 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Stopping Chain-of-thoughts in Large Language Models
Sep 17, 2025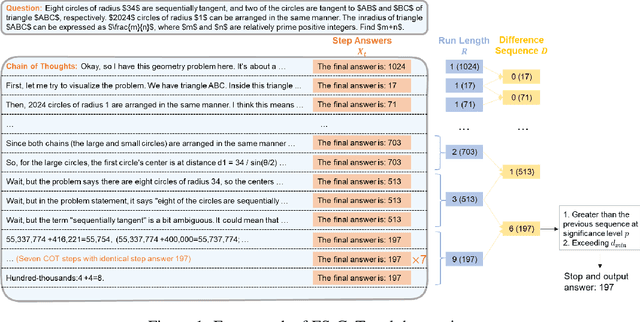
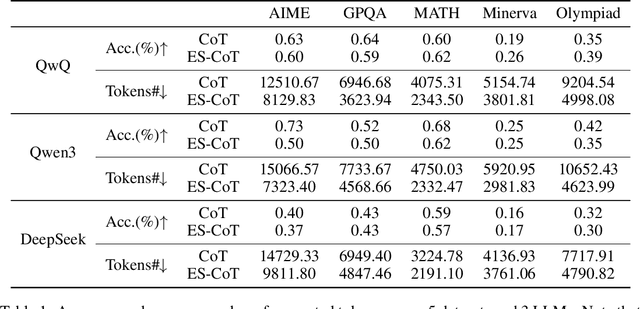
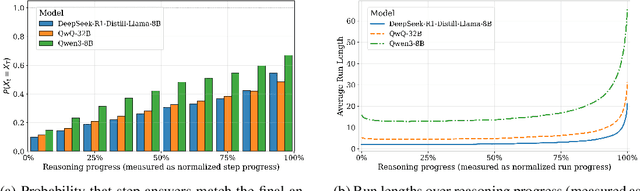
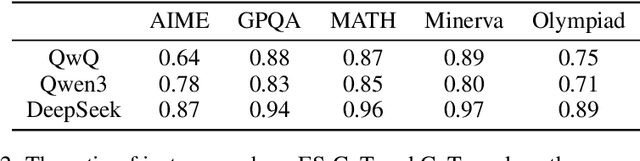
Reasoning large language models (LLMs) have demonstrated superior capacities in solving complicated problems by generating long chain-of-thoughts (CoT), but such a lengthy CoT incurs high inference costs. In this study, we introduce ES-CoT, an inference-time method that shortens CoT generation by detecting answer convergence and stopping early with minimal performance loss. At the end of each reasoning step, we prompt the LLM to output its current final answer, denoted as a step answer. We then track the run length of consecutive identical step answers as a measure of answer convergence. Once the run length exhibits a sharp increase and exceeds a minimum threshold, the generation is terminated. We provide both empirical and theoretical support for this heuristic: step answers steadily converge to the final answer, and large run-length jumps reliably mark this convergence. Experiments on five reasoning datasets across three LLMs show that ES-CoT reduces the number of inference tokens by about 41\% on average while maintaining accuracy comparable to standard CoT. Further, ES-CoT integrates seamlessly with self-consistency prompting and remains robust across hyperparameter choices, highlighting it as a practical and effective approach for efficient reasoning.
