 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaolin: A PyTorch Library for Accelerating 3D Deep Learning Research
Nov 13, 2019

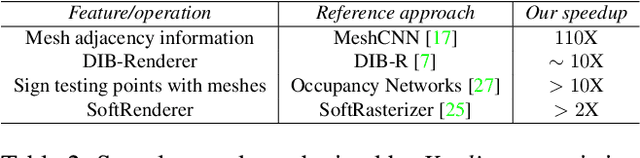

We present Kaolin, a PyTorch library aiming to accelerate 3D deep learning research. Kaolin provides efficient implementations of differentiable 3D modules for use in deep learning systems. With functionality to load and preprocess several popular 3D datasets, and native functions to manipulate meshes, pointclouds, signed distance functions, and voxel grids, Kaolin mitigates the need to write wasteful boilerplate code. Kaolin packages together several differentiable graphics modules including rendering, lighting, shading, and view warping. Kaolin also supports an array of loss functions and evaluation metrics for seamless evaluation and provides visualization functionality to render the 3D results. Importantly, we curate a comprehensive model zoo comprising many state-of-the-art 3D deep learning architectures, to serve as a starting point for future research endeavours. Kaolin is available as open-source software at https://github.com/NVIDIAGameWorks/kaolin/.
Flight Dynamics-based Recovery of a UAV Trajectory using Ground Cameras
Nov 21, 2017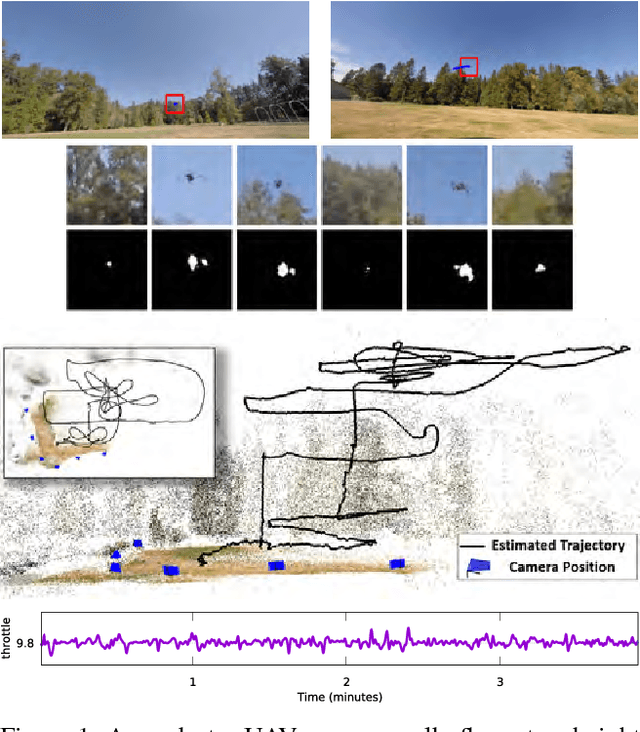

