 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientDepth: A Fast and Detail-Preserving Monocular Depth Estimation Model
Sep 26, 2025



Monocular depth estimation (MDE) plays a pivotal role in various computer vision applications, such as robotics, augmented reality, and autonomous driving. Despite recent advancements, existing methods often fail to meet key requirements for 3D reconstruction and view synthesis, including geometric consistency, fine details, robustness to real-world challenges like reflective surfaces, and efficiency for edge devices. To address these challenges, we introduce a novel MDE system, called EfficientDepth, which combines a transformer architecture with a lightweight convolutional decoder, as well as a bimodal density head that allows the network to estimate detailed depth maps. We train our model on a combination of labeled synthetic and real images, as well as pseudo-labeled real images, generated using a high-performing MDE method. Furthermore, we employ a multi-stage optimization strategy to improve training efficiency and produce models that emphasize geometric consistency and fine detail. Finally, in addition to commonly used objectives, we introduce a loss function based on LPIPS to encourage the network to produce detailed depth maps. Experimental results demonstrate that EfficientDepth achieves performance comparable to or better than existing state-of-the-art models, with significantly reduced computational resources.
PanoDreamer: 3D Panorama Synthesis from a Single Image
Dec 06, 2024



In this paper, we present PanoDreamer, a novel method for producing a coherent 360$^\circ$ 3D scene from a single input image. Unlike existing methods that generate the scene sequentially, we frame the problem as single-image panorama and depth estimation. Once the coherent panoramic image and its corresponding depth are obtained, the scene can be reconstructed by inpainting the small occluded regions and projecting them into 3D space. Our key contribution is formulating single-image panorama and depth estimation as two optimization tasks and introducing alternating minimization strategies to effectively solve their objectives. We demonstrate that our approach outperforms existing techniques in single-image 360$^\circ$ scene reconstruction in terms of consistency and overall quality.
ReShader: View-Dependent Highlights for Single Image View-Synthesis
Sep 19, 2023



In recent years, novel view synthesis from a single image has seen significant progress thanks to the rapid advancements in 3D scene representation and image inpainting techniques. While the current approaches are able to synthesize geometrically consistent novel views, they often do not handle the view-dependent effects properly. Specifically, the highlights in their synthesized images usually appear to be glued to the surfaces, making the novel views unrealistic. To address this major problem, we make a key observation that the process of synthesizing novel views requires changing the shading of the pixels based on the novel camera, and moving them to appropriate locations. Therefore, we propose to split the view synthesis process into two independent tasks of pixel reshading and relocation. During the reshading process, we take the single image as the input and adjust its shading based on the novel camera. This reshaded image is then used as the input to an existing view synthesis method to relocate the pixels and produce the final novel view image. We propose to use a neural network to perform reshading and generate a large set of synthetic input-reshaded pairs to train our network. We demonstrate that our approach produces plausible novel view images with realistic moving highlights on a variety of real world scenes.
Implicit View-Time Interpolation of Stereo Videos using Multi-Plane Disparities and Non-Uniform Coordinates
Mar 30, 2023


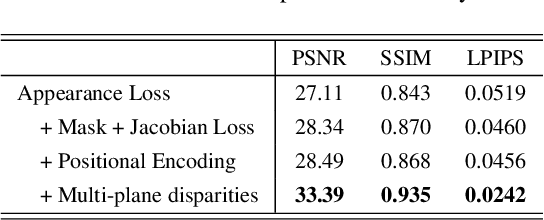
In this paper, we propose an approach for view-time interpolation of stereo videos. Specifically, we build upon X-Fields that approximates an interpolatable mapping between the input coordinates and 2D RGB images using a convolutional decoder. Our main contribution is to analyze and identify the sources of the problems with using X-Fields in our application and propose novel techniques to overcome these challenges. Specifically, we observe that X-Fields struggles to implicitly interpolate the disparities for large baseline cameras. Therefore, we propose multi-plane disparities to reduce the spatial distance of the objects in the stereo views. Moreover, we propose non-uniform time coordinates to handle the non-linear and sudden motion spikes in videos. We additionally introduce several simple, but important, improvements over X-Fields. We demonstrate that our approach is able to produce better results than the state of the art, while running in near real-time rates and having low memory and storage costs.