 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Large-Scale Dense 3D Reconstruction with Online Inter-Agent Pose Optimisation
Jan 25, 2018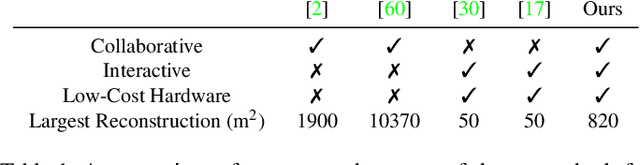

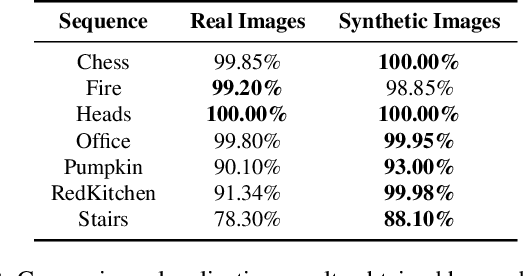
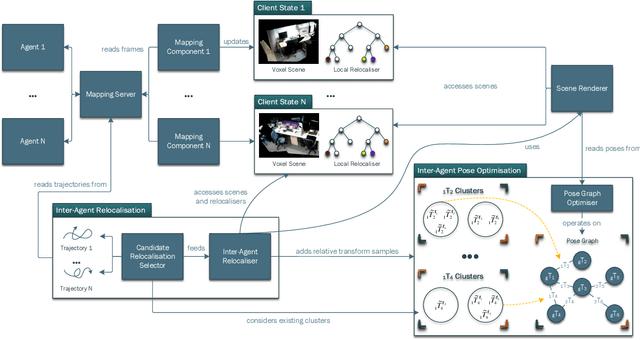
Reconstructing dense, volumetric models of real-world 3D scenes is important for many tasks, but capturing large scenes can take significant time, and the risk of transient changes to the scene goes up as the capture time increases. These are good reasons to want instead to capture several smaller sub-scenes that can be joined to make the whole scene. Achieving this has traditionally been difficult: joining sub-scenes that may never have been viewed from the same angle requires a high-quality relocaliser that can cope with novel poses, and tracking drift in each sub-scene can prevent them from being joined to make a consistent overall scene. Recent advances in mobile hardware, however, have significantly improved our ability to capture medium-sized sub-scenes with little to no tracking drift. Moreover, high-quality regression forest-based relocalisers have recently been made more practical by the introduction of a method to allow them to be trained and used online. In this paper, we leverage these advances to present what to our knowledge is the first system to allow multiple users to collaborate interactively to reconstruct dense, voxel-based models of whole buildings. Using our system, an entire house or lab can be captured and reconstructed in under half an hour using only consumer-grade hardware.
InfiniTAM v3: A Framework for Large-Scale 3D Reconstruction with Loop Closure
Aug 02, 2017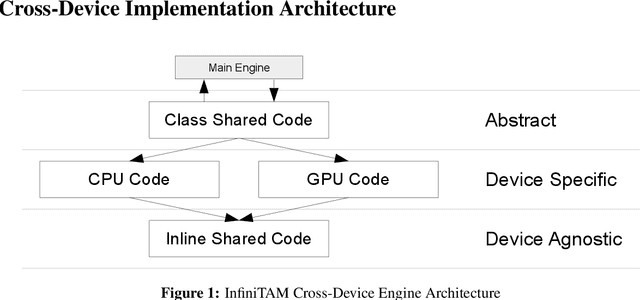