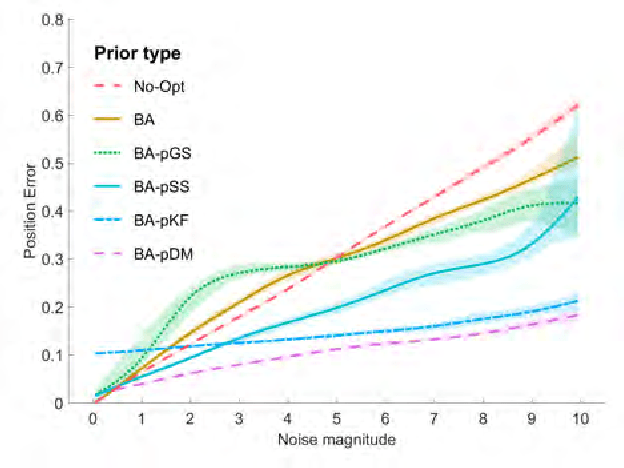
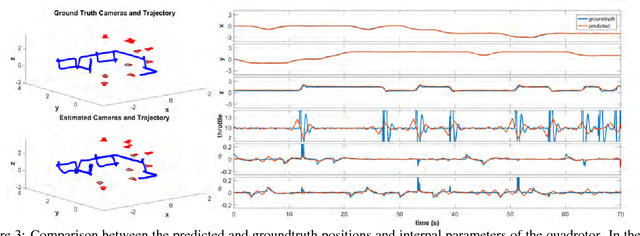
We propose a new method to estimate the 6-dof trajectory of a flying object such as a quadrotor UAV within a 3D airspace monitored using multiple fixed ground cameras. It is based on a new structure from motion formulation for the 3D reconstruction of a single moving point with known motion dynamics. Our main contribution is a new bundle adjustment procedure which in addition to optimizing the camera poses, regularizes the point trajectory using a prior based on motion dynamics (or specifically flight dynamics). Furthermore, we can infer the underlying control input sent to the UAV's autopilot that determined its flight trajectory. Our method requires neither perfect single-view tracking nor appearance matching across views. For robustness, we allow the tracker to generate multiple detections per frame in each video. The true detections and the data association across videos is estimated using robust multi-view triangulation and subsequently refined during our bundle adjustment procedure. Quantitative evaluation on simulated data and experiments on real videos from indoor and outdoor scenes demonstrates the effectiveness of our method.
Residual Parameter Transfer for Deep Domain Adaptation
Nov 21, 2017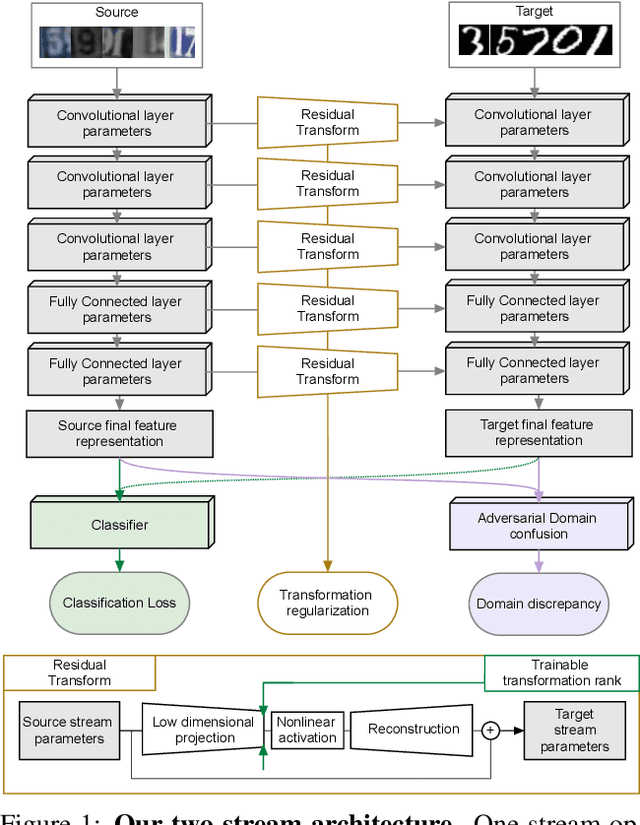

