 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Generalized Coordinates
Sep 18, 2015
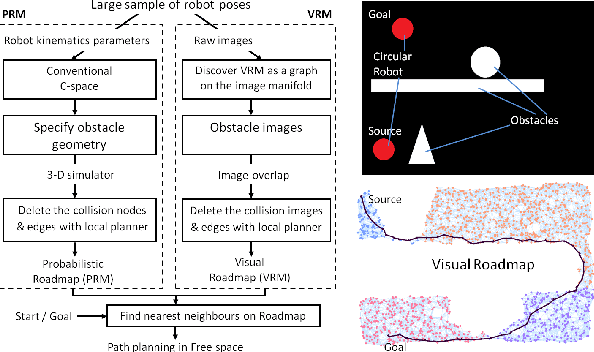
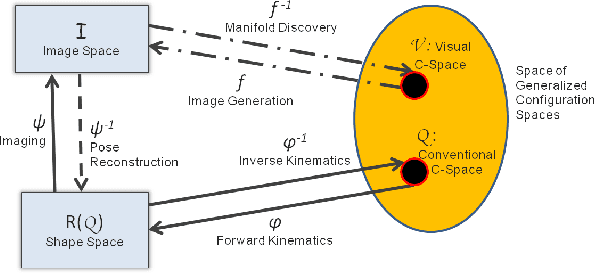

An open problem in robotics is that of using vision to identify a robot's own body and the world around it. Many models attempt to recover the traditional C-space parameters. Instead, we propose an alternative C-space by deriving generalized coordinates from $n$ images of the robot. We show that the space of such images is bijective to the motion space, so these images lie on a manifold $\mathcal{V}$ homeomorphic to the canonical C-space. We now approximate this manifold as a set of $n$ neighbourhood tangent spaces that result in a graph, which we call the Visual Roadmap (VRM). Given a new robot image, we perform inverse kinematics visually by interpolating between nearby images in the image space. Obstacles are projected onto the VRM in $O(n)$ time by superimposition of images, leading to the identification of collision poses. The edges joining the free nodes can now be checked with a visual local planner, and free-space motions computed in $O(nlogn)$ time. This enables us to plan paths in the image space for a robot manipulator with unknown link geometries, DOF, kinematics, obstacles, and camera pose. We sketch the proofs for the main theoretical ideas, identify the assumptions, and demonstrate the approach for both articulated and mobile robots. We also investigate the feasibility of the process by investigating various metrics and image sampling densities, and demonstrate it on simulated and real robots.