 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRI3D: Few-Shot Gaussian Splatting With Repair and Inpainting Diffusion Priors
Mar 13, 2025In this paper, we propose RI3D, a novel 3DGS-based approach that harnesses the power of diffusion models to reconstruct high-quality novel views given a sparse set of input images. Our key contribution is separating the view synthesis process into two tasks of reconstructing visible regions and hallucinating missing regions, and introducing two personalized diffusion models, each tailored to one of these tasks. Specifically, one model ('repair') takes a rendered image as input and predicts the corresponding high-quality image, which in turn is used as a pseudo ground truth image to constrain the optimization. The other model ('inpainting') primarily focuses on hallucinating details in unobserved areas. To integrate these models effectively, we introduce a two-stage optimization strategy: the first stage reconstructs visible areas using the repair model, and the second stage reconstructs missing regions with the inpainting model while ensuring coherence through further optimization. Moreover, we augment the optimization with a novel Gaussian initialization method that obtains per-image depth by combining 3D-consistent and smooth depth with highly detailed relative depth. We demonstrate that by separating the process into two tasks and addressing them with the repair and inpainting models, we produce results with detailed textures in both visible and missing regions that outperform state-of-the-art approaches on a diverse set of scenes with extremely sparse inputs.
Compressed Depth Map Super-Resolution and Restoration: AIM 2024 Challenge Results
Sep 24, 2024The increasing demand for augmented reality (AR) and virtual reality (VR) applications highlights the need for efficient depth information processing. Depth maps, essential for rendering realistic scenes and supporting advanced functionalities, are typically large and challenging to stream efficiently due to their size. This challenge introduces a focus on developing innovative depth upsampling techniques to reconstruct high-quality depth maps from compressed data. These techniques are crucial for overcoming the limitations posed by depth compression, which often degrades quality, loses scene details and introduces artifacts. By enhancing depth upsampling methods, this challenge aims to improve the efficiency and quality of depth map reconstruction. Our goal is to advance the state-of-the-art in depth processing technologies, thereby enhancing the overall user experience in AR and VR applications.
CoherentGS: Sparse Novel View Synthesis with Coherent 3D Gaussians
Mar 28, 2024The field of 3D reconstruction from images has rapidly evolved in the past few years, first with the introduction of Neural Radiance Field (NeRF) and more recently with 3D Gaussian Splatting (3DGS). The latter provides a significant edge over NeRF in terms of the training and inference speed, as well as the reconstruction quality. Although 3DGS works well for dense input images, the unstructured point-cloud like representation quickly overfits to the more challenging setup of extremely sparse input images (e.g., 3 images), creating a representation that appears as a jumble of needles from novel views. To address this issue, we propose regularized optimization and depth-based initialization. Our key idea is to introduce a structured Gaussian representation that can be controlled in 2D image space. We then constraint the Gaussians, in particular their position, and prevent them from moving independently during optimization. Specifically, we introduce single and multiview constraints through an implicit convolutional decoder and a total variation loss, respectively. With the coherency introduced to the Gaussians, we further constrain the optimization through a flow-based loss function. To support our regularized optimization, we propose an approach to initialize the Gaussians using monocular depth estimates at each input view. We demonstrate significant improvements compared to the state-of-the-art sparse-view NeRF-based approaches on a variety of scenes.
Consistent Direct Time-of-Flight Video Depth Super-Resolution
Nov 16, 2022



Direct time-of-flight (dToF) sensors are promising for next-generation on-device 3D sensing. However, to achieve the sufficient signal-to-noise-ratio (SNR) in a compact module, the dToF data has limited spatial resolution (e.g., ~20x30 for iPhone dToF), and it requires a super-resolution step before being passed to downstream tasks. In this paper, we solve this super-resolution problem by fusing the low-resolution dToF data with the corresponding high-resolution RGB guidance. Unlike the conventional RGB-guided depth enhancement approaches which perform the fusion in a per-frame manner, we propose the first multi-frame fusion scheme to mitigate the spatial ambiguity resulting from the low-resolution dToF imaging. In addition, dToF sensors provide unique depth histogram information for each local patch, and we incorporate this dToF-specific feature in our network design to further alleviate spatial ambiguity. To evaluate our models on complex dynamic indoor environments and to provide a large-scale dToF sensor dataset, we introduce DyDToF, the first synthetic RGB-dToF video dataset that features dynamic objects and a realistic dToF simulator following the physical imaging process. We believe the methods and dataset are beneficial to a broad community as dToF depth sensing is becoming mainstream on mobile devices.
