 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual RNN-GANs for Abstract Reasoning Diagram Generation
Dec 06, 2016
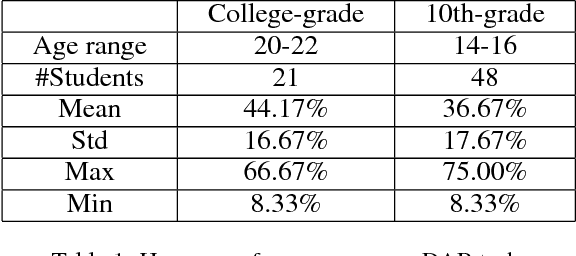
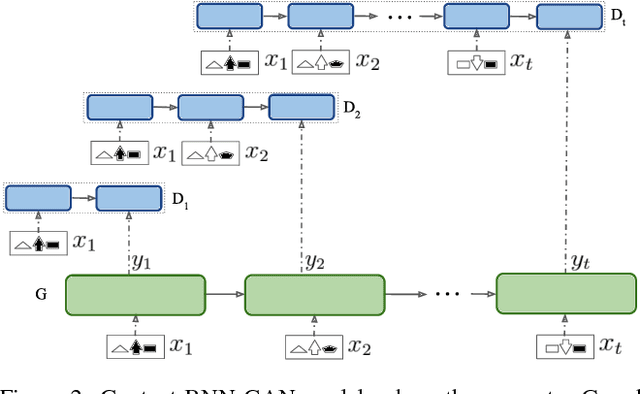
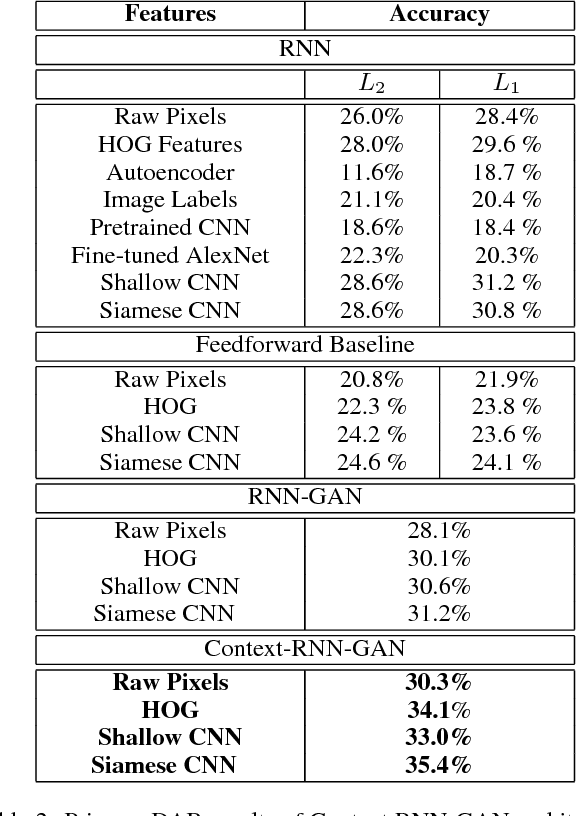
Understanding, predicting, and generating object motions and transformations is a core problem in artificial intelligence. Modeling sequences of evolving images may provide better representations and models of motion and may ultimately be used for forecasting, simulation, or video generation. Diagrammatic Abstract Reasoning is an avenue in which diagrams evolve in complex patterns and one needs to infer the underlying pattern sequence and generate the next image in the sequence. For this, we develop a novel Contextual Generative Adversarial Network based on Recurrent Neural Networks (Context-RNN-GANs), where both the generator and the discriminator modules are based on contextual history (modeled as RNNs) and the adversarial discriminator guides the generator to produce realistic images for the particular time step in the image sequence. We evaluate the Context-RNN-GAN model (and its variants) on a novel dataset of Diagrammatic Abstract Reasoning, where it performs competitively with 10th-grade human performance but there is still scope for interesting improvements as compared to college-grade human performance. We also evaluate our model on a standard video next-frame prediction task, achieving improved performance over comparable state-of-the-art.
