 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiMu: Hierarchical Multimodal Frame Selection for Long Video Question Answering
Mar 19, 2026Long-form video question answering requires reasoning over extended temporal contexts, making frame selection critical for large vision-language models (LVLMs) bound by finite context windows. Existing methods face a sharp trade-off: similarity-based selectors are fast but collapse compositional queries into a single dense vector, losing sub-event ordering and cross-modal bindings; agent-based methods recover this structure through iterative LVLM inference, but at prohibitive cost. We introduce HiMu, a training-free framework that bridges this gap. A single text-only LLM call decomposes the query into a hierarchical logic tree whose leaves are atomic predicates, each routed to a lightweight expert spanning vision (CLIP, open-vocabulary detection, OCR) and audio (ASR, CLAP). The resulting signals are normalized, temporally smoothed to align different modalities, and composed bottom-up through fuzzy-logic operators that enforce temporal sequencing and adjacency, producing a continuous satisfaction curve. Evaluations on Video-MME, LongVideoBench and HERBench-Lite show that HiMu advances the efficiency-accuracy Pareto front: at 16 frames with Qwen3-VL 8B it outperforms all competing selectors, and with GPT-4o it surpasses agentic systems operating at 32-512 frames while requiring roughly 10x fewer FLOPs.
Distributed Learning in Markovian Restless Bandits over Interference Graphs for Stable Spectrum Sharing
Dec 19, 2025



We study distributed learning for spectrum access and sharing among multiple cognitive communication entities, such as cells, subnetworks, or cognitive radio users (collectively referred to as cells), in communication-constrained wireless networks modeled by interference graphs. Our goal is to achieve a globally stable and interference-aware channel allocation. Stability is defined through a generalized Gale-Shapley multi-to-one matching, a well-established solution concept in wireless resource allocation. We consider wireless networks where L cells share S orthogonal channels and cannot simultaneously use the same channel as their neighbors. Each channel evolves as an unknown restless Markov process with cell-dependent rewards, making this the first work to establish global Gale-Shapley stability for channel allocation in a stochastic, temporally varying restless environment. To address this challenge, we develop SMILE (Stable Multi-matching with Interference-aware LEarning), a communication-efficient distributed learning algorithm that integrates restless bandit learning with graph-constrained coordination. SMILE enables cells to distributedly balance exploration of unknown channels with exploitation of learned information. We prove that SMILE converges to the optimal stable allocation and achieves logarithmic regret relative to a genie with full knowledge of expected utilities. Simulations validate the theoretical guarantees and demonstrate SMILE's robustness, scalability, and efficiency across diverse spectrum-sharing scenarios.
HERBench: A Benchmark for Multi-Evidence Integration in Video Question Answering
Dec 16, 2025



Video Large Language Models (Video-LLMs) are rapidly improving, yet current Video Question Answering (VideoQA) benchmarks often allow questions to be answered from a single salient cue, under-testing reasoning that must aggregate multiple, temporally separated visual evidence. We present HERBench, a VideoQA benchmark purpose-built to assess multi-evidence integration across time. Each question requires aggregating at least three non-overlapping evidential cues across distinct video segments, so neither language priors nor a single snapshot can suffice. HERBench comprises 26K five-way multiple-choice questions organized into twelve compositional tasks that probe identity binding, cross-entity relations, temporal ordering, co-occurrence verification, and counting. To make evidential demand measurable, we introduce the Minimum Required Frame-Set (MRFS), the smallest number of frames a model must fuse to answer correctly, and show that HERBench imposes substantially higher demand than prior datasets (mean MRFS 5.5 vs. 2.6-4.2). Evaluating 13 state-of-the-art Video-LLMs on HERBench reveals pervasive failures: accuracies of 31-42% are only slightly above the 20% random-guess baseline. We disentangle this failure into two critical bottlenecks: (1) a retrieval deficit, where frame selectors overlook key evidence, and (2) a fusion deficit, where models fail to integrate information even when all necessary evidence is provided. By making cross-time evidence both unavoidable and quantifiable, HERBench establishes a principled target for advancing robust, compositional video understanding.
