 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Precision Quantization for Efficient and Accurate Deep Neural Networks Inference
May 20, 2025Deep neural networks have achieved state-of-the-art results in a wide range of applications, from natural language processing and computer vision to speech recognition. However, as tasks become increasingly complex, model sizes continue to grow, posing challenges in latency and memory efficiency. To meet these constraints, post-training quantization has emerged as a promising solution. In this paper, we propose a novel hardware-efficient quantization and inference scheme that exploits hardware advantages with minimal accuracy degradation. Specifically, we introduce a W4A8 scheme, where weights are quantized and stored using 4-bit integer precision, and inference computations are performed using 8-bit floating-point arithmetic, demonstrating significant speedups and improved memory utilization compared to 16-bit operations, applicable on various modern accelerators. To mitigate accuracy loss, we develop a novel quantization algorithm, dubbed Dual Precision Quantization (DPQ), that leverages the unique structure of our scheme without introducing additional inference overhead. Experimental results demonstrate improved performance (i.e., increased throughput) while maintaining tolerable accuracy degradation relative to the full-precision model.
Asymptotically Optimal Search for a Change Point Anomaly under a Composite Hypothesis Model
Dec 27, 2024



We address the problem of searching for a change point in an anomalous process among a finite set of M processes. Specifically, we address a composite hypothesis model in which each process generates measurements following a common distribution with an unknown parameter (vector). This parameter belongs to either a normal or abnormal space depending on the current state of the process. Before the change point, all processes, including the anomalous one, are in a normal state; after the change point, the anomalous process transitions to an abnormal state. Our goal is to design a sequential search strategy that minimizes the Bayes risk by balancing sample complexity and detection accuracy. We propose a deterministic search algorithm with the following notable properties. First, we analytically demonstrate that when the distributions of both normal and abnormal processes are unknown, the algorithm is asymptotically optimal in minimizing the Bayes risk as the error probability approaches zero. In the second setting, where the parameter under the null hypothesis is known, the algorithm achieves asymptotic optimality with improved detection time based on the true normal state. Simulation results are presented to validate the theoretical findings.
SINR-Aware Deep Reinforcement Learning for Distributed Dynamic Channel Allocation in Cognitive Interference Networks
Feb 17, 2024



We consider the problem of dynamic channel allocation (DCA) in cognitive communication networks with the goal of maximizing a global signal-to-interference-plus-noise ratio (SINR) measure under a specified target quality of service (QoS)-SINR for each network. The shared bandwidth is partitioned into K channels with frequency separation. In contrast to the majority of existing studies that assume perfect orthogonality or a one- to-one user-channel allocation mapping, this paper focuses on real-world systems experiencing inter-carrier interference (ICI) and channel reuse by multiple large-scale networks. This realistic scenario significantly increases the problem dimension, rendering existing algorithms inefficient. We propose a novel multi-agent reinforcement learning (RL) framework for distributed DCA, named Channel Allocation RL To Overlapped Networks (CARLTON). The CARLTON framework is based on the Centralized Training with Decentralized Execution (CTDE) paradigm, utilizing the DeepMellow value-based RL algorithm. To ensure robust performance in the interference-laden environment we address, CARLTON employs a low-dimensional representation of observations, generating a QoS-type measure while maximizing a global SINR measure and ensuring the target QoS-SINR for each network. Our results demonstrate exceptional performance and robust generalization, showcasing superior efficiency compared to alternative state-of-the-art methods, while achieving a marginally diminished performance relative to a fully centralized approach.
Federated Learning from Heterogeneous Data via Controlled Bayesian Air Aggregation
Mar 30, 2023



