 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Specific Scaling of Positional Encodings for Superior Long-Context Modeling
Paper and Code
Mar 06, 2025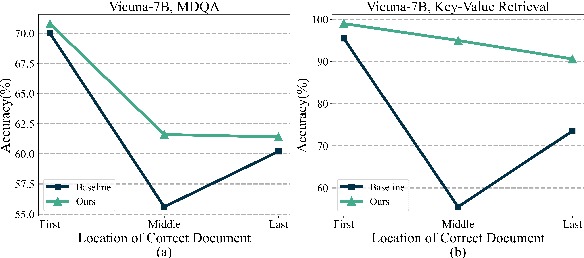



Although large language models (LLMs) have achieved significant progress in handling long-context inputs, they still suffer from the ``lost-in-the-middle'' problem, where crucial information in the middle of the context is often underrepresented or lost. Our extensive experiments reveal that this issue may arise from the rapid long-term decay in Rotary Position Embedding (RoPE). To address this problem, we propose a layer-specific positional encoding scaling method that assigns distinct scaling factors to each layer, slowing down the decay rate caused by RoPE to make the model pay more attention to the middle context. A specially designed genetic algorithm is employed to efficiently select the optimal scaling factors for each layer by incorporating Bezier curves to reduce the search space. Through comprehensive experimentation, we demonstrate that our method significantly alleviates the ``lost-in-the-middle'' problem. Our approach results in an average accuracy improvement of up to 20% on the Key-Value Retrieval dataset. Furthermore, we show that layer-specific interpolation, as opposed to uniform interpolation across all layers, enhances the model's extrapolation capabilities when combined with PI and Dynamic-NTK positional encoding schemes.