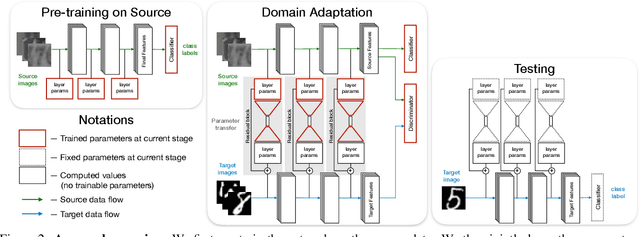

The goal of Deep Domain Adaptation is to make it possible to use Deep Nets trained in one domain where there is enough annotated training data in another where there is little or none. Most current approaches have focused on learning feature representations that are invariant to the changes that occur when going from one domain to the other, which means using the same network parameters in both domains. While some recent algorithms explicitly model the changes by adapting the network parameters, they either severely restrict the possible domain changes, or significantly increase the number of model parameters. By contrast, we introduce a network architecture that includes auxiliary residual networks, which we train to predict the parameters in the domain with little annotated data from those in the other one. This architecture enables us to flexibly preserve the similarities between domains where they exist and model the differences when necessary. We demonstrate that our approach yields higher accuracy than state-of-the-art methods without undue complexity.
Beyond Sharing Weights for Deep Domain Adaptation
Nov 17, 2016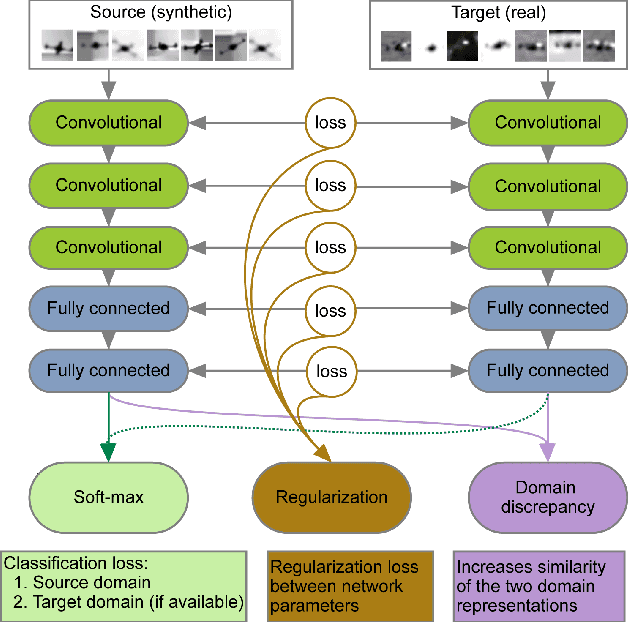


The performance of a classifier trained on data coming from a specific domain typically degrades when applied to a related but different one. While annotating many samples from the new domain would address this issue, it is often too expensive or impractical. Domain Adaptation has therefore emerged as a solution to this problem; It leverages annotated data from a source domain, in which it is abundant, to train a classifier to operate in a target domain, in which it is either sparse or even lacking altogether. In this context, the recent trend consists of learning deep architectures whose weights are shared for both domains, which essentially amounts to learning domain invariant features. Here, we show that it is more effective to explicitly model the shift from one domain to the other. To this end, we introduce a two-stream architecture, where one operates in the source domain and the other in the target domain. In contrast to other approaches, the weights in corresponding layers are related but not shared. We demonstrate that this both yields higher accuracy than state-of-the-art methods on several object recognition and detection tasks and consistently outperforms networks with shared weights in both supervised and unsupervised settings.
Direct Prediction of 3D Body Poses from Motion Compensated Sequences
Sep 02, 2016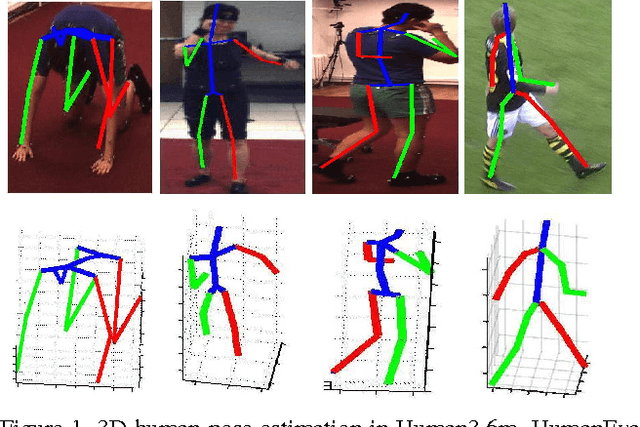
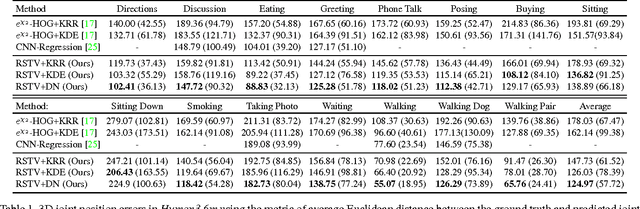
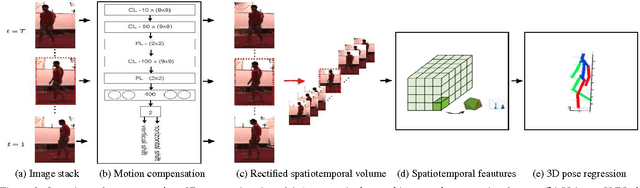

