 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Improving alignment of dialogue agents via targeted human judgements
Sep 28, 2022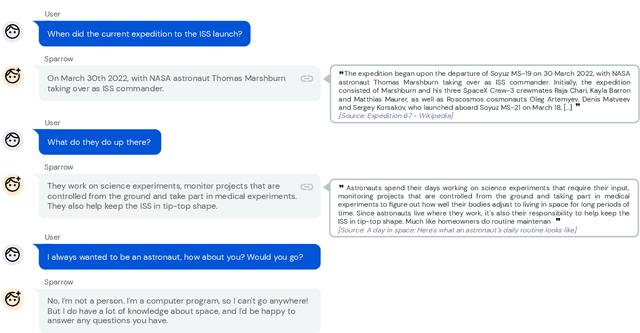

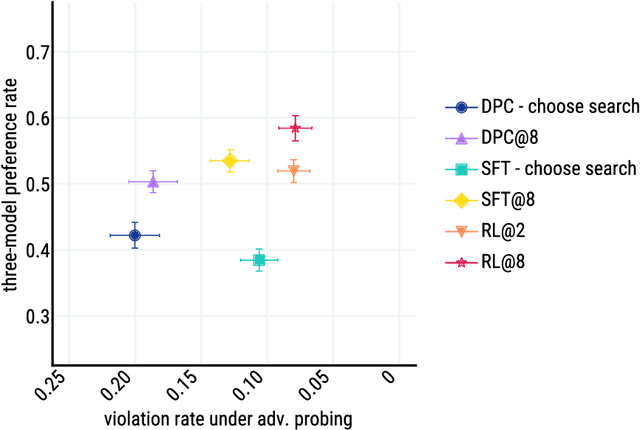
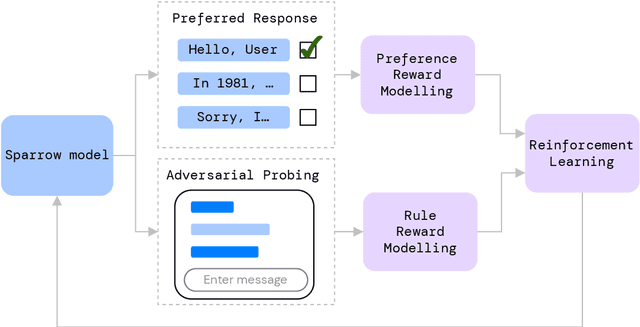
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
NeRF-VAE: A Geometry Aware 3D Scene Generative Model
Apr 01, 2021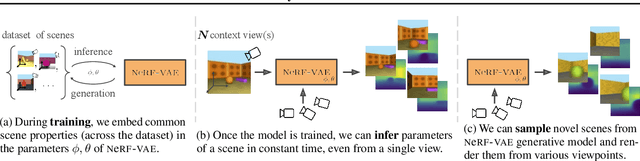

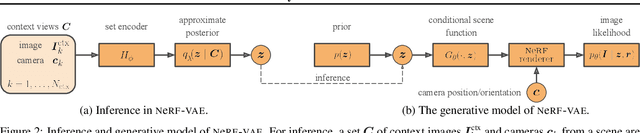
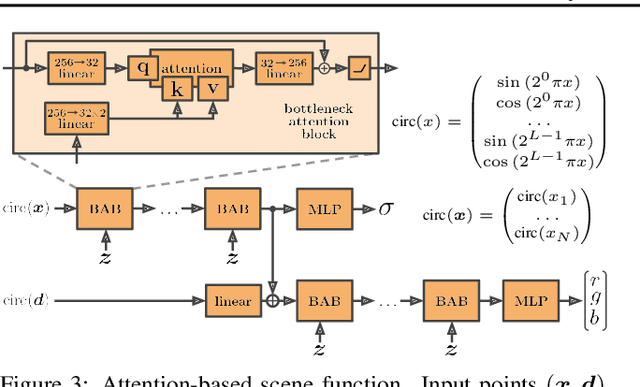
We propose NeRF-VAE, a 3D scene generative model that incorporates geometric structure via NeRF and differentiable volume rendering. In contrast to NeRF, our model takes into account shared structure across scenes, and is able to infer the structure of a novel scene -- without the need to re-train -- using amortized inference. NeRF-VAE's explicit 3D rendering process further contrasts previous generative models with convolution-based rendering which lacks geometric structure. Our model is a VAE that learns a distribution over radiance fields by conditioning them on a latent scene representation. We show that, once trained, NeRF-VAE is able to infer and render geometrically-consistent scenes from previously unseen 3D environments using very few input images. We further demonstrate that NeRF-VAE generalizes well to out-of-distribution cameras, while convolutional models do not. Finally, we introduce and study an attention-based conditioning mechanism of NeRF-VAE's decoder, which improves model performance.
