 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaFun: Meta-Learning with Iterative Functional Updates
Paper and Code
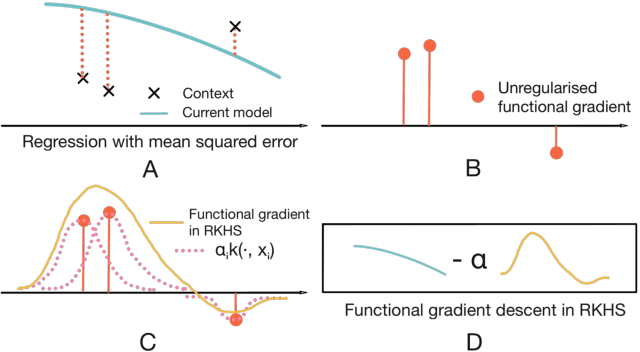
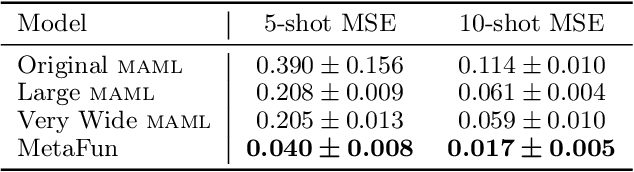
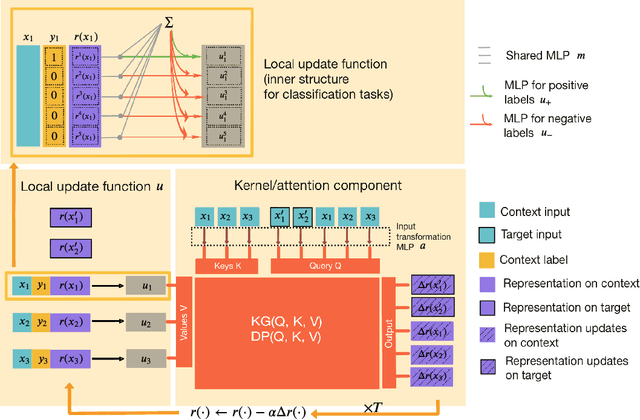
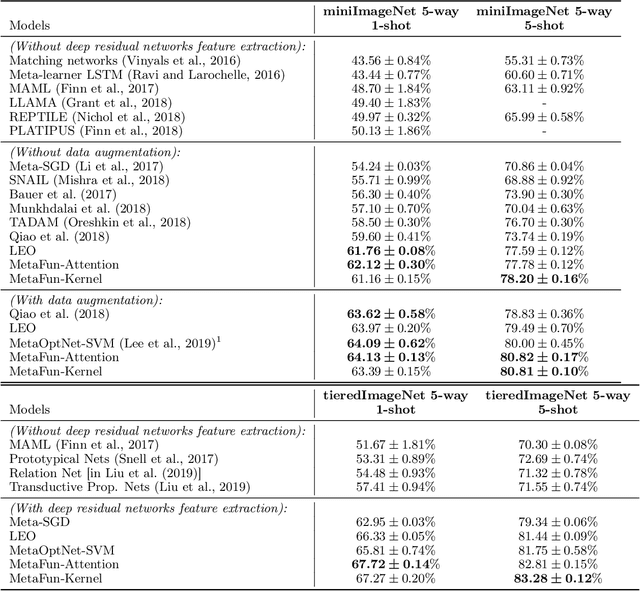
Few-shot supervised learning leverages experience from previous learning tasks to solve new tasks where only a few labelled examples are available. One successful line of approach to this problem is to use an encoder-decoder meta-learning pipeline, whereby labelled data in a task is encoded to produce task representation, and this representation is used to condition the decoder to make predictions on unlabelled data. We propose an approach that uses this pipeline with two important features. 1) We use infinite-dimensional functional representations of the task rather than fixed-dimensional representations. 2) We iteratively apply functional updates to the representation. We show that our approach can be interpreted as extending functional gradient descent, and delivers performance that is comparable to or outperforms previous state-of-the-art on few-shot classification benchmarks such as miniImageNet and tieredImageNet.