We propose an efficient approach to exploiting motion information from consecutive frames of a video sequence to recover the 3D pose of people. Previous approaches typically compute candidate poses in individual frames and then link them in a post-processing step to resolve ambiguities. By contrast, we directly regress from a spatio-temporal volume of bounding boxes to a 3D pose in the central frame. We further show that, for this approach to achieve its full potential, it is essential to compensate for the motion in consecutive frames so that the subject remains centered. This then allows us to effectively overcome ambiguities and improve upon the state-of-the-art by a large margin on the Human3.6m, HumanEva, and KTH Multiview Football 3D human pose estimation benchmarks.
On Rendering Synthetic Images for Training an Object Detector
Nov 28, 2014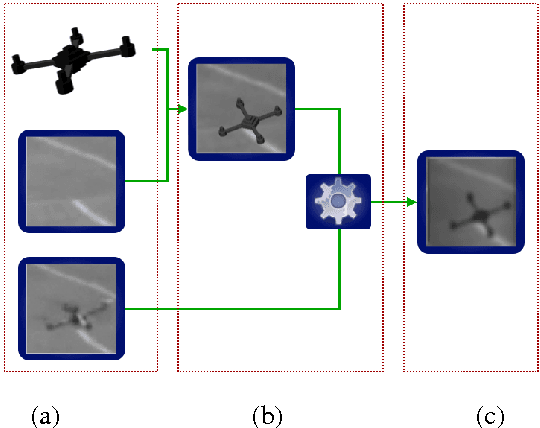
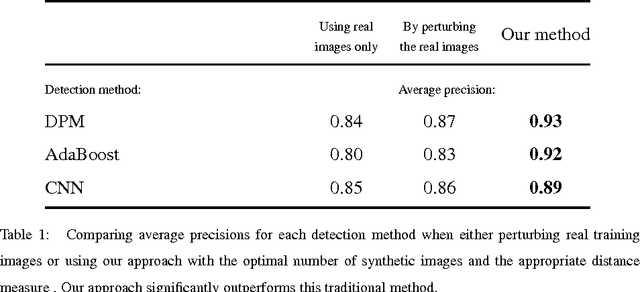

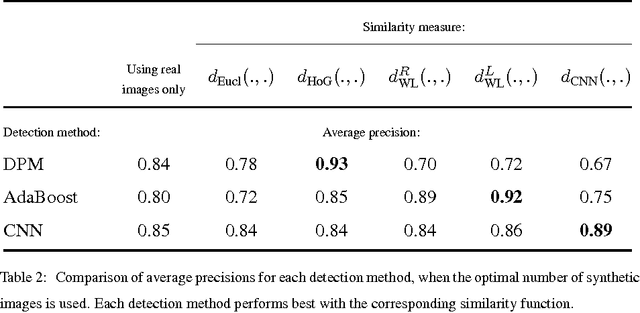
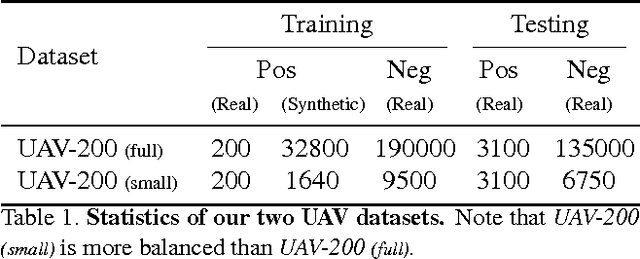
We propose a novel approach to synthesizing images that are effective for training object detectors. Starting from a small set of real images, our algorithm estimates the rendering parameters required to synthesize similar images given a coarse 3D model of the target object. These parameters can then be reused to generate an unlimited number of training images of the object of interest in arbitrary 3D poses, which can then be used to increase classification performances. A key insight of our approach is that the synthetically generated images should be similar to real images, not in terms of image quality, but rather in terms of features used during the detector training. We show in the context of drone, plane, and car detection that using such synthetically generated images yields significantly better performances than simply perturbing real images or even synthesizing images in such way that they look very realistic, as is often done when only limited amounts of training data are available.
Flying Objects Detection from a Single Moving Camera
Nov 27, 2014



We propose an approach to detect flying objects such as UAVs and aircrafts when they occupy a small portion of the field of view, possibly moving against complex backgrounds, and are filmed by a camera that itself moves. Solving such a difficult problem requires combining both appearance and motion cues. To this end we propose a regression-based approach to motion stabilization of local image patches that allows us to achieve effective classification on spatio-temporal image cubes and outperform state-of-the-art techniques. As the problem is relatively new, we collected two challenging datasets for UAVs and Aircrafts, which can be used as benchmarks for flying objects detection and vision-guided collision avoidance.