 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
PointInfinity: Resolution-Invariant Point Diffusion Models
Apr 04, 2024We present PointInfinity, an efficient family of point cloud diffusion models. Our core idea is to use a transformer-based architecture with a fixed-size, resolution-invariant latent representation. This enables efficient training with low-resolution point clouds, while allowing high-resolution point clouds to be generated during inference. More importantly, we show that scaling the test-time resolution beyond the training resolution improves the fidelity of generated point clouds and surfaces. We analyze this phenomenon and draw a link to classifier-free guidance commonly used in diffusion models, demonstrating that both allow trading off fidelity and variability during inference. Experiments on CO3D show that PointInfinity can efficiently generate high-resolution point clouds (up to 131k points, 31 times more than Point-E) with state-of-the-art quality.
ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
Jan 02, 2023

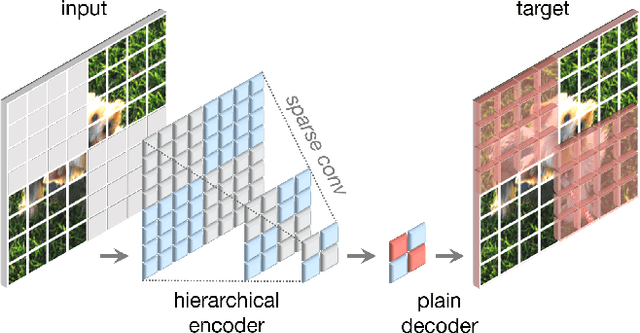

Driven by improved architectures and better representation learning frameworks, the field of visual recognition has enjoyed rapid modernization and performance boost in the early 2020s. For example, modern ConvNets, represented by ConvNeXt, have demonstrated strong performance in various scenarios. While these models were originally designed for supervised learning with ImageNet labels, they can also potentially benefit from self-supervised learning techniques such as masked autoencoders (MAE). However, we found that simply combining these two approaches leads to subpar performance. In this paper, we propose a fully convolutional masked autoencoder framework and a new Global Response Normalization (GRN) layer that can be added to the ConvNeXt architecture to enhance inter-channel feature competition. This co-design of self-supervised learning techniques and architectural improvement results in a new model family called ConvNeXt V2, which significantly improves the performance of pure ConvNets on various recognition benchmarks, including ImageNet classification, COCO detection, and ADE20K segmentation. We also provide pre-trained ConvNeXt V2 models of various sizes, ranging from an efficient 3.7M-parameter Atto model with 76.7% top-1 accuracy on ImageNet, to a 650M Huge model that achieves a state-of-the-art 88.9% accuracy using only public training data.
Exploring Long-Sequence Masked Autoencoders
Oct 13, 2022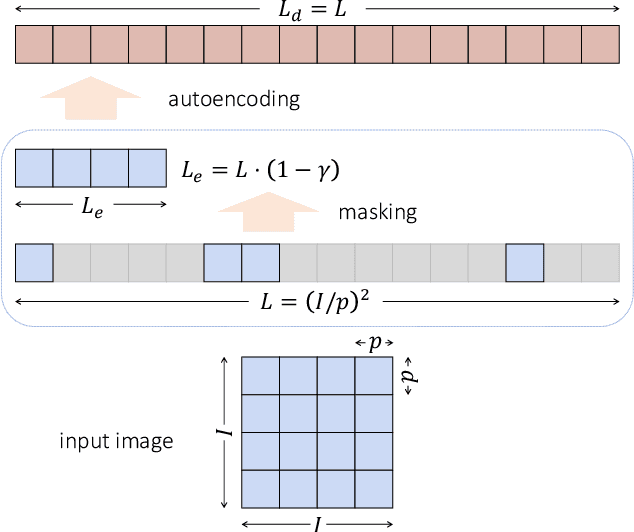

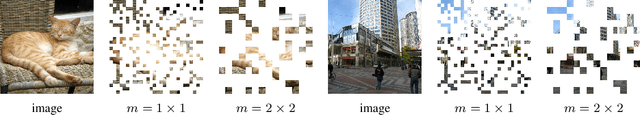

Masked Autoencoding (MAE) has emerged as an effective approach for pre-training representations across multiple domains. In contrast to discrete tokens in natural languages, the input for image MAE is continuous and subject to additional specifications. We systematically study each input specification during the pre-training stage, and find sequence length is a key axis that further scales MAE. Our study leads to a long-sequence version of MAE with minimal changes to the original recipe, by just decoupling the mask size from the patch size. For object detection and semantic segmentation, our long-sequence MAE shows consistent gains across all the experimental setups without extra computation cost during the transfer. While long-sequence pre-training is discerned most beneficial for detection and segmentation, we also achieve strong results on ImageNet-1K classification by keeping a standard image size and only increasing the sequence length. We hope our findings can provide new insights and avenues for scaling in computer vision.