Federated learning (FL) is an emerging machine learning paradigm for training models across multiple edge devices holding local data sets, without explicitly exchanging the data. Recently, over-the-air (OTA) FL has been suggested to reduce the bandwidth and energy consumption, by allowing the users to transmit their data simultaneously over a Multiple Access Channel (MAC). However, this approach results in channel noise directly affecting the optimization procedure, which may degrade the accuracy of the trained model. In this paper we jointly exploit the prior distribution of local weights and the channel distribution, and develop an OTA FL algorithm based on a Bayesian approach for signal aggregation. Our proposed algorithm, dubbed Bayesian Air Aggregation Federated learning (BAAF), is shown to effectively mitigate noise and fading effects induced by the channel. To handle statistical heterogeneity of users data, which is a second major challenge in FL, we extend BAAF to allow for appropriate local updates by the users and develop the Controlled Bayesian Air Aggregation Federated-learning (COBAAF) algorithm. In addition to using a Bayesian approach to average the channel output, COBAAF controls the drift in local updates using a judicious design of correction terms. We analyze the convergence of the learned global model using BAAF and COBAAF in noisy and heterogeneous environment, showing their ability to achieve a convergence rate similar to that achieved over error-free channels. Simulation results demonstrate the improved convergence of BAAF and COBAAF over existing algorithms in machine learning tasks.
Composite Anomaly Detection via Hierarchical Dynamic Search
Mar 17, 2022
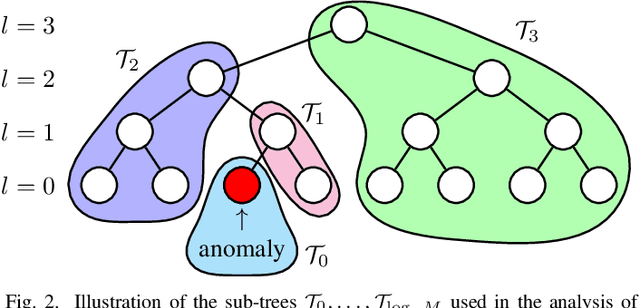
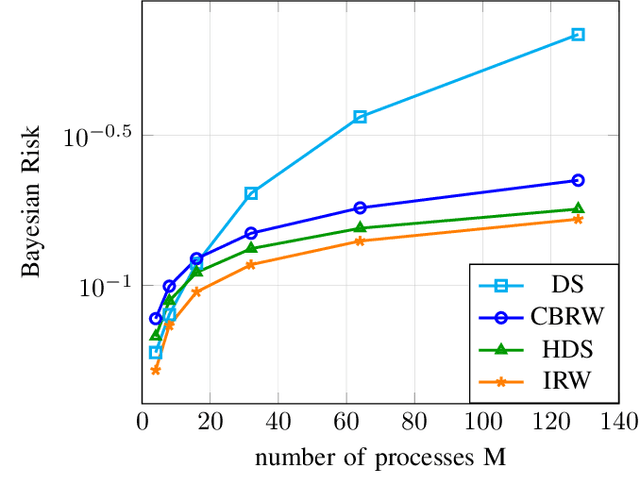
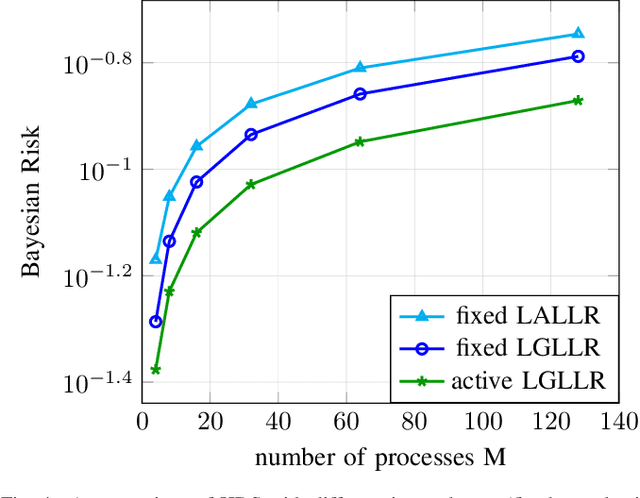
Anomaly detection among a large number of processes arises in many applications ranging from dynamic spectrum access to cybersecurity. In such problems one can often obtain noisy observations aggregated from a chosen subset of processes that conforms to a tree structure. The distribution of these observations, based on which the presence of anomalies is detected, may be only partially known. This gives rise to the need for a search strategy designed to account for both the sample complexity and the detection accuracy, as well as cope with statistical models that are known only up to some missing parameters. In this work we propose a sequential search strategy using two variations of the Generalized Local Likelihood Ratio statistic. Our proposed Hierarchical Dynamic Search (HDS) strategy is shown to be order-optimal with respect to the size of the search space and asymptotically optimal with respect to the detection accuracy. An explicit upper bound on the error probability of HDS is established for the finite sample regime. Extensive experiments are conducted, demonstrating the performance gains of HDS over existing methods.
Restless Multi-Armed Bandits under Exogenous Global Markov Process
Feb 28, 2022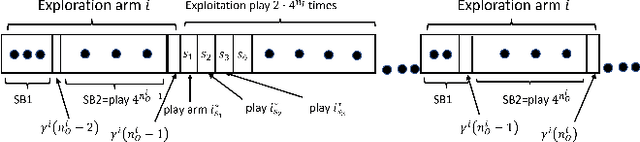

