 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine-assisted writing evaluation: Exploring pre-trained language models in analyzing argumentative moves
Mar 25, 2025The study investigates the efficacy of pre-trained language models (PLMs) in analyzing argumentative moves in a longitudinal learner corpus. Prior studies on argumentative moves often rely on qualitative analysis and manual coding, limiting their efficiency and generalizability. The study aims to: 1) to assess the reliability of PLMs in analyzing argumentative moves; 2) to utilize PLM-generated annotations to illustrate developmental patterns and predict writing quality. A longitudinal corpus of 1643 argumentative texts from 235 English learners in China is collected and annotated into six move types: claim, data, counter-claim, counter-data, rebuttal, and non-argument. The corpus is divided into training, validation, and application sets annotated by human experts and PLMs. We use BERT as one of the implementations of PLMs. The results indicate a robust reliability of PLMs in analyzing argumentative moves, with an overall F1 score of 0.743, surpassing existing models in the field. Additionally, PLM-labeled argumentative moves effectively capture developmental patterns and predict writing quality. Over time, students exhibit an increase in the use of data and counter-claims and a decrease in non-argument moves. While low-quality texts are characterized by a predominant use of claims and data supporting only oneside position, mid- and high-quality texts demonstrate an integrative perspective with a higher ratio of counter-claims, counter-data, and rebuttals. This study underscores the transformative potential of integrating artificial intelligence into language education, enhancing the efficiency and accuracy of evaluating students' writing. The successful application of PLMs can catalyze the development of educational technology, promoting a more data-driven and personalized learning environment that supports diverse educational needs.
Advancing Translation Preference Modeling with RLHF: A Step Towards Cost-Effective Solution
Feb 27, 2024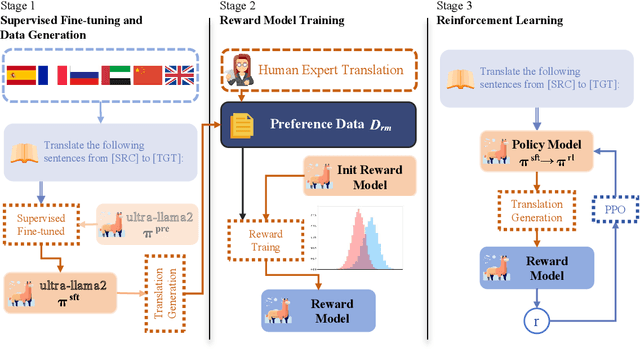

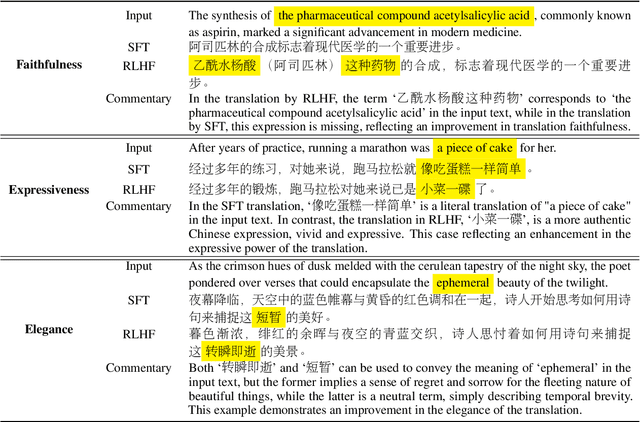
Faithfulness, expressiveness, and elegance is the constant pursuit in machine translation. However, traditional metrics like \textit{BLEU} do not strictly align with human preference of translation quality. In this paper, we explore leveraging reinforcement learning with human feedback (\textit{RLHF}) to improve translation quality. It is non-trivial to collect a large high-quality dataset of human comparisons between translations, especially for low-resource languages. To address this issue, we propose a cost-effective preference learning strategy, optimizing reward models by distinguishing between human and machine translations. In this manner, the reward model learns the deficiencies of machine translation compared to human and guides subsequent improvements in machine translation. Experimental results demonstrate that \textit{RLHF} can effectively enhance translation quality and this improvement benefits other translation directions not trained with \textit{RLHF}. Further analysis indicates that the model's language capabilities play a crucial role in preference learning. A reward model with strong language capabilities can more sensitively learn the subtle differences in translation quality and align better with real human translation preferences.
The Rise and Potential of Large Language Model Based Agents: A Survey
Sep 19, 2023



For a long time, humanity has pursued artificial intelligence (AI) equivalent to or surpassing the human level, with AI agents considered a promising vehicle for this pursuit. AI agents are artificial entities that sense their environment, make decisions, and take actions. Many efforts have been made to develop intelligent agents, but they mainly focus on advancement in algorithms or training strategies to enhance specific capabilities or performance on particular tasks. Actually, what the community lacks is a general and powerful model to serve as a starting point for designing AI agents that can adapt to diverse scenarios. Due to the versatile capabilities they demonstrate, large language models (LLMs) are regarded as potential sparks for Artificial General Intelligence (AGI), offering hope for building general AI agents. Many researchers have leveraged LLMs as the foundation to build AI agents and have achieved significant progress. In this paper, we perform a comprehensive survey on LLM-based agents. We start by tracing the concept of agents from its philosophical origins to its development in AI, and explain why LLMs are suitable foundations for agents. Building upon this, we present a general framework for LLM-based agents, comprising three main components: brain, perception, and action, and the framework can be tailored for different applications. Subsequently, we explore the extensive applications of LLM-based agents in three aspects: single-agent scenarios, multi-agent scenarios, and human-agent cooperation. Following this, we delve into agent societies, exploring the behavior and personality of LLM-based agents, the social phenomena that emerge from an agent society, and the insights they offer for human society. Finally, we discuss several key topics and open problems within the field. A repository for the related papers at https://github.com/WooooDyy/LLM-Agent-Paper-List.