Stochastic Convolutional Sparse Coding
Aug 31, 2019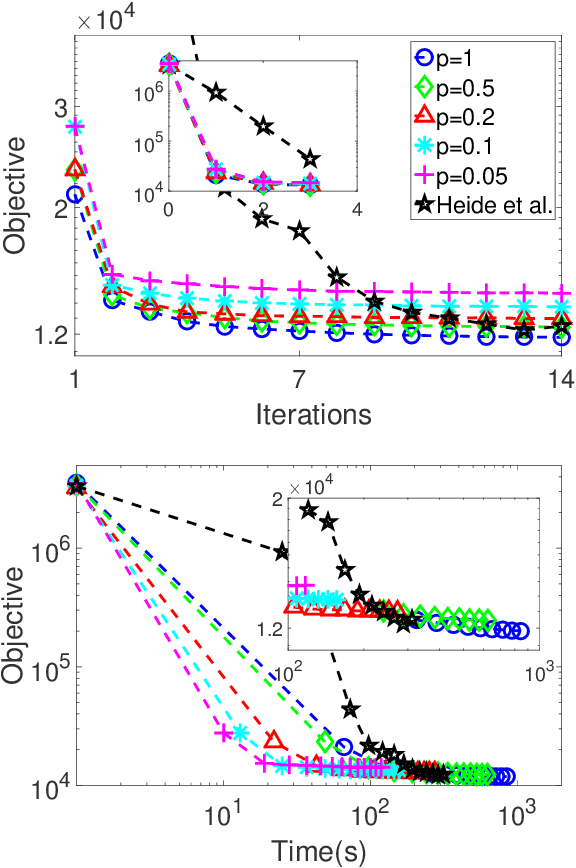
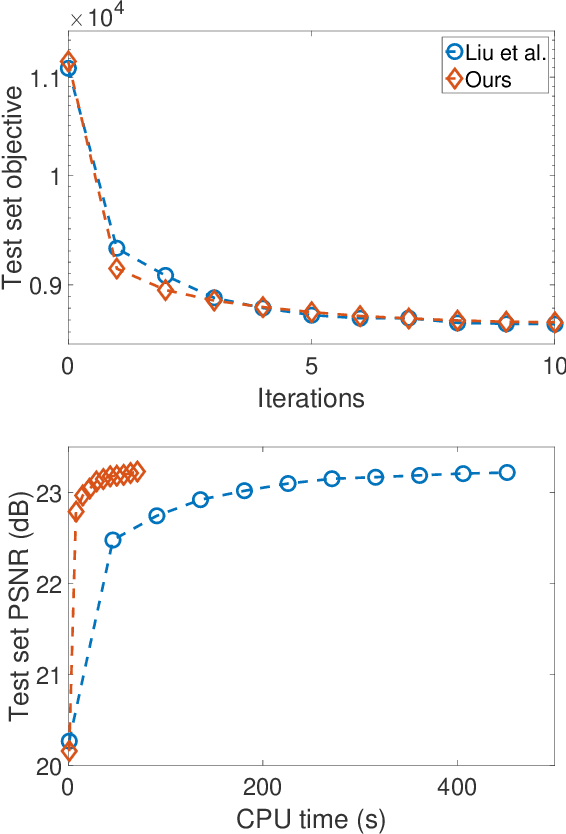
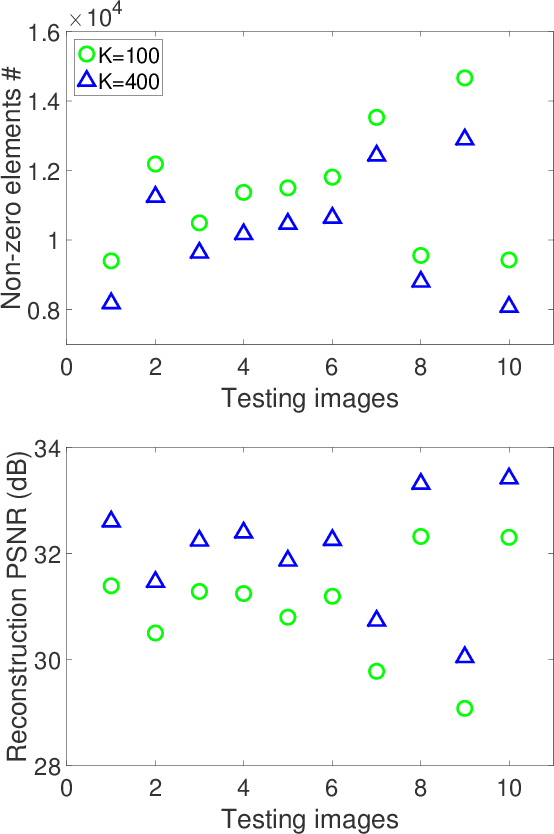

State-of-the-art methods for Convolutional Sparse Coding usually employ Fourier-domain solvers in order to speed up the convolution operators. However, this approach is not without shortcomings. For example, Fourier-domain representations implicitly assume circular boundary conditions and make it hard to fully exploit the sparsity of the problem as well as the small spatial support of the filters. In this work, we propose a novel stochastic spatial-domain solver, in which a randomized subsampling strategy is introduced during the learning sparse codes. Afterwards, we extend the proposed strategy in conjunction with online learning, scaling the CSC model up to very large sample sizes. In both cases, we show experimentally that the proposed subsampling strategy, with a reasonable selection of the subsampling rate, outperforms the state-of-the-art frequency-domain solvers in terms of execution time without losing the learning quality. Finally, we evaluate the effectiveness of the over-complete dictionary learned from large-scale datasets, which demonstrates an improved sparse representation of the natural images on account of more abundant learned image features.