 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAIL: Dataset-Aware and Invariant Learning for Face Recognition
Jan 14, 2021
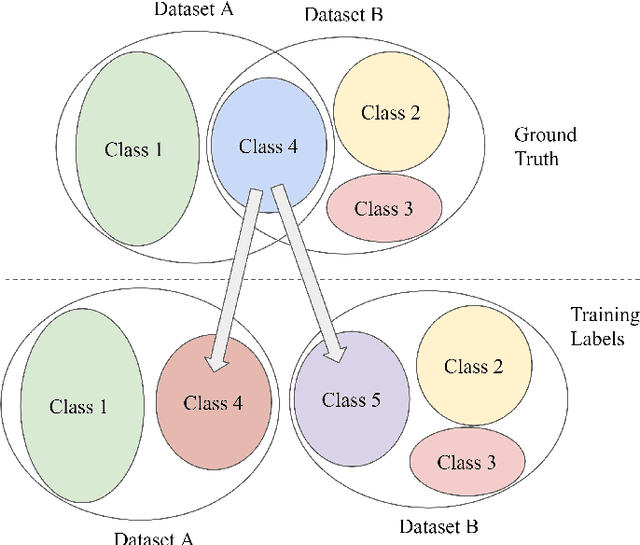
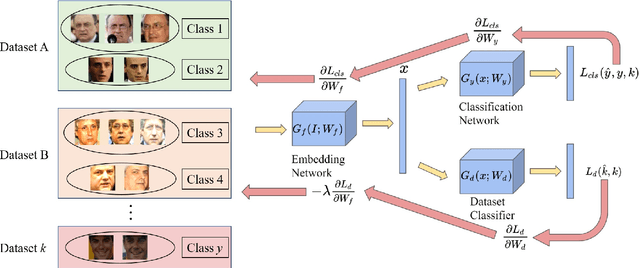
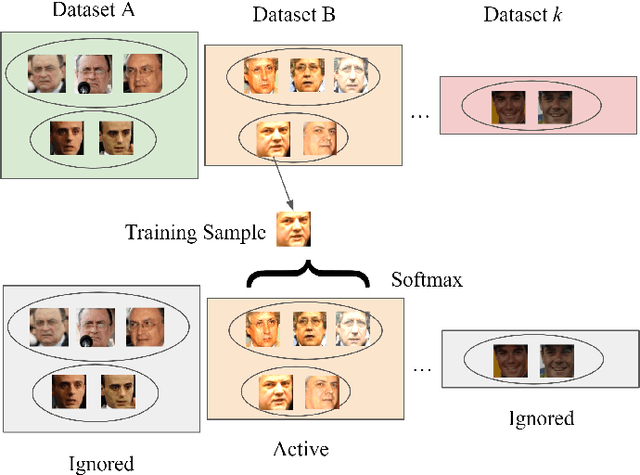
To achieve good performance in face recognition, a large scale training dataset is usually required. A simple yet effective way to improve recognition performance is to use a dataset as large as possible by combining multiple datasets in the training. However, it is problematic and troublesome to naively combine different datasets due to two major issues. First, the same person can possibly appear in different datasets, leading to an identity overlapping issue between different datasets. Naively treating the same person as different classes in different datasets during training will affect back-propagation and generate non-representative embeddings. On the other hand, manually cleaning labels may take formidable human efforts, especially when there are millions of images and thousands of identities. Second, different datasets are collected in different situations and thus will lead to different domain distributions. Naively combining datasets will make it difficult to learn domain invariant embeddings across different datasets. In this paper, we propose DAIL: Dataset-Aware and Invariant Learning to resolve the above-mentioned issues. To solve the first issue of identity overlapping, we propose a dataset-aware loss for multi-dataset training by reducing the penalty when the same person appears in multiple datasets. This can be readily achieved with a modified softmax loss with a dataset-aware term. To solve the second issue, domain adaptation with gradient reversal layers is employed for dataset invariant learning. The proposed approach not only achieves state-of-the-art results on several commonly used face recognition validation sets, including LFW, CFP-FP, and AgeDB-30, but also shows great benefit for practical use.