RGB-D Local Implicit Function for Depth Completion of Transparent Objects
Apr 01, 2021
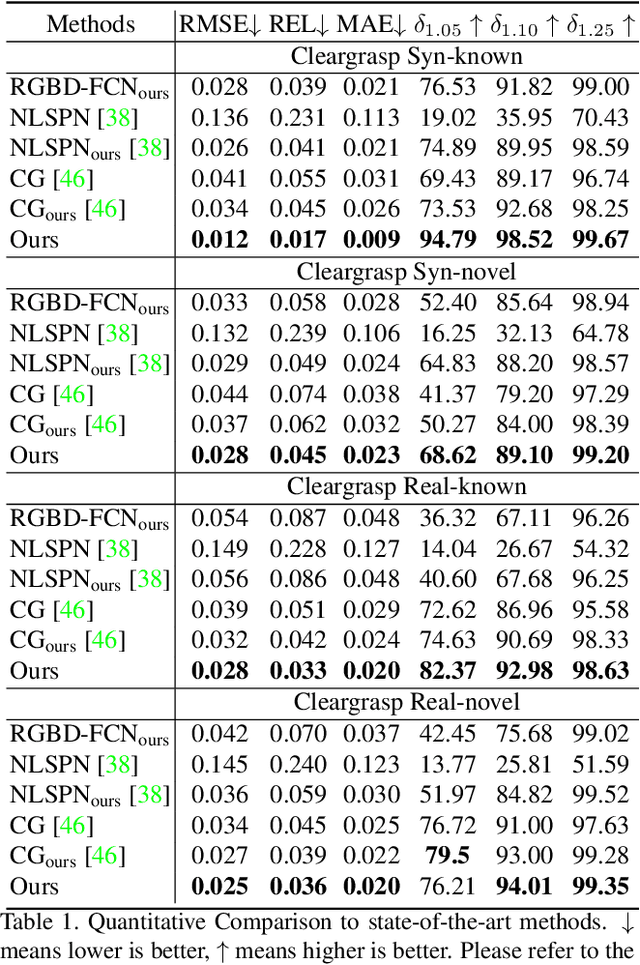


Majority of the perception methods in robotics require depth information provided by RGB-D cameras. However, standard 3D sensors fail to capture depth of transparent objects due to refraction and absorption of light. In this paper, we introduce a new approach for depth completion of transparent objects from a single RGB-D image. Key to our approach is a local implicit neural representation built on ray-voxel pairs that allows our method to generalize to unseen objects and achieve fast inference speed. Based on this representation, we present a novel framework that can complete missing depth given noisy RGB-D input. We further improve the depth estimation iteratively using a self-correcting refinement model. To train the whole pipeline, we build a large scale synthetic dataset with transparent objects. Experiments demonstrate that our method performs significantly better than the current state-of-the-art methods on both synthetic and real world data. In addition, our approach improves the inference speed by a factor of 20 compared to the previous best method, ClearGrasp. Code and dataset will be released at https://research.nvidia.com/publication/2021-03_RGB-D-Local-Implicit.
