 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Watermark for Low-entropy and Unbiased Generation in Large Language Models
Paper and Code
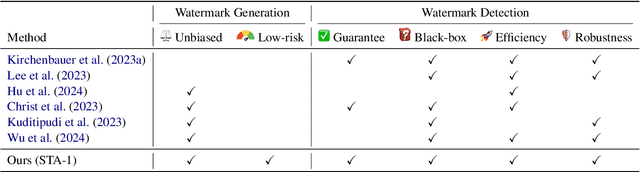
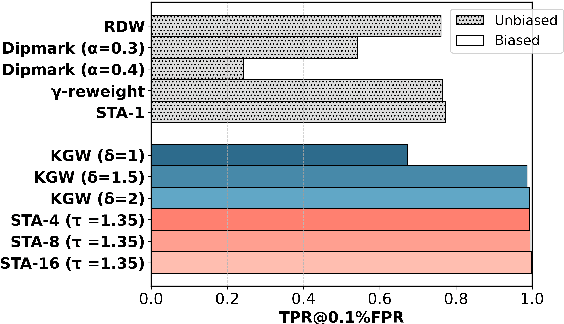
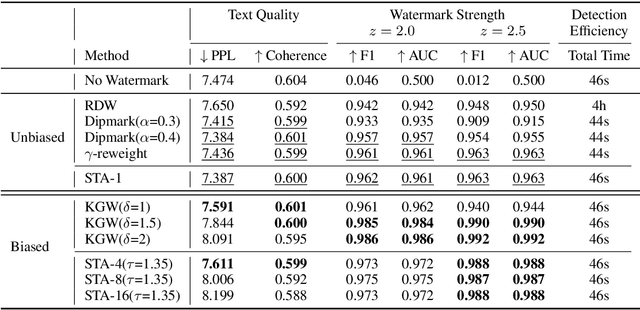
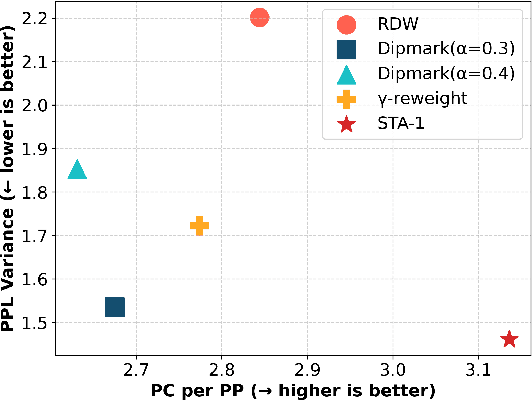
Recent advancements in large language models (LLMs) have highlighted the risk of misuse, raising concerns about accurately detecting LLM-generated content. A viable solution for the detection problem is to inject imperceptible identifiers into LLMs, known as watermarks. Previous work demonstrates that unbiased watermarks ensure unforgeability and preserve text quality by maintaining the expectation of the LLM output probability distribution. However, previous unbiased watermarking methods are impractical for local deployment because they rely on accesses to white-box LLMs and input prompts during detection. Moreover, these methods fail to provide statistical guarantees for the type II error of watermark detection. This study proposes the Sampling One Then Accepting (STA-1) method, an unbiased watermark that does not require access to LLMs nor prompts during detection and has statistical guarantees for the type II error. Moreover, we propose a novel tradeoff between watermark strength and text quality in unbiased watermarks. We show that in low-entropy scenarios, unbiased watermarks face a tradeoff between watermark strength and the risk of unsatisfactory outputs. Experimental results on low-entropy and high-entropy datasets demonstrate that STA-1 achieves text quality and watermark strength comparable to existing unbiased watermarks, with a low risk of unsatisfactory outputs. Implementation codes for this study are available online.