PAUSE: Low-Latency and Privacy-Aware Active User Selection for Federated Learning
Mar 17, 2025Federated learning (FL) enables multiple edge devices to collaboratively train a machine learning model without the need to share potentially private data. Federated learning proceeds through iterative exchanges of model updates, which pose two key challenges: First, the accumulation of privacy leakage over time, and second, communication latency. These two limitations are typically addressed separately: The former via perturbed updates to enhance privacy and the latter using user selection to mitigate latency - both at the expense of accuracy. In this work, we propose a method that jointly addresses the accumulation of privacy leakage and communication latency via active user selection, aiming to improve the trade-off among privacy, latency, and model performance. To achieve this, we construct a reward function that accounts for these three objectives. Building on this reward, we propose a multi-armed bandit (MAB)-based algorithm, termed Privacy-aware Active User SElection (PAUSE) which dynamically selects a subset of users each round while ensuring bounded overall privacy leakage. We establish a theoretical analysis, systematically showing that the reward growth rate of PAUSE follows that of the best-known rate in MAB literature. To address the complexity overhead of active user selection, we propose a simulated annealing-based relaxation of PAUSE and analyze its ability to approximate the reward-maximizing policy under reduced complexity. We numerically validate the privacy leakage, associated improved latency, and accuracy gains of our methods for the federated training in various scenarios.
Asymptotically Optimal Search for a Change Point Anomaly under a Composite Hypothesis Model
Dec 27, 2024



We address the problem of searching for a change point in an anomalous process among a finite set of M processes. Specifically, we address a composite hypothesis model in which each process generates measurements following a common distribution with an unknown parameter (vector). This parameter belongs to either a normal or abnormal space depending on the current state of the process. Before the change point, all processes, including the anomalous one, are in a normal state; after the change point, the anomalous process transitions to an abnormal state. Our goal is to design a sequential search strategy that minimizes the Bayes risk by balancing sample complexity and detection accuracy. We propose a deterministic search algorithm with the following notable properties. First, we analytically demonstrate that when the distributions of both normal and abnormal processes are unknown, the algorithm is asymptotically optimal in minimizing the Bayes risk as the error probability approaches zero. In the second setting, where the parameter under the null hypothesis is known, the algorithm achieves asymptotic optimality with improved detection time based on the true normal state. Simulation results are presented to validate the theoretical findings.
SINR-Aware Deep Reinforcement Learning for Distributed Dynamic Channel Allocation in Cognitive Interference Networks
Feb 17, 2024



We consider the problem of dynamic channel allocation (DCA) in cognitive communication networks with the goal of maximizing a global signal-to-interference-plus-noise ratio (SINR) measure under a specified target quality of service (QoS)-SINR for each network. The shared bandwidth is partitioned into K channels with frequency separation. In contrast to the majority of existing studies that assume perfect orthogonality or a one- to-one user-channel allocation mapping, this paper focuses on real-world systems experiencing inter-carrier interference (ICI) and channel reuse by multiple large-scale networks. This realistic scenario significantly increases the problem dimension, rendering existing algorithms inefficient. We propose a novel multi-agent reinforcement learning (RL) framework for distributed DCA, named Channel Allocation RL To Overlapped Networks (CARLTON). The CARLTON framework is based on the Centralized Training with Decentralized Execution (CTDE) paradigm, utilizing the DeepMellow value-based RL algorithm. To ensure robust performance in the interference-laden environment we address, CARLTON employs a low-dimensional representation of observations, generating a QoS-type measure while maximizing a global SINR measure and ensuring the target QoS-SINR for each network. Our results demonstrate exceptional performance and robust generalization, showcasing superior efficiency compared to alternative state-of-the-art methods, while achieving a marginally diminished performance relative to a fully centralized approach.
