 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedRule: Federated Rule Recommendation System with Graph Neural Networks
Nov 13, 2022



Much of the value that IoT (Internet-of-Things) devices bring to ``smart'' homes lies in their ability to automatically trigger other devices' actions: for example, a smart camera triggering a smart lock to unlock a door. Manually setting up these rules for smart devices or applications, however, is time-consuming and inefficient. Rule recommendation systems can automatically suggest rules for users by learning which rules are popular based on those previously deployed (e.g., in others' smart homes). Conventional recommendation formulations require a central server to record the rules used in many users' homes, which compromises their privacy and leaves them vulnerable to attacks on the central server's database of rules. Moreover, these solutions typically leverage generic user-item matrix methods that do not fully exploit the structure of the rule recommendation problem. In this paper, we propose a new rule recommendation system, dubbed as FedRule, to address these challenges. One graph is constructed per user upon the rules s/he is using, and the rule recommendation is formulated as a link prediction task in these graphs. This formulation enables us to design a federated training algorithm that is able to keep users' data private. Extensive experiments corroborate our claims by demonstrating that FedRule has comparable performance as the centralized setting and outperforms conventional solutions.
DAIL: Dataset-Aware and Invariant Learning for Face Recognition
Jan 14, 2021
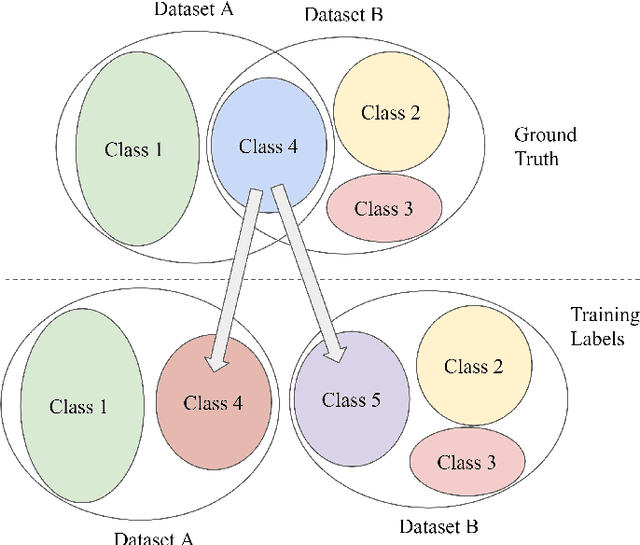
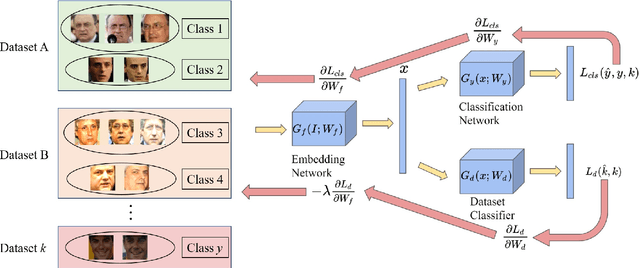
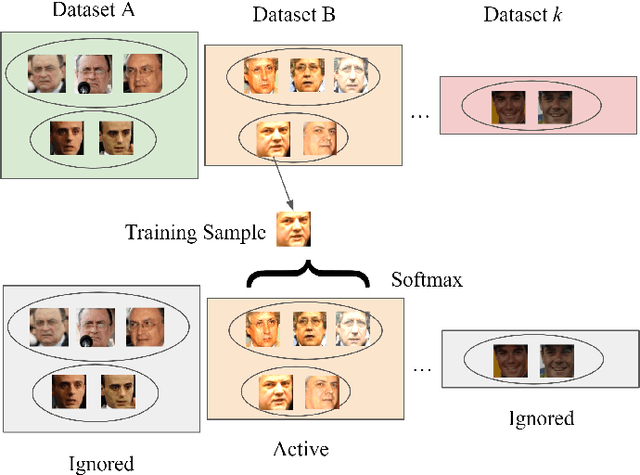
To achieve good performance in face recognition, a large scale training dataset is usually required. A simple yet effective way to improve recognition performance is to use a dataset as large as possible by combining multiple datasets in the training. However, it is problematic and troublesome to naively combine different datasets due to two major issues. First, the same person can possibly appear in different datasets, leading to an identity overlapping issue between different datasets. Naively treating the same person as different classes in different datasets during training will affect back-propagation and generate non-representative embeddings. On the other hand, manually cleaning labels may take formidable human efforts, especially when there are millions of images and thousands of identities. Second, different datasets are collected in different situations and thus will lead to different domain distributions. Naively combining datasets will make it difficult to learn domain invariant embeddings across different datasets. In this paper, we propose DAIL: Dataset-Aware and Invariant Learning to resolve the above-mentioned issues. To solve the first issue of identity overlapping, we propose a dataset-aware loss for multi-dataset training by reducing the penalty when the same person appears in multiple datasets. This can be readily achieved with a modified softmax loss with a dataset-aware term. To solve the second issue, domain adaptation with gradient reversal layers is employed for dataset invariant learning. The proposed approach not only achieves state-of-the-art results on several commonly used face recognition validation sets, including LFW, CFP-FP, and AgeDB-30, but also shows great benefit for practical use.