 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Translation Preference Modeling with RLHF: A Step Towards Cost-Effective Solution
Paper and Code
Feb 27, 2024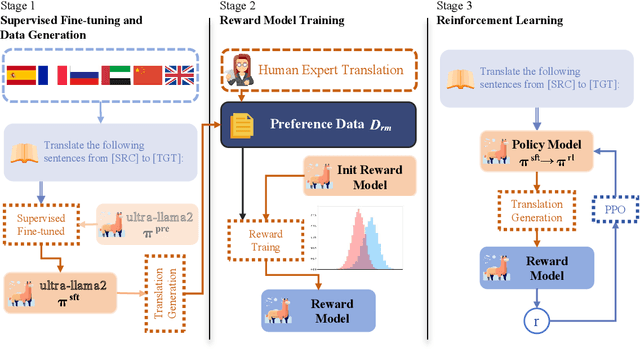

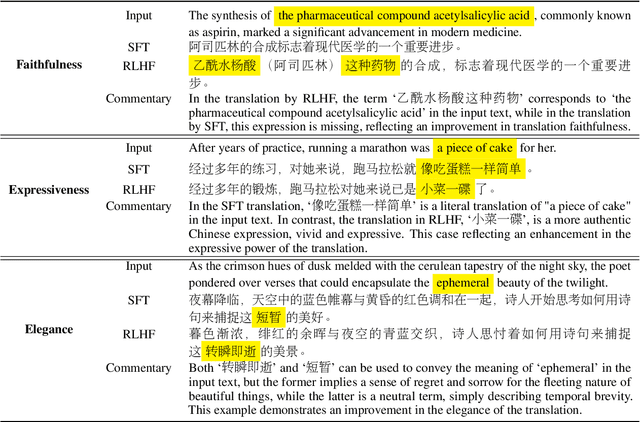
Faithfulness, expressiveness, and elegance is the constant pursuit in machine translation. However, traditional metrics like \textit{BLEU} do not strictly align with human preference of translation quality. In this paper, we explore leveraging reinforcement learning with human feedback (\textit{RLHF}) to improve translation quality. It is non-trivial to collect a large high-quality dataset of human comparisons between translations, especially for low-resource languages. To address this issue, we propose a cost-effective preference learning strategy, optimizing reward models by distinguishing between human and machine translations. In this manner, the reward model learns the deficiencies of machine translation compared to human and guides subsequent improvements in machine translation. Experimental results demonstrate that \textit{RLHF} can effectively enhance translation quality and this improvement benefits other translation directions not trained with \textit{RLHF}. Further analysis indicates that the model's language capabilities play a crucial role in preference learning. A reward model with strong language capabilities can more sensitively learn the subtle differences in translation quality and align better with real human translation preferences.