Sparse Training for Federated Learning with Regularized Error Correction
Dec 21, 2023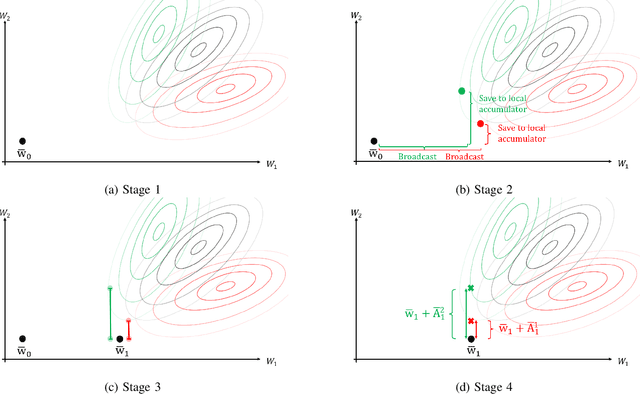
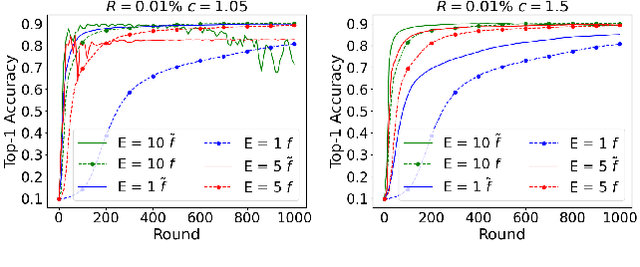
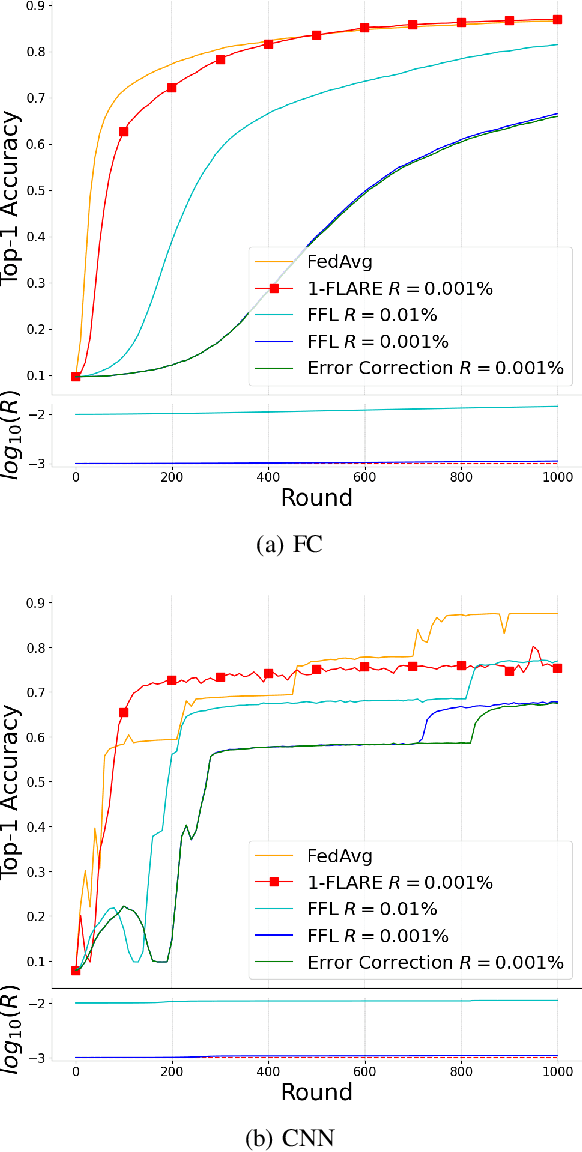
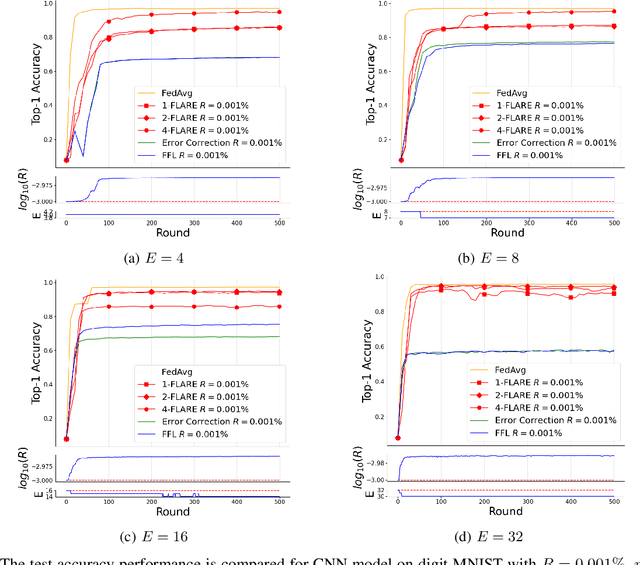
Federated Learning (FL) has attracted much interest due to the significant advantages it brings to training deep neural network (DNN) models. However, since communications and computation resources are limited, training DNN models in FL systems face challenges such as elevated computational and communication costs in complex tasks. Sparse training schemes gain increasing attention in order to scale down the dimensionality of each client (i.e., node) transmission. Specifically, sparsification with error correction methods is a promising technique, where only important updates are sent to the parameter server (PS) and the rest are accumulated locally. While error correction methods have shown to achieve a significant sparsification level of the client-to-PS message without harming convergence, pushing sparsity further remains unresolved due to the staleness effect. In this paper, we propose a novel algorithm, dubbed Federated Learning with Accumulated Regularized Embeddings (FLARE), to overcome this challenge. FLARE presents a novel sparse training approach via accumulated pulling of the updated models with regularization on the embeddings in the FL process, providing a powerful solution to the staleness effect, and pushing sparsity to an exceptional level. The performance of FLARE is validated through extensive experiments on diverse and complex models, achieving a remarkable sparsity level (10 times and more beyond the current state-of-the-art) along with significantly improved accuracy. Additionally, an open-source software package has been developed for the benefit of researchers and developers in related fields.