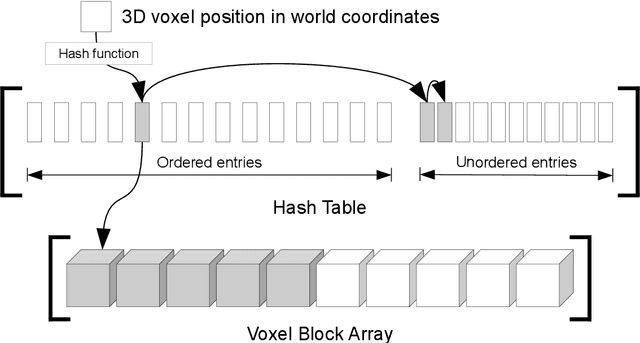
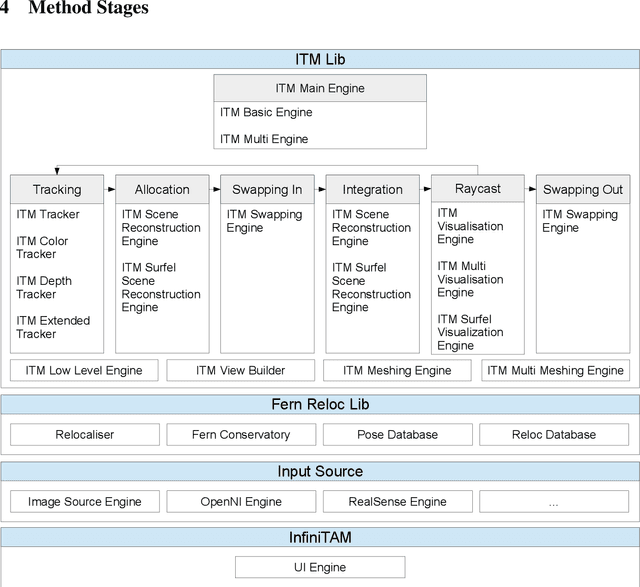
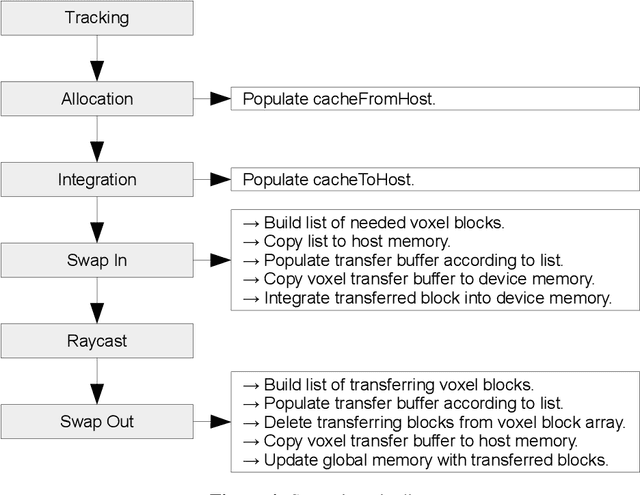
Volumetric models have become a popular representation for 3D scenes in recent years. One breakthrough leading to their popularity was KinectFusion, which focuses on 3D reconstruction using RGB-D sensors. However, monocular SLAM has since also been tackled with very similar approaches. Representing the reconstruction volumetrically as a TSDF leads to most of the simplicity and efficiency that can be achieved with GPU implementations of these systems. However, this representation is memory-intensive and limits applicability to small-scale reconstructions. Several avenues have been explored to overcome this. With the aim of summarizing them and providing for a fast, flexible 3D reconstruction pipeline, we propose a new, unifying framework called InfiniTAM. The idea is that steps like camera tracking, scene representation and integration of new data can easily be replaced and adapted to the user's needs. This report describes the technical implementation details of InfiniTAM v3, the third version of our InfiniTAM system. We have added various new features, as well as making numerous enhancements to the low-level code that significantly improve our camera tracking performance. The new features that we expect to be of most interest are (i) a robust camera tracking module; (ii) an implementation of Glocker et al.'s keyframe-based random ferns camera relocaliser; (iii) a novel approach to globally-consistent TSDF-based reconstruction, based on dividing the scene into rigid submaps and optimising the relative poses between them; and (iv) an implementation of Keller et al.'s surfel-based reconstruction approach.