A Watermark for Low-entropy and Unbiased Generation in Large Language Models
May 23, 2024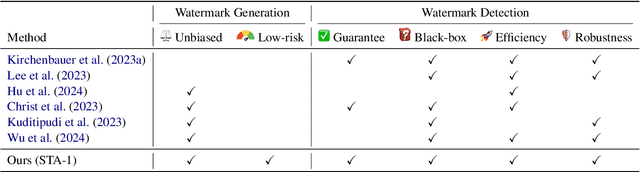
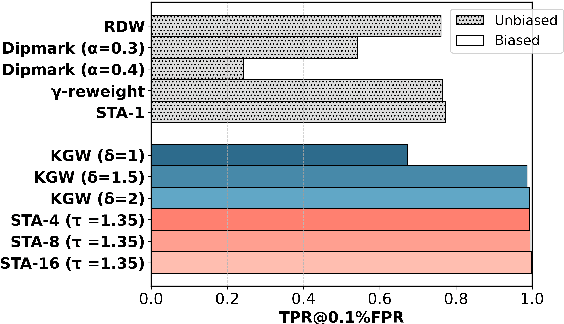
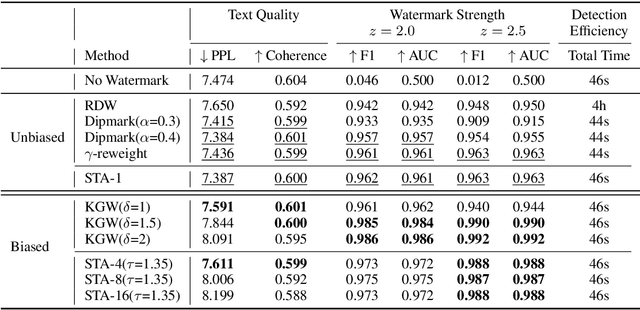
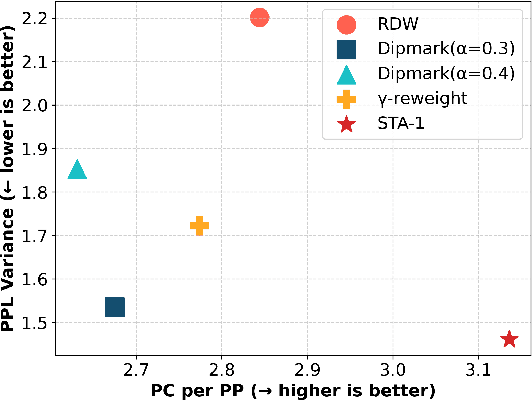
Recent advancements in large language models (LLMs) have highlighted the risk of misuse, raising concerns about accurately detecting LLM-generated content. A viable solution for the detection problem is to inject imperceptible identifiers into LLMs, known as watermarks. Previous work demonstrates that unbiased watermarks ensure unforgeability and preserve text quality by maintaining the expectation of the LLM output probability distribution. However, previous unbiased watermarking methods are impractical for local deployment because they rely on accesses to white-box LLMs and input prompts during detection. Moreover, these methods fail to provide statistical guarantees for the type II error of watermark detection. This study proposes the Sampling One Then Accepting (STA-1) method, an unbiased watermark that does not require access to LLMs nor prompts during detection and has statistical guarantees for the type II error. Moreover, we propose a novel tradeoff between watermark strength and text quality in unbiased watermarks. We show that in low-entropy scenarios, unbiased watermarks face a tradeoff between watermark strength and the risk of unsatisfactory outputs. Experimental results on low-entropy and high-entropy datasets demonstrate that STA-1 achieves text quality and watermark strength comparable to existing unbiased watermarks, with a low risk of unsatisfactory outputs. Implementation codes for this study are available online.
Bias of AI-Generated Content: An Examination of News Produced by Large Language Models
Sep 19, 2023Large language models (LLMs) have the potential to transform our lives and work through the content they generate, known as AI-Generated Content (AIGC). To harness this transformation, we need to understand the limitations of LLMs. Here, we investigate the bias of AIGC produced by seven representative LLMs, including ChatGPT and LLaMA. We collect news articles from The New York Times and Reuters, both known for their dedication to provide unbiased news. We then apply each examined LLM to generate news content with headlines of these news articles as prompts, and evaluate the gender and racial biases of the AIGC produced by the LLM by comparing the AIGC and the original news articles. We further analyze the gender bias of each LLM under biased prompts by adding gender-biased messages to prompts constructed from these news headlines. Our study reveals that the AIGC produced by each examined LLM demonstrates substantial gender and racial biases. Moreover, the AIGC generated by each LLM exhibits notable discrimination against females and individuals of the Black race. Among the LLMs, the AIGC generated by ChatGPT demonstrates the lowest level of bias, and ChatGPT is the sole model capable of declining content generation when provided with biased prompts.