A Masked Pruning Approach for Dimensionality Reduction in Communication-Efficient Federated Learning Systems
Dec 06, 2023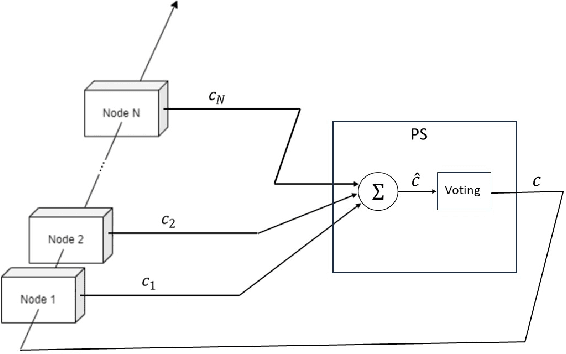
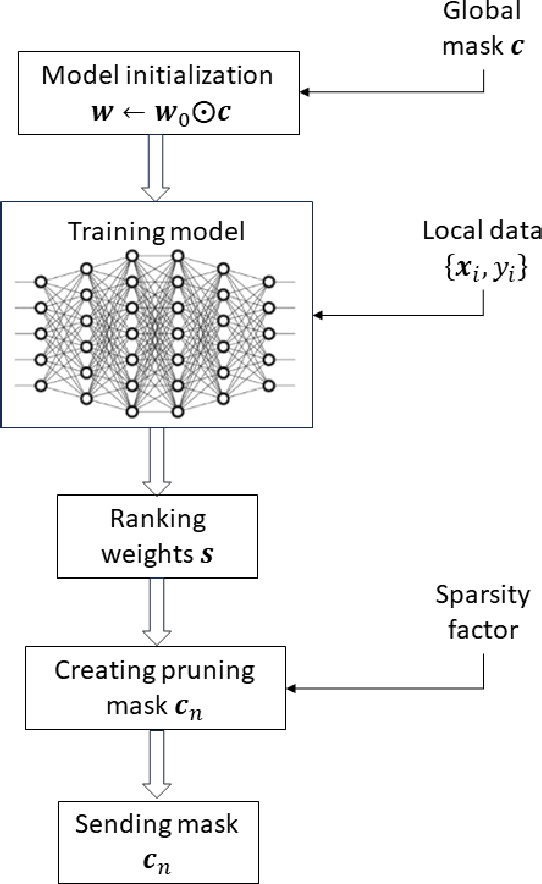
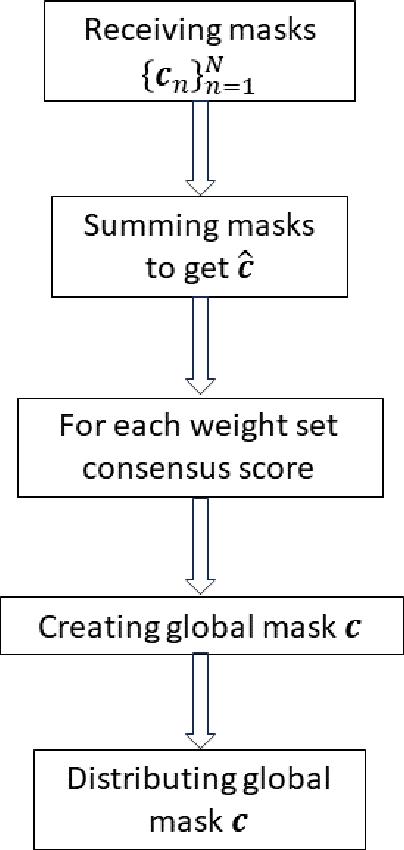
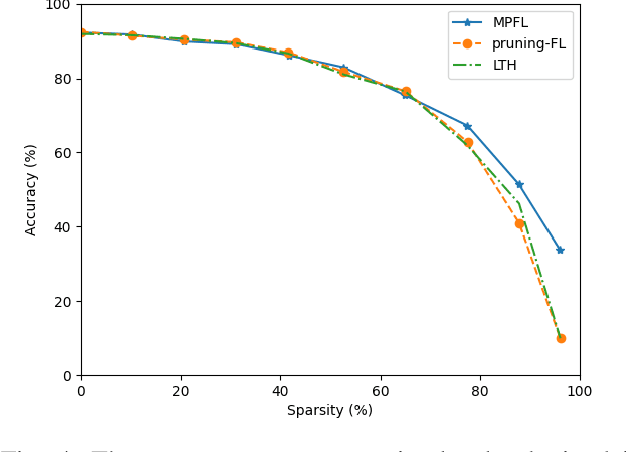
Federated Learning (FL) represents a growing machine learning (ML) paradigm designed for training models across numerous nodes that retain local datasets, all without directly exchanging the underlying private data with the parameter server (PS). Its increasing popularity is attributed to notable advantages in terms of training deep neural network (DNN) models under privacy aspects and efficient utilization of communication resources. Unfortunately, DNNs suffer from high computational and communication costs, as well as memory consumption in intricate tasks. These factors restrict the applicability of FL algorithms in communication-constrained systems with limited hardware resources. In this paper, we develop a novel algorithm that overcomes these limitations by synergistically combining a pruning-based method with the FL process, resulting in low-dimensional representations of the model with minimal communication cost, dubbed Masked Pruning over FL (MPFL). The algorithm operates by initially distributing weights to the nodes through the PS. Subsequently, each node locally trains its model and computes pruning masks. These low-dimensional masks are then transmitted back to the PS, which generates a consensus pruning mask, broadcasted back to the nodes. This iterative process enhances the robustness and stability of the masked pruning model. The generated mask is used to train the FL model, achieving significant bandwidth savings. We present an extensive experimental study demonstrating the superior performance of MPFL compared to existing methods. Additionally, we have developed an open-source software package for the benefit of researchers and developers in related fields.
Deep Multi-Agent Reinforcement Learning for Decentralized Active Hypothesis Testing
Sep 14, 2023



We consider a decentralized formulation of the active hypothesis testing (AHT) problem, where multiple agents gather noisy observations from the environment with the purpose of identifying the correct hypothesis. At each time step, agents have the option to select a sampling action. These different actions result in observations drawn from various distributions, each associated with a specific hypothesis. The agents collaborate to accomplish the task, where message exchanges between agents are allowed over a rate-limited communications channel. The objective is to devise a multi-agent policy that minimizes the Bayes risk. This risk comprises both the cost of sampling and the joint terminal cost incurred by the agents upon making a hypothesis declaration. Deriving