 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Markov Decision Processes with Reachability Characterization from Mean First Passage Times
Paper and Code
Jan 04, 2019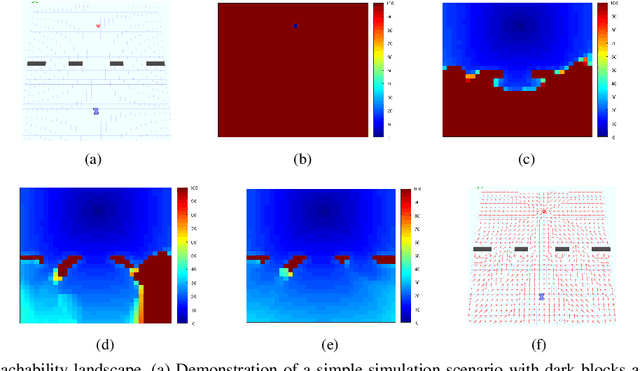
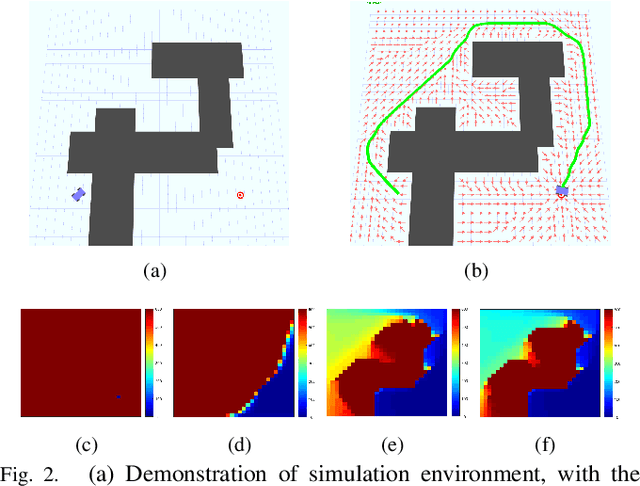
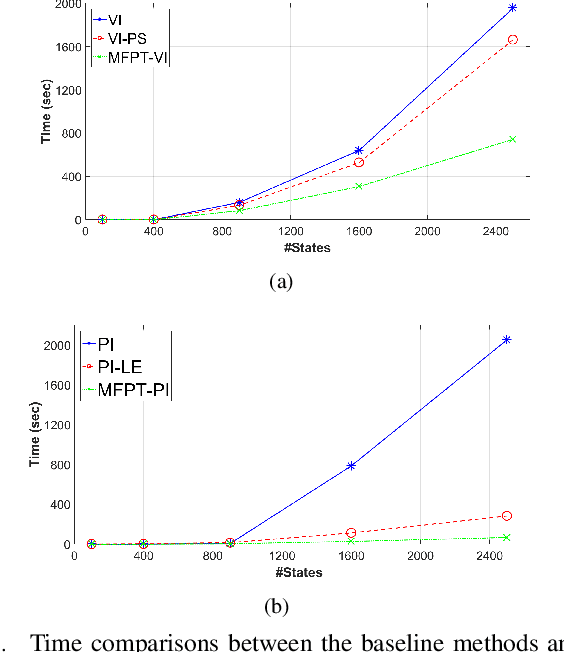
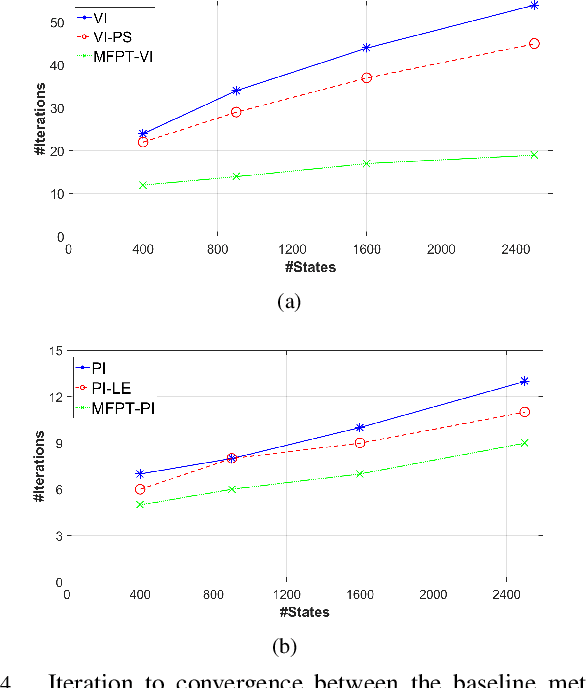
A new mechanism for efficiently solving the Markov decision processes (MDPs) is proposed in this paper. We introduce the notion of reachability landscape where we use the Mean First Passage Time (MFPT) as a means to characterize the reachability of every state in the state space. We show that such reachability characterization very well assesses the importance of states and thus provides a natural basis for effectively prioritizing states and approximating policies. Built on such a novel observation, we design two new algorithms -- Mean First Passage Time based Value Iteration (MFPT-VI) and Mean First Passage Time based Policy Iteration (MFPT-PI) -- that have been modified from the state-of-the-art solution methods. To validate our design, we have performed numerical evaluations in robotic decision-making scenarios, by comparing the proposed new methods with corresponding classic baseline mechanisms. The evaluation results showed that MFPT-VI and MFPT-PI have outperformed the state-of-the-art solutions in terms of both practical runtime and number of iterations. Aside from the advantage of fast convergence, this new solution method is intuitively easy to understand and practically simple to implement.