Sim2SG: Sim-to-Real Scene Graph Generation for Transfer Learning
Nov 30, 2020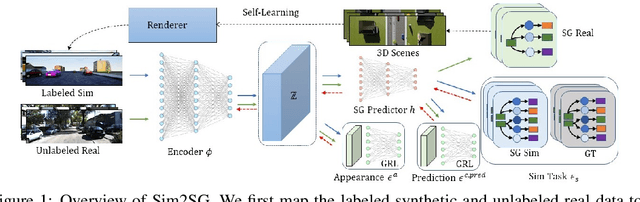

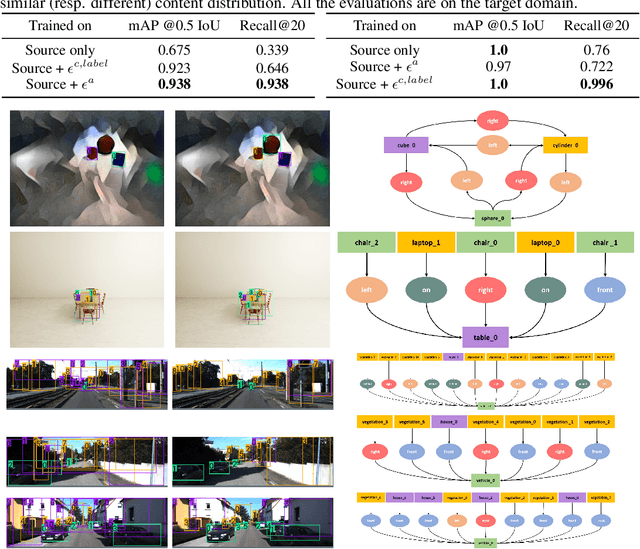
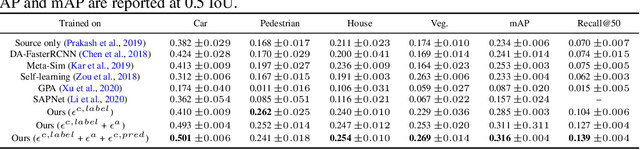
Scene graph (SG) generation has been gaining a lot of traction recently. Current SG generation techniques, however, rely on the availability of expensive and limited number of labeled datasets. Synthetic data offers a viable alternative as labels are essentially free. However, neural network models trained on synthetic data, do not perform well on real data because of the domain gap. To overcome this challenge, we propose Sim2SG, a scalable technique for sim-to-real transfer for scene graph generation. Sim2SG addresses the domain gap by decomposing it into appearance, label and prediction discrepancies between the two domains. We handle these discrepancies by introducing pseudo statistic based self-learning and adversarial techniques. Sim2SG does not require costly supervision from the real-world dataset. Our experiments demonstrate significant improvements over baselines in reducing the domain gap both qualitatively and quantitatively. We validate our approach on toy simulators, as well as realistic simulators evaluated on real-world data.
Accelerating Goal-Directed Reinforcement Learning by Model Characterization
