 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Training for Federated Learning with Regularized Error Correction
Paper and Code
Dec 21, 2023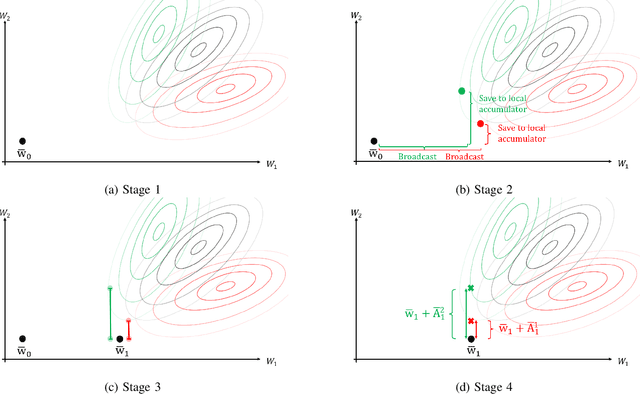
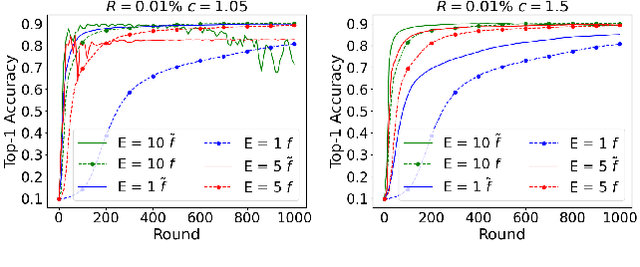
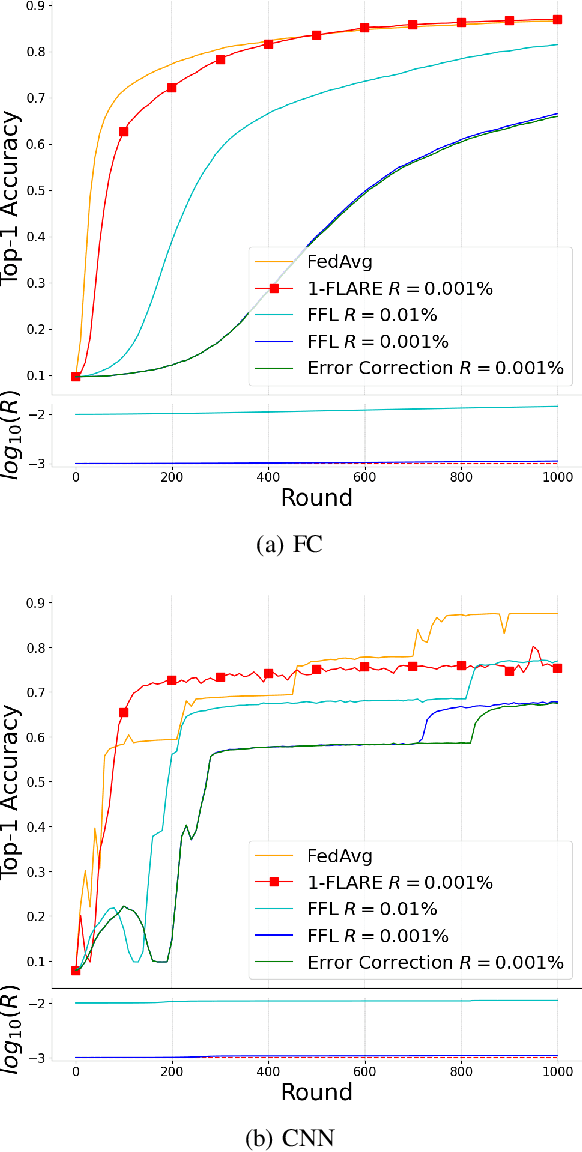
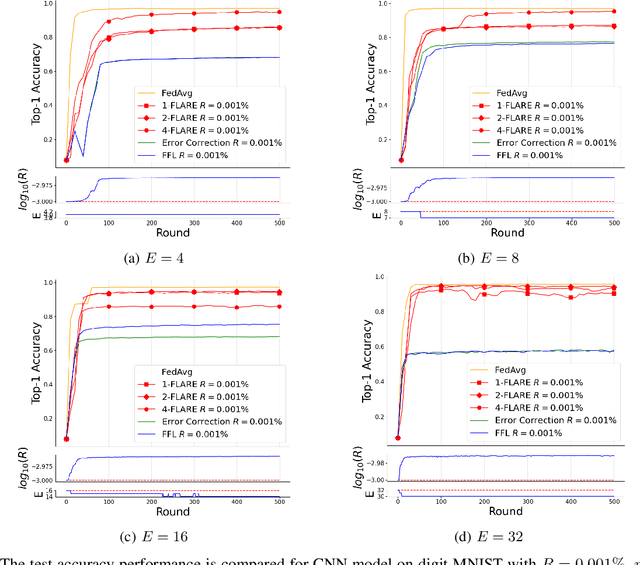
Federated Learning (FL) has attracted much interest due to the significant advantages it brings to training deep neural network (DNN) models. However, since communications and computation resources are limited, training DNN models in FL systems face challenges such as elevated computational and communication costs in complex tasks. Sparse training schemes gain increasing attention in order to scale down the dimensionality of each client (i.e., node) transmission. Specifically, sparsification with error correction methods is a promising technique, where only important updates are sent to the parameter server (PS) and the rest are accumulated locally. While error correction methods have shown to achieve a significant sparsification level of the client-to-PS message without harming convergence, pushing sparsity further remains unresolved due to the staleness effect. In this paper, we propose a novel algorithm, dubbed Federated Learning with Accumulated Regularized Embeddings (FLARE), to overcome this challenge. FLARE presents a novel sparse training approach via accumulated pulling of the updated models with regularization on the embeddings in the FL process, providing a powerful solution to the staleness effect, and pushing sparsity to an exceptional level. The performance of FLARE is validated through extensive experiments on diverse and complex models, achieving a remarkable sparsity level (10 times and more beyond the current state-of-the-art) along with significantly improved accuracy. Additionally, an open-source software package has been developed for the benefit of researchers and developers in related fields.