 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in Restless Multi-Armed Bandits via Adaptive Arm Sequencing Rules
Paper and Code
Jun 19, 2019
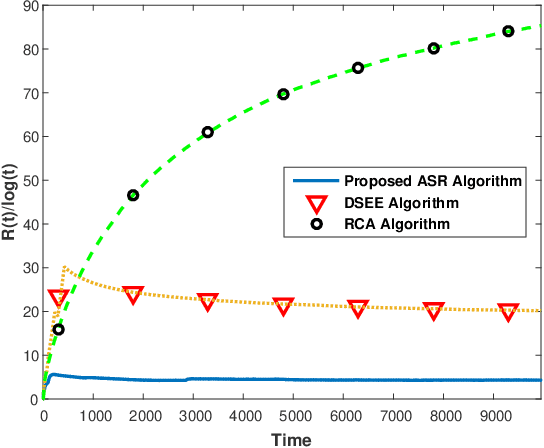

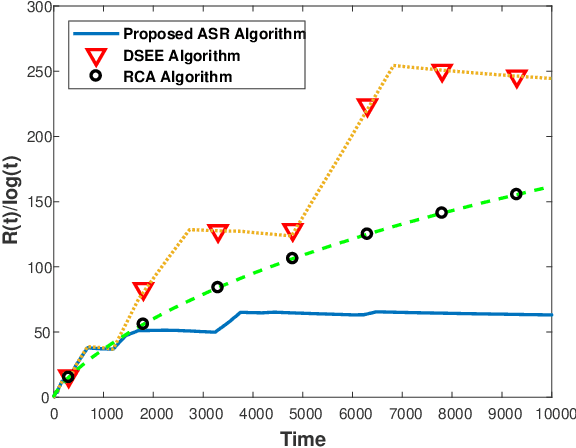
We consider a class of restless multi-armed bandit (RMAB) problems with unknown arm dynamics. At each time, a player chooses an arm out of N arms to play, referred to as an active arm, and receives a random reward from a finite set of reward states. The reward state of the active arm transits according to an unknown Markovian dynamics. The reward state of passive arms (which are not chosen to play at time t) evolves according to an arbitrary unknown random process. The objective is an arm-selection policy that minimizes the regret, defined as the reward loss with respect to a player that always plays the most rewarding arm. This class of RMAB problems has been studied recently in the context of communication networks and financial investment applications. We develop a strategy that selects arms to be played in a consecutive manner, dubbed Adaptive Sequencing Rules (ASR) algorithm. The sequencing rules for selecting arms under the ASR algorithm are adaptively updated and controlled by the current sample reward means. By designing judiciously the adaptive sequencing rules, we show that the ASR algorithm achieves a logarithmic regret order with time, and a finite-sample bound on the regret is established. Although existing methods have shown a logarithmic regret order with time in this RMAB setting, the theoretical analysis shows a significant improvement in the regret scaling with respect to the system parameters under ASR. Extensive simulation results support the theoretical study and demonstrate strong performance of the algorithm as compared to existing methods.