 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefInt: A Default-interventionist Framework for Efficient Reasoning with Hybrid Large Language Models
Paper and Code
Feb 04, 2024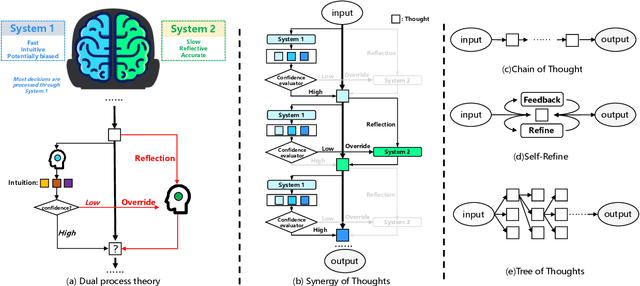
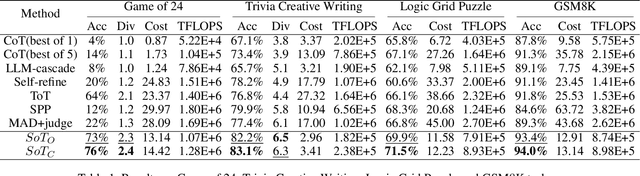
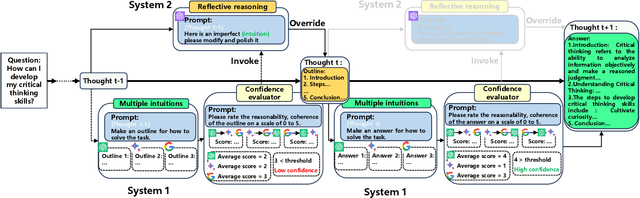
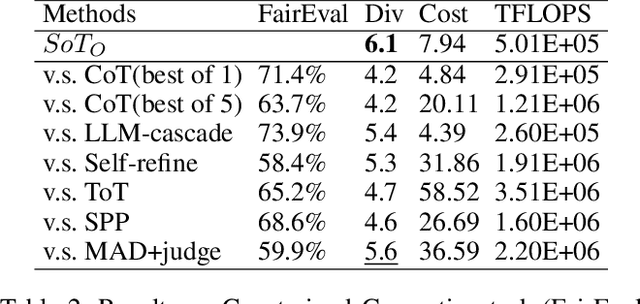
Large language models (LLMs) have shown impressive emergent abilities in a wide range of tasks, but still face challenges in handling complex reasoning problems. Previous works like chain-of-thought (CoT) and tree-of-thoughts(ToT) have predominately focused on enhancing accuracy, but overlook the rapidly increasing token cost, which could be particularly problematic for open-ended real-world tasks with huge solution spaces. Motivated by the dual process theory of human cognition, we propose a Default-Interventionist framework (DefInt) to unleash the synergistic potential of hybrid LLMs. By default, DefInt uses smaller-scale language models to generate low-cost reasoning thoughts, which resembles the fast intuitions produced by System 1. If the intuitions are considered with low confidence, DefInt will invoke the reflective reasoning of scaled-up language models as the intervention of System 2, which can override the default thoughts and rectify the reasoning process. Experiments on five representative reasoning tasks show that DefInt consistently achieves state-of-the-art reasoning accuracy and solution diversity. More importantly, it substantially reduces the token cost by 49%-79% compared to the second accurate baselines. Specifically, the open-ended tasks have an average 75% token cost reduction. Code repo with all prompts will be released upon publication.