 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable end-to-end Neurosymbolic Reinforcement Learning agents
Paper and Code
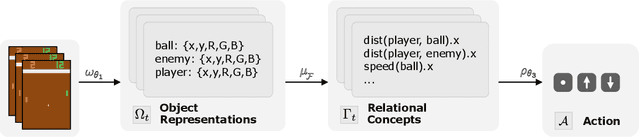
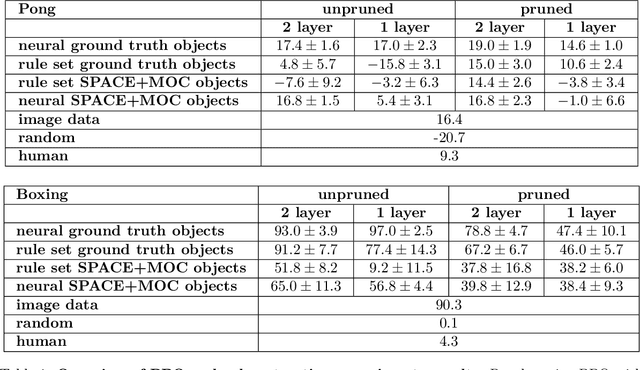
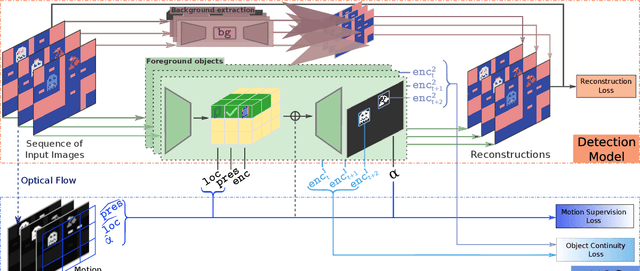

Deep reinforcement learning (RL) agents rely on shortcut learning, preventing them from generalizing to slightly different environments. To address this problem, symbolic method, that use object-centric states, have been developed. However, comparing these methods to deep agents is not fair, as these last operate from raw pixel-based states. In this work, we instantiate the symbolic SCoBots framework. SCoBots decompose RL tasks into intermediate, interpretable representations, culminating in action decisions based on a comprehensible set of object-centric relational concepts. This architecture aids in demystifying agent decisions. By explicitly learning to extract object-centric representations from raw states, object-centric RL, and policy distillation via rule extraction, this work places itself within the neurosymbolic AI paradigm, blending the strengths of neural networks with symbolic AI. We present the first implementation of an end-to-end trained SCoBot, separately evaluate of its components, on different Atari games. The results demonstrate the framework's potential to create interpretable and performing RL systems, and pave the way for future research directions in obtaining end-to-end interpretable RL agents.