optimal structured policies for AHT problems is generally mathematically intractable, even in the context of a single agent. As a result, recent efforts have turned to deep learning methodologies to address these problems, which have exhibited significant success in single-agent learning scenarios. In this paper, we tackle the multi-agent AHT formulation by introducing a novel algorithm rooted in the framework of deep multi-agent reinforcement learning. This algorithm, named Multi-Agent Reinforcement Learning for AHT (MARLA), operates at each time step by having each agent map its state to an action (sampling rule or stopping rule) using a trained deep neural network with the goal of minimizing the Bayes risk. We present a comprehensive set of experimental results that effectively showcase the agents' ability to learn collaborative strategies and enhance performance using MARLA. Furthermore, we demonstrate the superiority of MARLA over single-agent learning approaches. Finally, we provide an open-source implementation of the MARLA framework, for the benefit of researchers and developers in related domains.
Federated Learning from Heterogeneous Data via Controlled Bayesian Air Aggregation
Mar 30, 2023



Federated learning (FL) is an emerging machine learning paradigm for training models across multiple edge devices holding local data sets, without explicitly exchanging the data. Recently, over-the-air (OTA) FL has been suggested to reduce the bandwidth and energy consumption, by allowing the users to transmit their data simultaneously over a Multiple Access Channel (MAC). However, this approach results in channel noise directly affecting the optimization procedure, which may degrade the accuracy of the trained model. In this paper we jointly exploit the prior distribution of local weights and the channel distribution, and develop an OTA FL algorithm based on a Bayesian approach for signal aggregation. Our proposed algorithm, dubbed Bayesian Air Aggregation Federated learning (BAAF), is shown to effectively mitigate noise and fading effects induced by the channel. To handle statistical heterogeneity of users data, which is a second major challenge in FL, we extend BAAF to allow for appropriate local updates by the users and develop the Controlled Bayesian Air Aggregation Federated-learning (COBAAF) algorithm. In addition to using a Bayesian approach to average the channel output, COBAAF controls the drift in local updates using a judicious design of correction terms. We analyze the convergence of the learned global model using BAAF and COBAAF in noisy and heterogeneous environment, showing their ability to achieve a convergence rate similar to that achieved over error-free channels. Simulation results demonstrate the improved convergence of BAAF and COBAAF over existing algorithms in machine learning tasks.