We consider an extension to the restless multi-armed bandit (RMAB) problem with unknown arm dynamics, where an unknown exogenous global Markov process governs the rewards distribution of each arm. Under each global state, the rewards process of each arm evolves according to an unknown Markovian rule, which is non-identical among different arms. At each time, a player chooses an arm out of N arms to play, and receives a random reward from a finite set of reward states. The arms are restless, that is, their local state evolves regardless of the player's actions. The objective is an arm-selection policy that minimizes the regret, defined as the reward loss with respect to a player that knows the dynamics of the problem, and plays at each time t the arm that maximizes the expected immediate value. We develop the Learning under Exogenous Markov Process (LEMP) algorithm, that achieves a logarithmic regret order with time, and a finite-sample bound on the regret is established. Simulation results support the theoretical study and demonstrate strong performances of LEMP.
Learning in Restless Bandits under Exogenous Global Markov Process
Dec 17, 2021
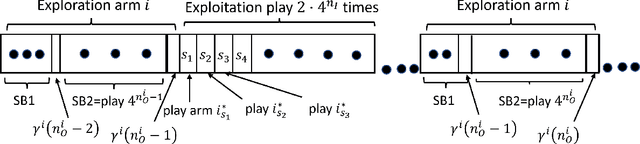


We consider an extension to the restless multi-armed bandit (RMAB) problem with unknown arm dynamics, where an unknown exogenous global Markov process governs the rewards distribution of each arm. Under each global state, the rewards process of each arm evolves according to an unknown Markovian rule, which is non-identical among different arms. At each time, a player chooses an arm out of $N$ arms to play, and receives a random reward from a finite set of reward states. The arms are restless, that is, their local state evolves regardless of the player's actions. Motivated by recent studies on related RMAB settings, the regret is defined as the reward loss with respect to a player that knows the dynamics of the problem, and plays at each time $t$ the arm that maximizes the expected immediate value. The objective is to develop an arm-selection policy that minimizes the regret. To that end, we develop the Learning under Exogenous Markov Process (LEMP) algorithm. We analyze LEMP theoretically and establish a finite-sample bound on the regret. We show that LEMP achieves a logarithmic regret order with time. We further analyze LEMP numerically and present simulation results that support the theoretical findings and demonstrate that LEMP significantly outperforms alternative algorithms.
Federated Learning: A Signal Processing Perspective
Mar 31, 2021
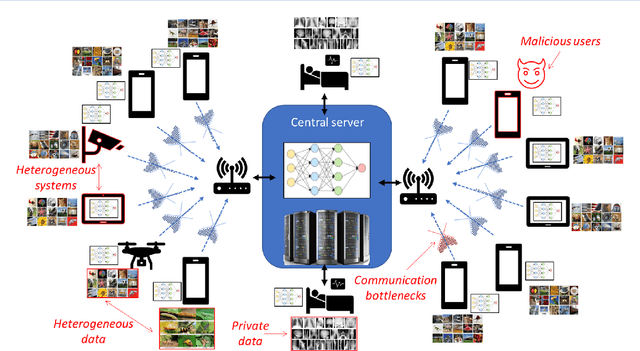
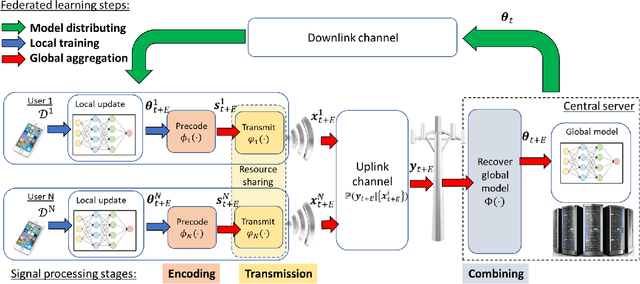

The dramatic success of deep learning is largely due to the availability of data. Data samples are often acquired on edge devices, such as smart phones, vehicles and sensors, and in some cases cannot be shared due to privacy considerations. Federated learning is an emerging machine learning paradigm for training models across multiple edge devices holding local datasets, without explicitly exchanging the data. Learning in a federated manner differs from conventional centralized machine learning, and poses several core unique challenges and requirements, which are closely related to classical problems studied in the areas of signal processing and communications. Consequently, dedicated schemes derived from these areas are expected to play an important role in the success of federated learning and the transition of deep learning from the domain of centralized servers to mobile edge devices. In this article, we provide a unified systematic framework for federated learning in a manner that encapsulates and highlights the main challenges that are natural to treat using signal processing tools. We present a formulation for the federated learning paradigm from a signal processing perspective, and survey a set of candidate approaches for tackling its unique challenges. We further provide guidelines for the design and adaptation of signal processing and communication methods to facilitate federated learning at large scale.
Distributed Learning over Markovian Fading Channels for Stable Spectrum Access
Jan 27, 2021
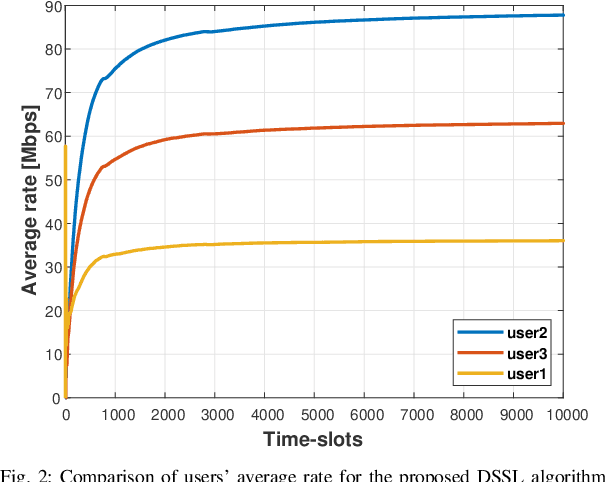


