 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Goal-Directed Reinforcement Learning by Model Characterization
Paper and Code
Jan 04, 2019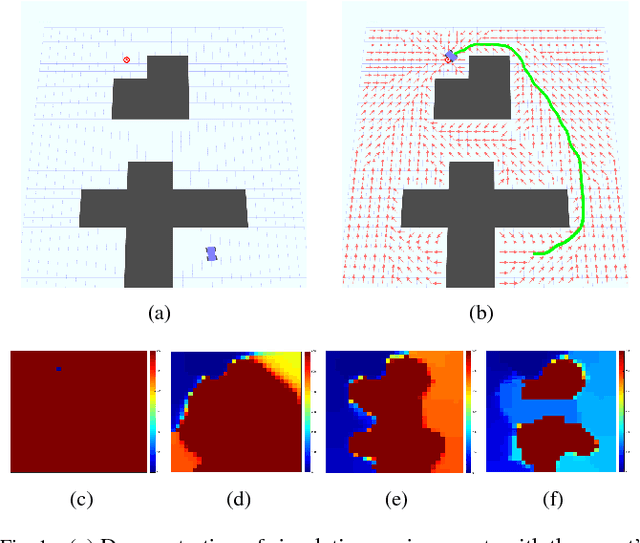
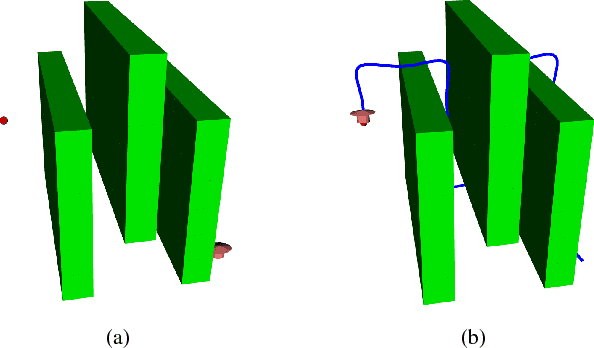
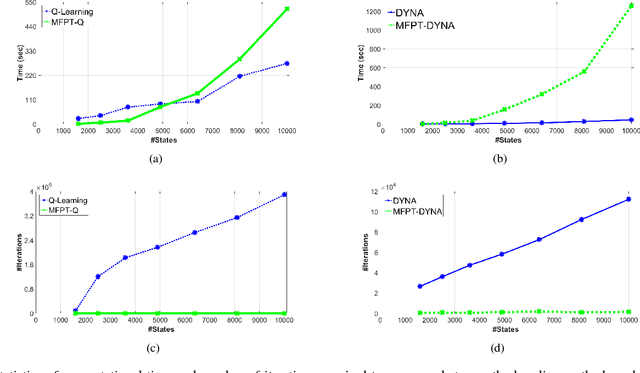
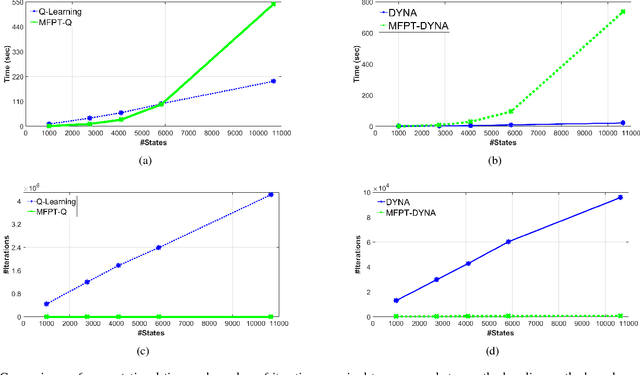
We propose a hybrid approach aimed at improving the sample efficiency in goal-directed reinforcement learning. We do this via a two-step mechanism where firstly, we approximate a model from Model-Free reinforcement learning. Then, we leverage this approximate model along with a notion of reachability using Mean First Passage Times to perform Model-Based reinforcement learning. Built on such a novel observation, we design two new algorithms - Mean First Passage Time based Q-Learning (MFPT-Q) and Mean First Passage Time based DYNA (MFPT-DYNA), that have been fundamentally modified from the state-of-the-art reinforcement learning techniques. Preliminary results have shown that our hybrid approaches converge with much fewer iterations than their corresponding state-of-the-art counterparts and therefore requiring much fewer samples and much fewer training trials to converge.