Jan 04, 2019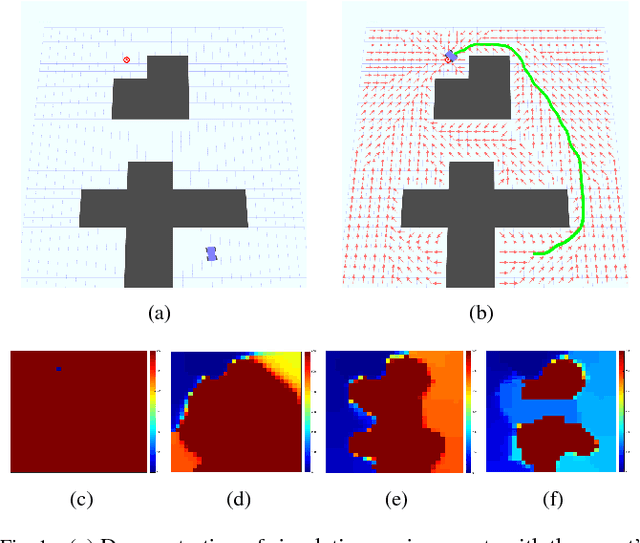
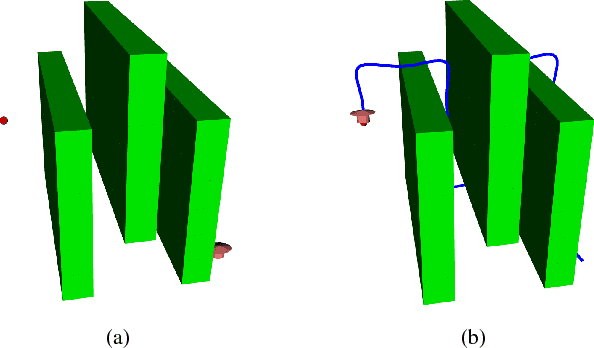
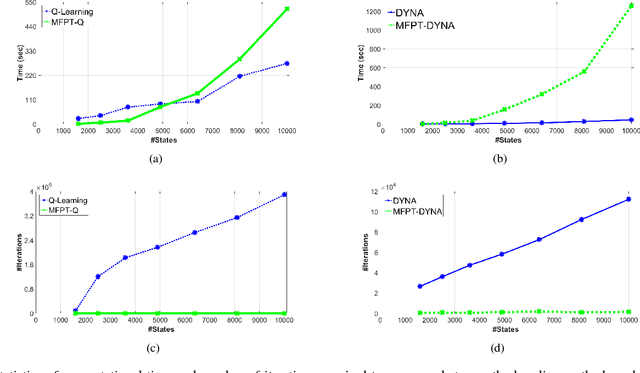
We propose a hybrid approach aimed at improving the sample efficiency in goal-directed reinforcement learning. We do this via a two-step mechanism where firstly, we approximate a model from Model-Free reinforcement learning. Then, we leverage this approximate model along with a notion of reachability using Mean First Passage Times to perform Model-Based reinforcement learning. Built on such a novel observation, we design two new algorithms - Mean First Passage Time based Q-Learning (MFPT-Q) and Mean First Passage Time based DYNA (MFPT-DYNA), that have been fundamentally modified from the state-of-the-art reinforcement learning techniques. Preliminary results have shown that our hybrid approaches converge with much fewer iterations than their corresponding state-of-the-art counterparts and therefore requiring much fewer samples and much fewer training trials to converge.
Solving Markov Decision Processes with Reachability Characterization from Mean First Passage Times
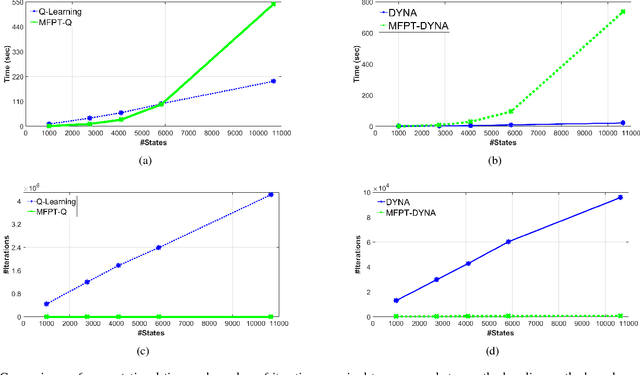
Jan 04, 2019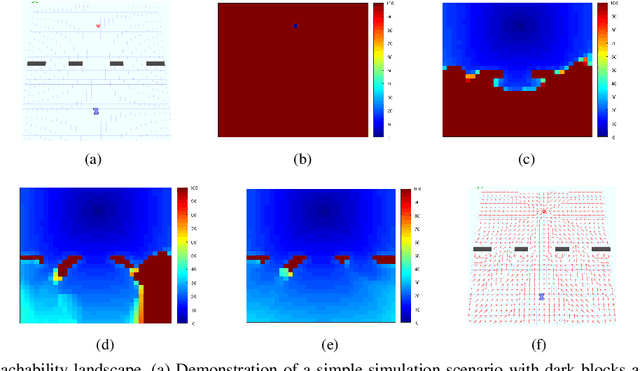
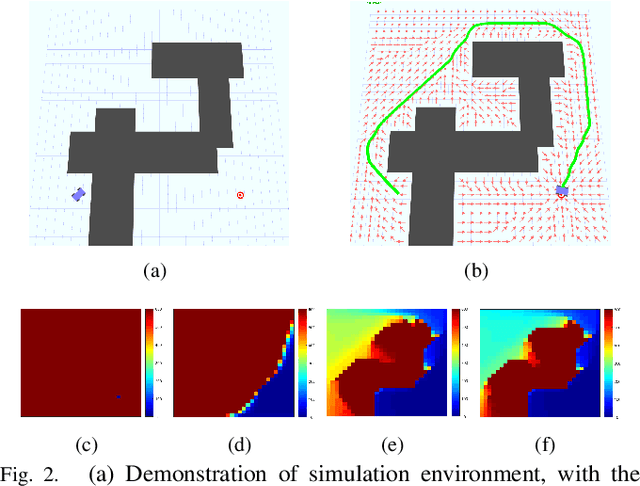
