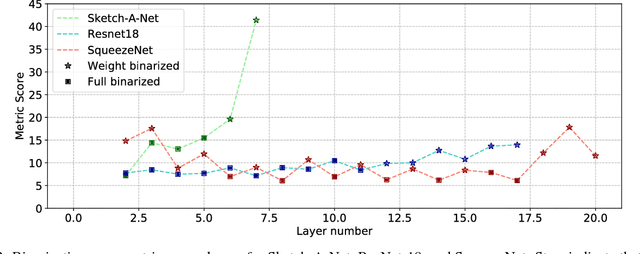
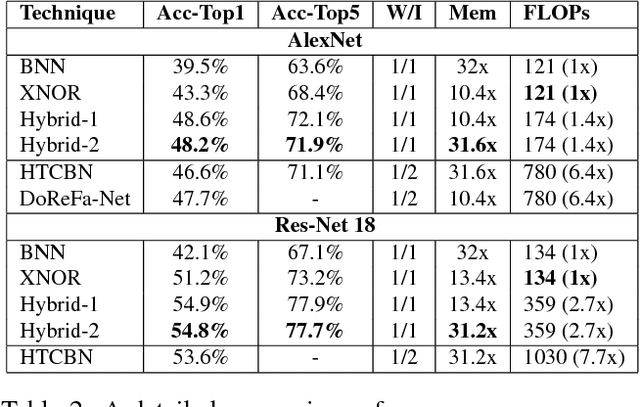
Binarization is an extreme network compression approach that provides large computational speedups along with energy and memory savings, albeit at significant accuracy costs. We investigate the question of where to binarize inputs at layer-level granularity and show that selectively binarizing the inputs to specific layers in the network could lead to significant improvements in accuracy while preserving most of the advantages of binarization. We analyze the binarization tradeoff using a metric that jointly models the input binarization-error and computational cost and introduce an efficient algorithm to select layers whose inputs are to be binarized. Practical guidelines based on insights obtained from applying the algorithm to a variety of models are discussed. Experiments on Imagenet dataset using AlexNet and ResNet-18 models show 3-4% improvements in accuracy over fully binarized networks with minimal impact on compression and computational speed. The improvements are even more substantial on sketch datasets like TU-Berlin, where we match state-of-the-art accuracy as well, getting over 8% increase in accuracies. We further show that our approach can be applied in tandem with other forms of compression that deal with individual layers or overall model compression (e.g., SqueezeNets). Unlike previous quantization approaches, we are able to binarize the weights in the last layers of a network, which often have a large number of parameters, resulting in significant improvement in accuracy over fully binarized models.