Words are not Equal: Graded Weighting Model for building Composite Document Vectors
Dec 11, 2015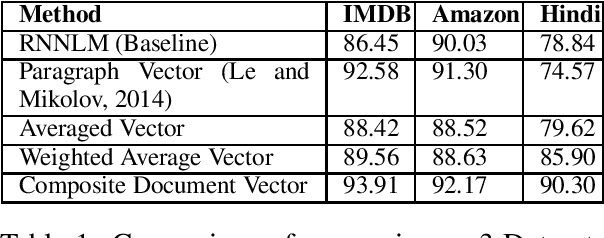

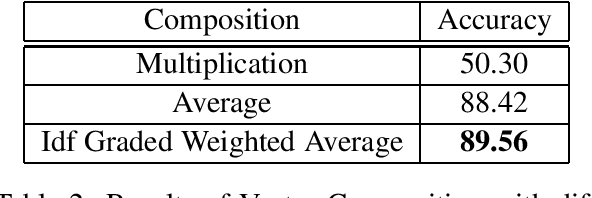
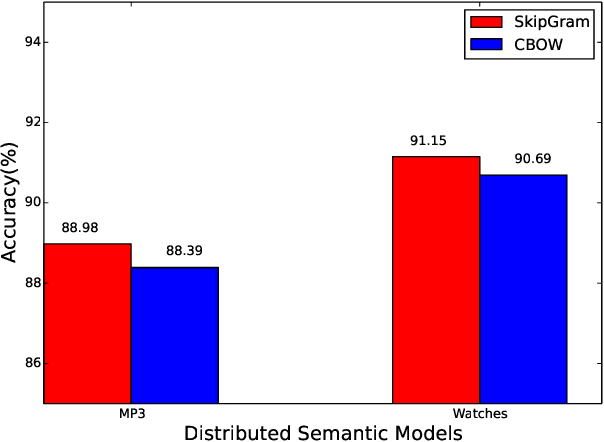
Despite the success of distributional semantics, composing phrases from word vectors remains an important challenge. Several methods have been tried for benchmark tasks such as sentiment classification, including word vector averaging, matrix-vector approaches based on parsing, and on-the-fly learning of paragraph vectors. Most models usually omit stop words from the composition. Instead of such an yes-no decision, we consider several graded schemes where words are weighted according to their discriminatory relevance with respect to its use in the document (e.g., idf). Some of these methods (particularly tf-idf) are seen to result in a significant improvement in performance over prior state of the art. Further, combining such approaches into an ensemble based on alternate classifiers such as the RNN model, results in an 1.6% performance improvement on the standard IMDB movie review dataset, and a 7.01% improvement on Amazon product reviews. Since these are language free models and can be obtained in an unsupervised manner, they are of interest also for under-resourced languages such as Hindi as well and many more languages. We demonstrate the language free aspects by showing a gain of 12% for two review datasets over earlier results, and also release a new larger dataset for future testing (Singh,2015).
Visual Generalized Coordinates
Sep 18, 2015
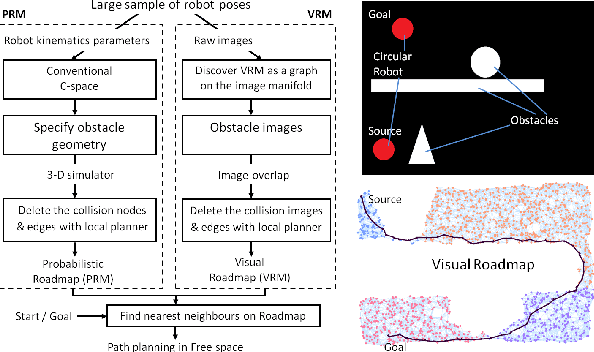
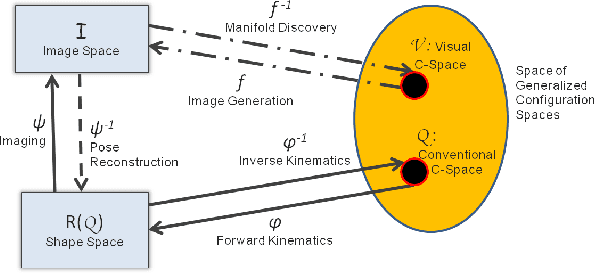

An open problem in robotics is that of using vision to identify a robot's own body and the world around it. Many models attempt to recover the traditional C-space parameters. Instead, we propose an alternative C-space by deriving generalized coordinates from $n$ images of the robot. We show that the space of such images is bijective to the motion space, so these images lie on a manifold $\mathcal{V}$ homeomorphic to the canonical C-space. We now approximate this manifold as a set of $n$ neighbourhood tangent spaces that result in a graph, which we call the Visual Roadmap (VRM). Given a new robot image, we perform inverse kinematics visually by interpolating between nearby images in the image space. Obstacles are projected onto the VRM in $O(n)$ time by superimposition of images, leading to the identification of collision poses. The edges joining the free nodes can now be checked with a visual local planner, and free-space motions computed in $O(nlogn)$ time. This enables us to plan paths in the image space for a robot manipulator with unknown link geometries, DOF, kinematics, obstacles, and camera pose. We sketch the proofs for the main theoretical ideas, identify the assumptions, and demonstrate the approach for both articulated and mobile robots. We also investigate the feasibility of the process by investigating various metrics and image sampling densities, and demonstrate it on simulated and real robots.