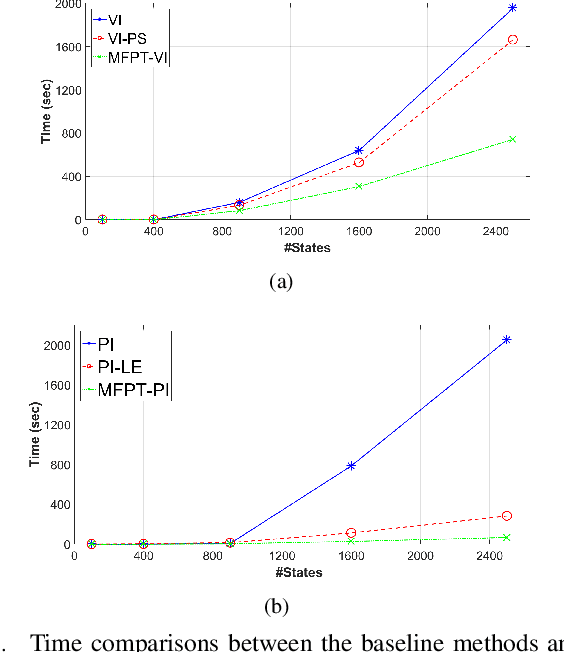
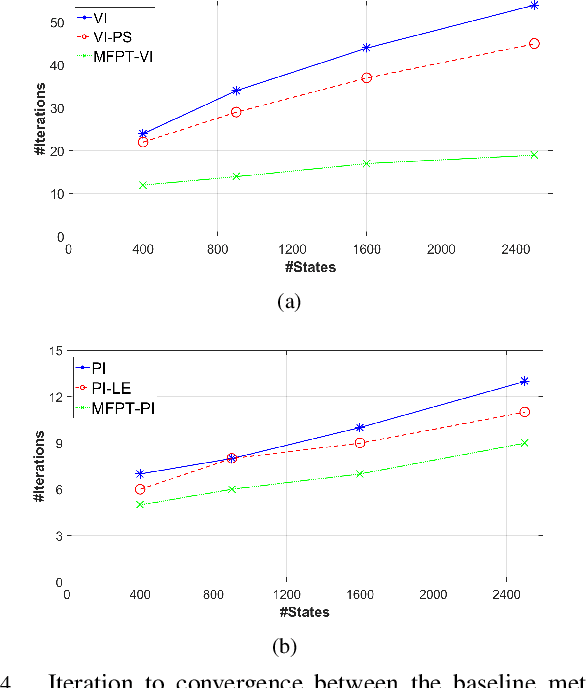
A new mechanism for efficiently solving the Markov decision processes (MDPs) is proposed in this paper. We introduce the notion of reachability landscape where we use the Mean First Passage Time (MFPT) as a means to characterize the reachability of every state in the state space. We show that such reachability characterization very well assesses the importance of states and thus provides a natural basis for effectively prioritizing states and approximating policies. Built on such a novel observation, we design two new algorithms -- Mean First Passage Time based Value Iteration (MFPT-VI) and Mean First Passage Time based Policy Iteration (MFPT-PI) -- that have been modified from the state-of-the-art solution methods. To validate our design, we have performed numerical evaluations in robotic decision-making scenarios, by comparing the proposed new methods with corresponding classic baseline mechanisms. The evaluation results showed that MFPT-VI and MFPT-PI have outperformed the state-of-the-art solutions in terms of both practical runtime and number of iterations. Aside from the advantage of fast convergence, this new solution method is intuitively easy to understand and practically simple to implement.
