 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Simulate Social Media Engagement? A Study on Action-Guided Response Generation
Feb 17, 2025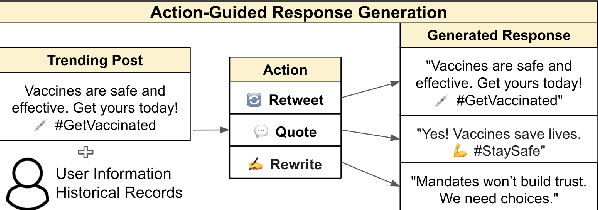



Social media enables dynamic user engagement with trending topics, and recent research has explored the potential of large language models (LLMs) for response generation. While some studies investigate LLMs as agents for simulating user behavior on social media, their focus remains on practical viability and scalability rather than a deeper understanding of how well LLM aligns with human behavior. This paper analyzes LLMs' ability to simulate social media engagement through action guided response generation, where a model first predicts a user's most likely engagement action-retweet, quote, or rewrite-towards a trending post before generating a personalized response conditioned on the predicted action. We benchmark GPT-4o-mini, O1-mini, and DeepSeek-R1 in social media engagement simulation regarding a major societal event discussed on X. Our findings reveal that zero-shot LLMs underperform BERT in action prediction, while few-shot prompting initially degrades the prediction accuracy of LLMs with limited examples. However, in response generation, few-shot LLMs achieve stronger semantic alignment with ground truth posts.
Semantics Preserving Emoji Recommendation with Large Language Models
Sep 16, 2024
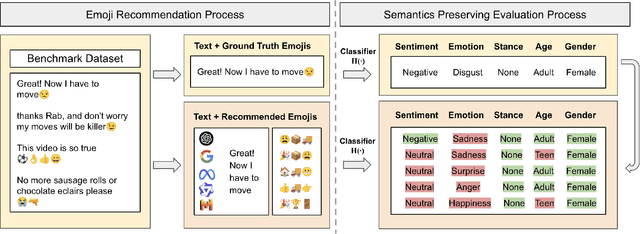

Emojis have become an integral part of digital communication, enriching text by conveying emotions, tone, and intent. Existing emoji recommendation methods are primarily evaluated based on their ability to match the exact emoji a user chooses in the original text. However, they ignore the essence of users' behavior on social media in that each text can correspond to multiple reasonable emojis. To better assess a model's ability to align with such real-world emoji usage, we propose a new semantics preserving evaluation framework for emoji recommendation, which measures a model's ability to recommend emojis that maintain the semantic consistency with the user's text. To evaluate how well a model preserves semantics, we assess whether the predicted affective state, demographic profile, and attitudinal stance of the user remain unchanged. If these attributes are preserved, we consider the recommended emojis to have maintained the original semantics. The advanced abilities of Large Language Models (LLMs) in understanding and generating nuanced, contextually relevant output make them well-suited for handling the complexities of semantics preserving emoji recommendation. To this end, we construct a comprehensive benchmark to systematically assess the performance of six proprietary and open-source LLMs using different prompting techniques on our task. Our experiments demonstrate that GPT-4o outperforms other LLMs, achieving a semantics preservation score of 79.23%. Additionally, we conduct case studies to analyze model biases in downstream classification tasks and evaluate the diversity of the recommended emojis.