We consider the problem of multi-user spectrum access in wireless networks. The bandwidth is divided into K orthogonal channels, and M users aim to access the spectrum. Each user chooses a single channel for transmission at each time slot. The state of each channel is modeled by a restless unknown Markovian process. Previous studies have analyzed a special case of this setting, in which each channel yields the same expected rate for all users. By contrast, we consider a more general and practical model, where each channel yields a different expected rate for each user. This model adds a significant challenge of how to efficiently learn a channel allocation in a distributed manner to yield a global system-wide objective. We adopt the stable matching utility as the system objective, which is known to yield strong performance in multichannel wireless networks, and develop a novel Distributed Stable Strategy Learning (DSSL) algorithm to achieve the objective. We prove theoretically that DSSL converges to the stable matching allocation, and the regret, defined as the loss in total rate with respect to the stable matching solution, has a logarithmic order with time. Finally, simulation results demonstrate the strong performance of the DSSL algorithm.
Learning in Restless Multi-Armed Bandits via Adaptive Arm Sequencing Rules
Jun 19, 2019
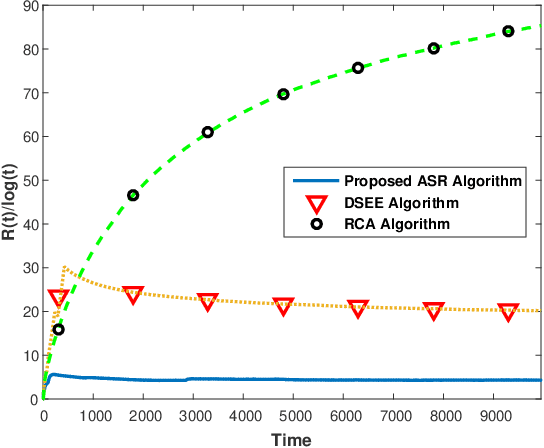

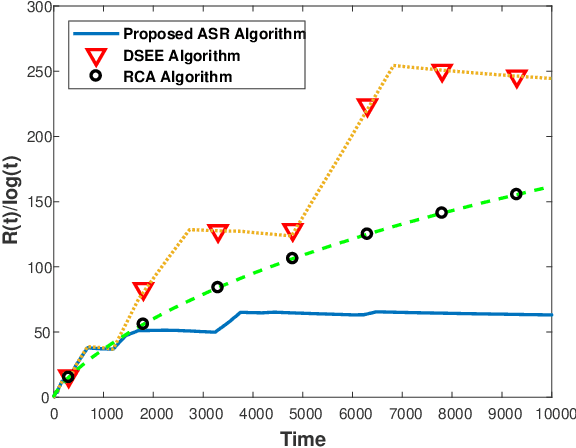
We consider a class of restless multi-armed bandit (RMAB) problems with unknown arm dynamics. At each time, a player chooses an arm out of N arms to play, referred to as an active arm, and receives a random reward from a finite set of reward states. The reward state of the active arm transits according to an unknown Markovian dynamics. The reward state of passive arms (which are not chosen to play at time t) evolves according to an arbitrary unknown random process. The objective is an arm-selection policy that minimizes the regret, defined as the reward loss with respect to a player that always plays the most rewarding arm. This class of RMAB problems has been studied recently in the context of communication networks and financial investment applications. We develop a strategy that selects arms to be played in a consecutive manner, dubbed Adaptive Sequencing Rules (ASR) algorithm. The sequencing rules for selecting arms under the ASR algorithm are adaptively updated and controlled by the current sample reward means. By designing judiciously the adaptive sequencing rules, we show that the ASR algorithm achieves a logarithmic regret order with time, and a finite-sample bound on the regret is established. Although existing methods have shown a logarithmic regret order with time in this RMAB setting, the theoretical analysis shows a significant improvement in the regret scaling with respect to the system parameters under ASR. Extensive simulation results support the theoretical study and demonstrate strong performance of the algorithm as compared to existing methods.