Imitating Interactive Intelligence
Jan 21, 2021
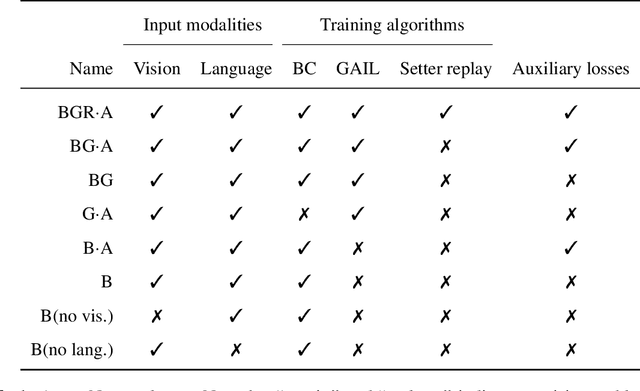
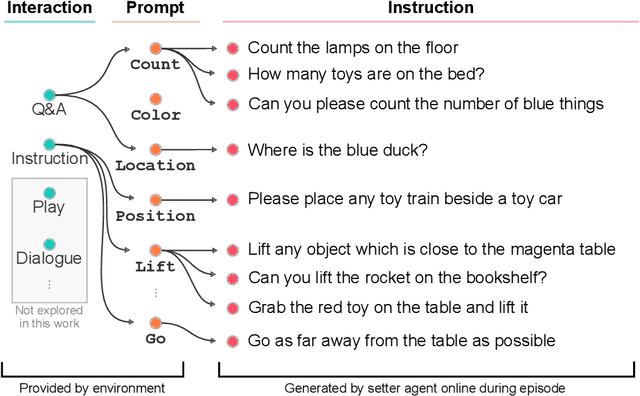
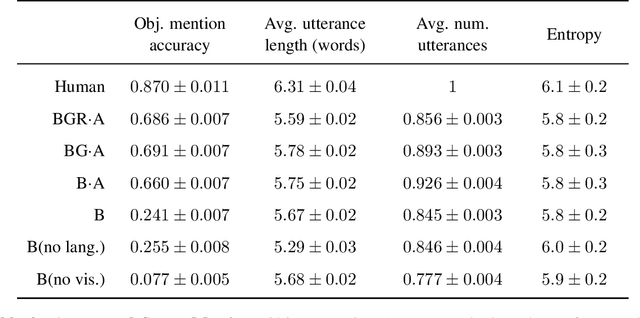
A common vision from science fiction is that robots will one day inhabit our physical spaces, sense the world as we do, assist our physical labours, and communicate with us through natural language. Here we study how to design artificial agents that can interact naturally with humans using the simplification of a virtual environment. This setting nevertheless integrates a number of the central challenges of artificial intelligence (AI) research: complex visual perception and goal-directed physical control, grounded language comprehension and production, and multi-agent social interaction. To build agents that can robustly interact with humans, we would ideally train them while they interact with humans. However, this is presently impractical. Therefore, we approximate the role of the human with another learned agent, and use ideas from inverse reinforcement learning to reduce the disparities between human-human and agent-agent interactive behaviour. Rigorously evaluating our agents poses a great challenge, so we develop a variety of behavioural tests, including evaluation by humans who watch videos of agents or interact directly with them. These evaluations convincingly demonstrate that interactive training and auxiliary losses improve agent behaviour beyond what is achieved by supervised learning of actions alone. Further, we demonstrate that agent capabilities generalise beyond literal experiences in the dataset. Finally, we train evaluation models whose ratings of agents agree well with human judgement, thus permitting the evaluation of new agent models without additional effort. Taken together, our results in this virtual environment provide evidence that large-scale human behavioural imitation is a promising tool to create intelligent, interactive agents, and the challenge of reliably evaluating such agents is possible to surmount.