 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias of AI-Generated Content: An Examination of News Produced by Large Language Models
Sep 19, 2023Large language models (LLMs) have the potential to transform our lives and work through the content they generate, known as AI-Generated Content (AIGC). To harness this transformation, we need to understand the limitations of LLMs. Here, we investigate the bias of AIGC produced by seven representative LLMs, including ChatGPT and LLaMA. We collect news articles from The New York Times and Reuters, both known for their dedication to provide unbiased news. We then apply each examined LLM to generate news content with headlines of these news articles as prompts, and evaluate the gender and racial biases of the AIGC produced by the LLM by comparing the AIGC and the original news articles. We further analyze the gender bias of each LLM under biased prompts by adding gender-biased messages to prompts constructed from these news headlines. Our study reveals that the AIGC produced by each examined LLM demonstrates substantial gender and racial biases. Moreover, the AIGC generated by each LLM exhibits notable discrimination against females and individuals of the Black race. Among the LLMs, the AIGC generated by ChatGPT demonstrates the lowest level of bias, and ChatGPT is the sole model capable of declining content generation when provided with biased prompts.
Proactive Resource Request for Disaster Response: A Deep Learning-based Optimization Model
Jul 31, 2023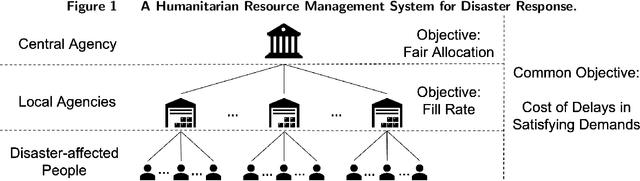

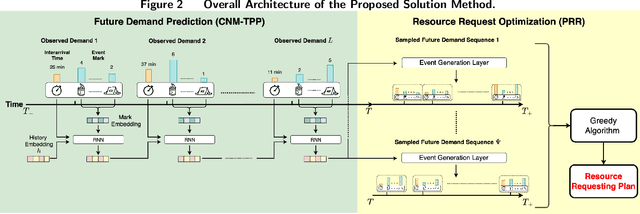
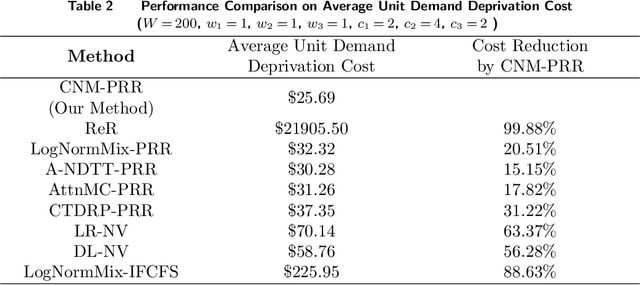
Disaster response is critical to save lives and reduce damages in the aftermath of a disaster. Fundamental to disaster response operations is the management of disaster relief resources. To this end, a local agency (e.g., a local emergency resource distribution center) collects demands from local communities affected by a disaster, dispatches available resources to meet the demands, and requests more resources from a central emergency management agency (e.g., Federal Emergency Management Agency in the U.S.). Prior resource management research for disaster response overlooks the problem of deciding optimal quantities of resources requested by a local agency. In response to this research gap, we define a new resource management problem that proactively decides optimal quantities of requested resources by considering both currently unfulfilled demands and future demands. To solve the problem, we take salient characteristics of the problem into consideration and develop a novel deep learning method for future demand prediction. We then formulate the problem as a stochastic optimization model, analyze key properties of the model, and propose an effective solution method to the problem based on the analyzed properties. We demonstrate the superior performance of our method over prevalent existing methods using both real world and simulated data. We also show its superiority over prevalent existing methods in a multi-stakeholder and multi-objective setting through simulations.
Care for the Mind Amid Chronic Diseases: An Interpretable AI Approach Using IoT
Nov 08, 2022



Health sensing for chronic disease management creates immense benefits for social welfare. Existing health sensing studies primarily focus on the prediction of physical chronic diseases. Depression, a widespread complication of chronic diseases, is however understudied. We draw on the medical literature to support depression prediction using motion sensor data. To connect human expertise in the decision-making, safeguard trust for this high-stake prediction, and ensure algorithm transparency, we develop an interpretable deep learning model: Temporal Prototype Network (TempPNet). TempPNet is built upon the emergent prototype learning models. To accommodate the temporal characteristic of sensor data and the progressive property of depression, TempPNet differs from existing prototype learning models in its capability of capturing the temporal progression of depression. Extensive empirical analyses using real-world motion sensor data show that TempPNet outperforms state-of-the-art benchmarks in depression prediction. Moreover, TempPNet interprets its predictions by visualizing the temporal progression of depression and its corresponding symptoms detected from sensor data. We further conduct a user study to demonstrate its superiority over the benchmarks in interpretability. This study offers an algorithmic solution for impactful social good - collaborative care of chronic diseases and depression in health sensing. Methodologically, it contributes to extant literature with a novel interpretable deep learning model for depression prediction from sensor data. Patients, doctors, and caregivers can deploy our model on mobile devices to monitor patients' depression risks in real-time. Our model's interpretability also allows human experts to participate in the decision-making by reviewing the interpretation of prediction outcomes and making informed interventions.
Exploiting Expert Knowledge for Assigning Firms to Industries: A Novel Deep Learning Method
Sep 11, 2022



Industry assignment, which assigns firms to industries according to a predefined Industry Classification System (ICS), is fundamental to a large number of critical business practices, ranging from operations and strategic decision making by firms to economic analyses by government agencies. Three types of expert knowledge are essential to effective industry assignment: definition-based knowledge (i.e., expert definitions of each industry), structure-based knowledge (i.e., structural relationships among industries as specified in an ICS), and assignment-based knowledge (i.e., prior firm-industry assignments performed by domain experts). Existing industry assignment methods utilize only assignment-based knowledge to learn a model that classifies unassigned firms to industries, and overlook definition-based and structure-based knowledge. Moreover, these methods only consider which industry a firm has been assigned to, but ignore the time-specificity of assignment-based knowledge, i.e., when the assignment occurs. To address the limitations of existing methods, we propose a novel deep learning-based method that not only seamlessly integrates the three types of knowledge for industry assignment but also takes the time-specificity of assignment-based knowledge into account. Methodologically, our method features two innovations: dynamic industry representation and hierarchical assignment. The former represents an industry as a sequence of time-specific vectors by integrating the three types of knowledge through our proposed temporal and spatial aggregation mechanisms. The latter takes industry and firm representations as inputs, computes the probability of assigning a firm to different industries, and assigns the firm to the industry with the highest probability.