Reachability and Differential based Heuristics for Solving Markov Decision Processes
Jan 03, 2019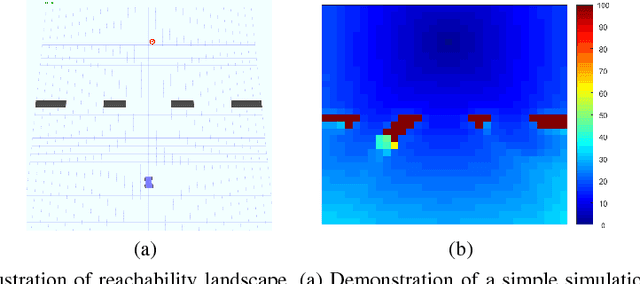
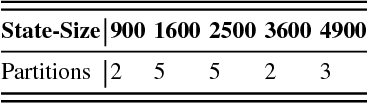
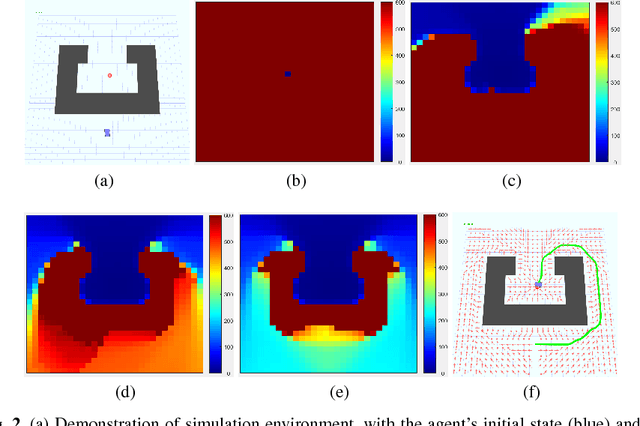
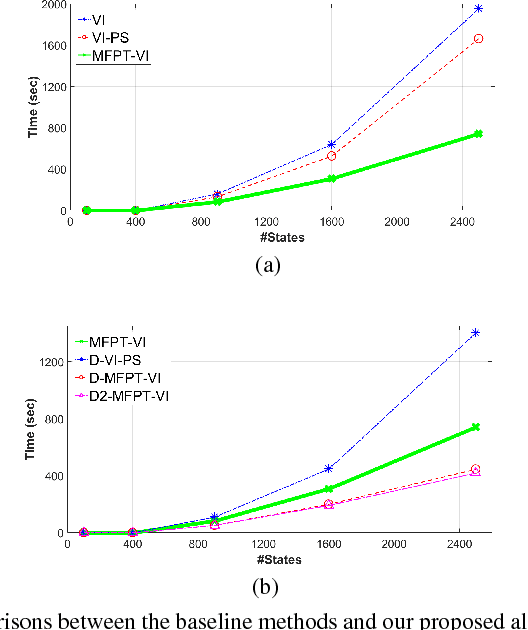
The solution convergence of Markov Decision Processes (MDPs) can be accelerated by prioritized sweeping of states ranked by their potential impacts to other states. In this paper, we present new heuristics to speed up the solution convergence of MDPs. First, we quantify the level of reachability of every state using the Mean First Passage Time (MFPT) and show that such reachability characterization very well assesses the importance of states which is used for effective state prioritization. Then, we introduce the notion of backup differentials as an extension to the prioritized sweeping mechanism, in order to evaluate the impacts of states at an even finer scale. Finally, we extend the state prioritization to the temporal process, where only partial sweeping can be performed during certain intermediate value iteration stages. To validate our design, we have performed numerical evaluations by comparing the proposed new heuristics with corresponding classic baseline mechanisms. The evaluation results showed that our reachability based framework and its differential variants have outperformed the state-of-the-art solutions in terms of both practical runtime and number of iterations.