 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriched BERT Embeddings for Scholarly Publication Classification
May 07, 2024With the rapid expansion of academic literature and the proliferation of preprints, researchers face growing challenges in manually organizing and labeling large volumes of articles. The NSLP 2024 FoRC Shared Task I addresses this challenge organized as a competition. The goal is to develop a classifier capable of predicting one of 123 predefined classes from the Open Research Knowledge Graph (ORKG) taxonomy of research fields for a given article.This paper presents our results. Initially, we enrich the dataset (containing English scholarly articles sourced from ORKG and arXiv), then leverage different pre-trained language Models (PLMs), specifically BERT, and explore their efficacy in transfer learning for this downstream task. Our experiments encompass feature-based and fine-tuned transfer learning approaches using diverse PLMs, optimized for scientific tasks, including SciBERT, SciNCL, and SPECTER2. We conduct hyperparameter tuning and investigate the impact of data augmentation from bibliographic databases such as OpenAlex, Semantic Scholar, and Crossref. Our results demonstrate that fine-tuning pre-trained models substantially enhances classification performance, with SPECTER2 emerging as the most accurate model. Moreover, enriching the dataset with additional metadata improves classification outcomes significantly, especially when integrating information from S2AG, OpenAlex and Crossref. Our best-performing approach achieves a weighted F1-score of 0.7415. Overall, our study contributes to the advancement of reliable automated systems for scholarly publication categorization, offering a potential solution to the laborious manual curation process, thereby facilitating researchers in efficiently locating relevant resources.
Composite Anomaly Detection via Hierarchical Dynamic Search
Mar 17, 2022
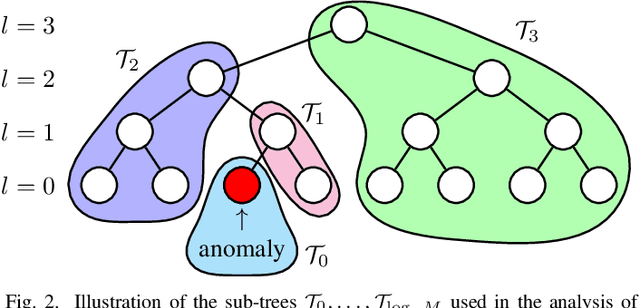
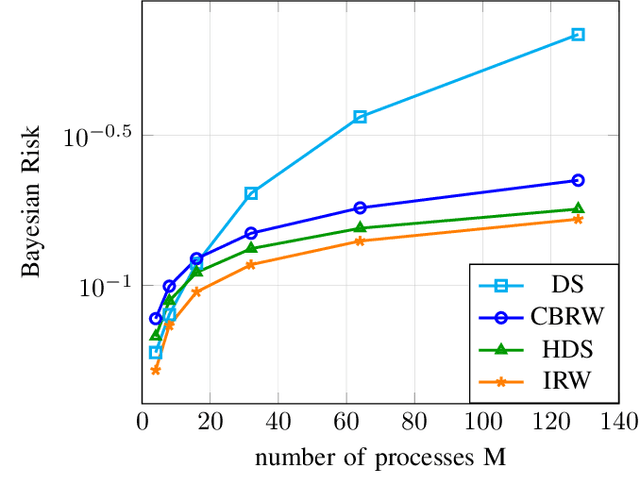
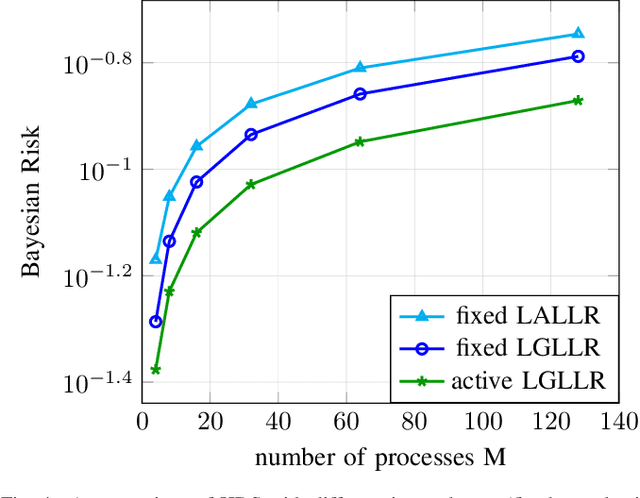
Anomaly detection among a large number of processes arises in many applications ranging from dynamic spectrum access to cybersecurity. In such problems one can often obtain noisy observations aggregated from a chosen subset of processes that conforms to a tree structure. The distribution of these observations, based on which the presence of anomalies is detected, may be only partially known. This gives rise to the need for a search strategy designed to account for both the sample complexity and the detection accuracy, as well as cope with statistical models that are known only up to some missing parameters. In this work we propose a sequential search strategy using two variations of the Generalized Local Likelihood Ratio statistic. Our proposed Hierarchical Dynamic Search (HDS) strategy is shown to be order-optimal with respect to the size of the search space and asymptotically optimal with respect to the detection accuracy. An explicit upper bound on the error probability of HDS is established for the finite sample regime. Extensive experiments are conducted, demonstrating the performance gains of HDS over existing methods.
Overview of LiLAS 2021 -- Living Labs for Academic Search
Mar 10, 2022


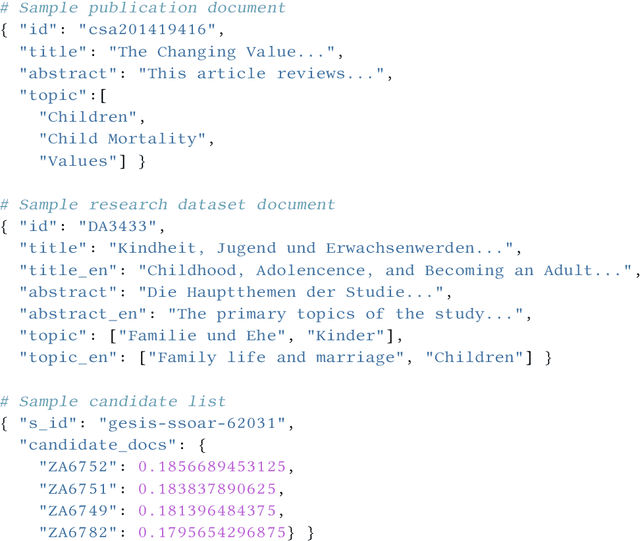
The Living Labs for Academic Search (LiLAS) lab aims to strengthen the concept of user-centric living labs for academic search. The methodological gap between real-world and lab-based evaluation should be bridged by allowing lab participants to evaluate their retrieval approaches in two real-world academic search systems from life sciences and social sciences. This overview paper outlines the two academic search systems LIVIVO and GESIS Search, and their corresponding tasks within LiLAS, which are ad-hoc retrieval and dataset recommendation. The lab is based on a new evaluation infrastructure named STELLA that allows participants to submit results corresponding to their experimental systems in the form of pre-computed runs and Docker containers that can be integrated into production systems and generate experimental results in real-time. Both submission types are interleaved with the results provided by the productive systems allowing for a seamless presentation and evaluation. The evaluation of results and a meta-analysis of the different tasks and submission types complement this overview.